 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTstars-Tryon 1.0: Robust and Realistic Virtual Try-On for Diverse Fashion Items
Apr 22, 2026Recent advances in image generation and editing have opened new opportunities for virtual try-on. However, existing methods still struggle to meet complex real-world demands. We present Tstars-Tryon 1.0, a commercial-scale virtual try-on system that is robust, realistic, versatile, and highly efficient. First, our system maintains a high success rate across challenging cases like extreme poses, severe illumination variations, motion blur, and other in-the-wild conditions. Second, it delivers highly photorealistic results with fine-grained details, faithfully preserving garment texture, material properties, and structural characteristics, while largely avoiding common AI-generated artifacts. Third, beyond apparel try-on, our model supports flexible multi-image composition (up to 6 reference images) across 8 fashion categories, with coordinated control over person identity and background. Fourth, to overcome the latency bottlenecks of commercial deployment, our system is heavily optimized for inference speed, delivering near real-time generation for a seamless user experience. These capabilities are enabled by an integrated system design spanning end-to-end model architecture, a scalable data engine, robust infrastructure, and a multi-stage training paradigm. Extensive evaluation and large-scale product deployment demonstrate that Tstars-Tryon1.0 achieves leading overall performance. To support future research, we also release a comprehensive benchmark. The model has been deployed at an industrial scale on the Taobao App, serving millions of users with tens of millions of requests.
How Control Information Influences Multilingual Text Image Generation and Editing?
Jul 16, 2024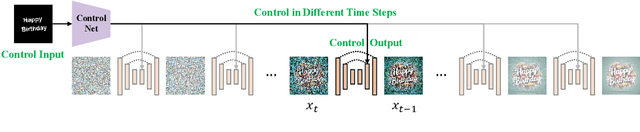

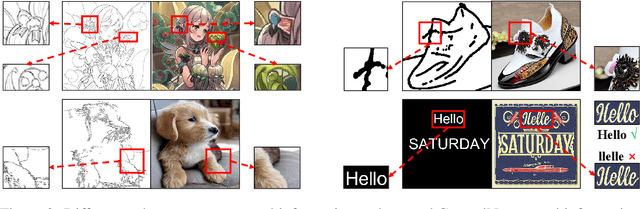

Visual text generation has significantly advanced through diffusion models aimed at producing images with readable and realistic text. Recent works primarily use a ControlNet-based framework, employing standard font text images to control diffusion models. Recognizing the critical role of control information in generating high-quality text, we investigate its influence from three perspectives: input encoding, role at different stages, and output features. Our findings reveal that: 1) Input control information has unique characteristics compared to conventional inputs like Canny edges and depth maps. 2) Control information plays distinct roles at different stages of the denoising process. 3) Output control features significantly differ from the base and skip features of the U-Net decoder in the frequency domain. Based on these insights, we propose TextGen, a novel framework designed to enhance generation quality by optimizing control information. We improve input and output features using Fourier analysis to emphasize relevant information and reduce noise. Additionally, we employ a two-stage generation framework to align the different roles of control information at different stages. Furthermore, we introduce an effective and lightweight dataset for training. Our method achieves state-of-the-art performance in both Chinese and English text generation. The code and dataset will be made available.
Self-Supervised Pre-training with Symmetric Superimposition Modeling for Scene Text Recognition
May 11, 2024



In text recognition, self-supervised pre-training emerges as a good solution to reduce dependence on expansive annotated real data. Previous studies primarily focus on local visual representation by leveraging mask image modeling or sequence contrastive learning. However, they omit modeling the linguistic information in text images, which is crucial for recognizing text. To simultaneously capture local character features and linguistic information in visual space, we propose Symmetric Superimposition Modeling (SSM). The objective of SSM is to reconstruct the direction-specific pixel and feature signals from the symmetrically superimposed input. Specifically, we add the original image with its inverted views to create the symmetrically superimposed inputs. At the pixel level, we reconstruct the original and inverted images to capture character shapes and texture-level linguistic context. At the feature level, we reconstruct the feature of the same original image and inverted image with different augmentations to model the semantic-level linguistic context and the local character discrimination. In our design, we disrupt the character shape and linguistic rules. Consequently, the dual-level reconstruction facilitates understanding character shapes and linguistic information from the perspective of visual texture and feature semantics. Experiments on various text recognition benchmarks demonstrate the effectiveness and generality of SSM, with 4.1% average performance gains and 86.6% new state-of-the-art average word accuracy on Union14M benchmarks. The code is available at https://github.com/FaltingsA/SSM.
Choose What You Need: Disentangled Representation Learning for Scene Text Recognition, Removal and Editing
May 07, 2024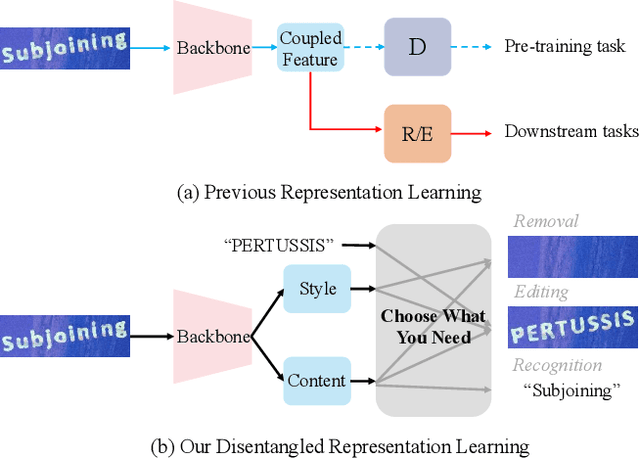
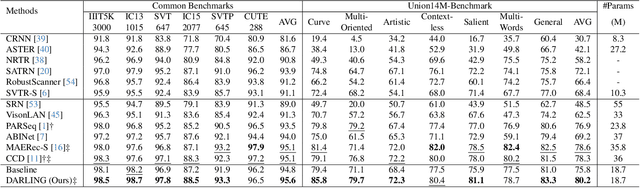
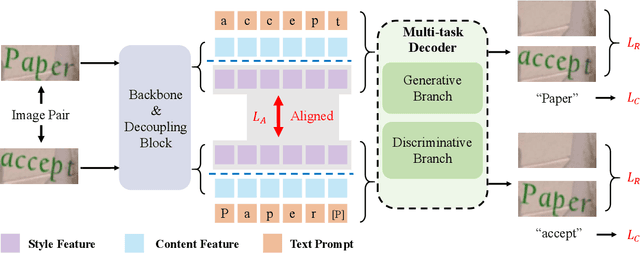

Scene text images contain not only style information (font, background) but also content information (character, texture). Different scene text tasks need different information, but previous representation learning methods use tightly coupled features for all tasks, resulting in sub-optimal performance. We propose a Disentangled Representation Learning framework (DARLING) aimed at disentangling these two types of features for improved adaptability in better addressing various downstream tasks (choose what you really need). Specifically, we synthesize a dataset of image pairs with identical style but different content. Based on the dataset, we decouple the two types of features by the supervision design. Clearly, we directly split the visual representation into style and content features, the content features are supervised by a text recognition loss, while an alignment loss aligns the style features in the image pairs. Then, style features are employed in reconstructing the counterpart image via an image decoder with a prompt that indicates the counterpart's content. Such an operation effectively decouples the features based on their distinctive properties. To the best of our knowledge, this is the first time in the field of scene text that disentangles the inherent properties of the text images. Our method achieves state-of-the-art performance in Scene Text Recognition, Removal, and Editing.