 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpaceVLLM: Endowing Multimodal Large Language Model with Spatio-Temporal Video Grounding Capability
Mar 18, 2025

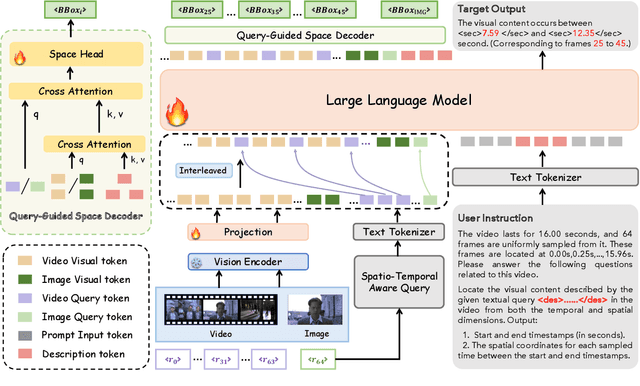
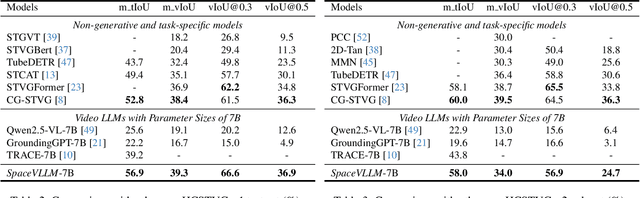
Multimodal large language models (MLLMs) have made remarkable progress in either temporal or spatial localization. However, they struggle to perform spatio-temporal video grounding. This limitation stems from two major challenges. Firstly, it is difficult to extract accurate spatio-temporal information of each frame in the video. Secondly, the substantial number of visual tokens makes it challenging to precisely map visual tokens of each frame to their corresponding spatial coordinates. To address these issues, we introduce SpaceVLLM, a MLLM endowed with spatio-temporal video grounding capability. Specifically, we adopt a set of interleaved Spatio-Temporal Aware Queries to capture temporal perception and dynamic spatial information. Moreover, we propose a Query-Guided Space Decoder to establish a corresponding connection between the queries and spatial coordinates. Additionally, due to the lack of spatio-temporal datasets, we construct the Unified Spatio-Temporal Grounding (Uni-STG) dataset, comprising 480K instances across three tasks. This dataset fully exploits the potential of MLLM to simultaneously facilitate localization in both temporal and spatial dimensions. Extensive experiments demonstrate that SpaceVLLM achieves the state-of-the-art performance across 11 benchmarks covering temporal, spatial, spatio-temporal and video understanding tasks, highlighting the effectiveness of our approach. Our code, datasets and model will be released.
AlignZeg: Mitigating Objective Misalignment for Zero-shot Semantic Segmentation
Apr 08, 2024A serious issue that harms the performance of zero-shot visual recognition is named objective misalignment, i.e., the learning objective prioritizes improving the recognition accuracy of seen classes rather than unseen classes, while the latter is the true target to pursue. This issue becomes more significant in zero-shot image segmentation because the stronger (i.e., pixel-level) supervision brings a larger gap between seen and unseen classes. To mitigate it, we propose a novel architecture named AlignZeg, which embodies a comprehensive improvement of the segmentation pipeline, including proposal extraction, classification, and correction, to better fit the goal of zero-shot segmentation. (1) Mutually-Refined Proposal Extraction. AlignZeg harnesses a mutual interaction between mask queries and visual features, facilitating detailed class-agnostic mask proposal extraction. (2) Generalization-Enhanced Proposal Classification. AlignZeg introduces synthetic data and incorporates multiple background prototypes to allocate a more generalizable feature space. (3) Predictive Bias Correction. During the inference stage, AlignZeg uses a class indicator to find potential unseen class proposals followed by a prediction postprocess to correct the prediction bias. Experiments demonstrate that AlignZeg markedly enhances zero-shot semantic segmentation, as shown by an average 3.8% increase in hIoU, primarily attributed to a 7.1% improvement in identifying unseen classes, and we further validate that the improvement comes from alleviating the objective misalignment issue.
Towards Balanced Alignment: Modal-Enhanced Semantic Modeling for Video Moment Retrieval
Dec 19, 2023



Video Moment Retrieval (VMR) aims to retrieve temporal segments in untrimmed videos corresponding to a given language query by constructing cross-modal alignment strategies. However, these existing strategies are often sub-optimal since they ignore the modality imbalance problem, \textit{i.e.}, the semantic richness inherent in videos far exceeds that of a given limited-length sentence. Therefore, in pursuit of better alignment, a natural idea is enhancing the video modality to filter out query-irrelevant semantics, and enhancing the text modality to capture more segment-relevant knowledge. In this paper, we introduce Modal-Enhanced Semantic Modeling (MESM), a novel framework for more balanced alignment through enhancing features at two levels. First, we enhance the video modality at the frame-word level through word reconstruction. This strategy emphasizes the portions associated with query words in frame-level features while suppressing irrelevant parts. Therefore, the enhanced video contains less redundant semantics and is more balanced with the textual modality. Second, we enhance the textual modality at the segment-sentence level by learning complementary knowledge from context sentences and ground-truth segments. With the knowledge added to the query, the textual modality thus maintains more meaningful semantics and is more balanced with the video modality. By implementing two levels of MESM, the semantic information from both modalities is more balanced to align, thereby bridging the modality gap. Experiments on three widely used benchmarks, including the out-of-distribution settings, show that the proposed framework achieves a new start-of-the-art performance with notable generalization ability (e.g., 4.42% and 7.69% average gains of R1@0.7 on Charades-STA and Charades-CG). The code will be available at https://github.com/lntzm/MESM.
Dual-Stream Knowledge-Preserving Hashing for Unsupervised Video Retrieval
Oct 12, 2023Unsupervised video hashing usually optimizes binary codes by learning to reconstruct input videos. Such reconstruction constraint spends much effort on frame-level temporal context changes without focusing on video-level global semantics that are more useful for retrieval. Hence, we address this problem by decomposing video information into reconstruction-dependent and semantic-dependent information, which disentangles the semantic extraction from reconstruction constraint. Specifically, we first design a simple dual-stream structure, including a temporal layer and a hash layer. Then, with the help of semantic similarity knowledge obtained from self-supervision, the hash layer learns to capture information for semantic retrieval, while the temporal layer learns to capture the information for reconstruction. In this way, the model naturally preserves the disentangled semantics into binary codes. Validated by comprehensive experiments, our method consistently outperforms the state-of-the-arts on three video benchmarks.
Balanced Classification: A Unified Framework for Long-Tailed Object Detection
Aug 04, 2023Conventional detectors suffer from performance degradation when dealing with long-tailed data due to a classification bias towards the majority head categories. In this paper, we contend that the learning bias originates from two factors: 1) the unequal competition arising from the imbalanced distribution of foreground categories, and 2) the lack of sample diversity in tail categories. To tackle these issues, we introduce a unified framework called BAlanced CLassification (BACL), which enables adaptive rectification of inequalities caused by disparities in category distribution and dynamic intensification of sample diversities in a synchronized manner. Specifically, a novel foreground classification balance loss (FCBL) is developed to ameliorate the domination of head categories and shift attention to difficult-to-differentiate categories by introducing pairwise class-aware margins and auto-adjusted weight terms, respectively. This loss prevents the over-suppression of tail categories in the context of unequal competition. Moreover, we propose a dynamic feature hallucination module (FHM), which enhances the representation of tail categories in the feature space by synthesizing hallucinated samples to introduce additional data variances. In this divide-and-conquer approach, BACL sets a new state-of-the-art on the challenging LVIS benchmark with a decoupled training pipeline, surpassing vanilla Faster R-CNN with ResNet-50-FPN by 5.8% AP and 16.1% AP for overall and tail categories. Extensive experiments demonstrate that BACL consistently achieves performance improvements across various datasets with different backbones and architectures. Code and models are available at https://github.com/Tianhao-Qi/BACL.