 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpaceVLLM: Endowing Multimodal Large Language Model with Spatio-Temporal Video Grounding Capability
Paper and Code
Mar 18, 2025

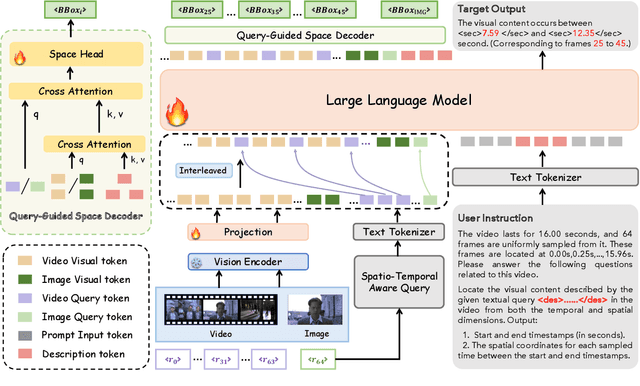
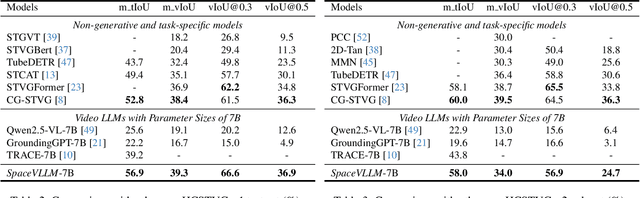
Multimodal large language models (MLLMs) have made remarkable progress in either temporal or spatial localization. However, they struggle to perform spatio-temporal video grounding. This limitation stems from two major challenges. Firstly, it is difficult to extract accurate spatio-temporal information of each frame in the video. Secondly, the substantial number of visual tokens makes it challenging to precisely map visual tokens of each frame to their corresponding spatial coordinates. To address these issues, we introduce SpaceVLLM, a MLLM endowed with spatio-temporal video grounding capability. Specifically, we adopt a set of interleaved Spatio-Temporal Aware Queries to capture temporal perception and dynamic spatial information. Moreover, we propose a Query-Guided Space Decoder to establish a corresponding connection between the queries and spatial coordinates. Additionally, due to the lack of spatio-temporal datasets, we construct the Unified Spatio-Temporal Grounding (Uni-STG) dataset, comprising 480K instances across three tasks. This dataset fully exploits the potential of MLLM to simultaneously facilitate localization in both temporal and spatial dimensions. Extensive experiments demonstrate that SpaceVLLM achieves the state-of-the-art performance across 11 benchmarks covering temporal, spatial, spatio-temporal and video understanding tasks, highlighting the effectiveness of our approach. Our code, datasets and model will be released.