 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing is Improving: Visual Feedback for Iterative Text Layout Refinement
Mar 23, 2026Recent advances in Multimodal Large Language Models (MLLMs) have enabled automated generation of structured layouts from natural language descriptions. Existing methods typically follow a code-only paradigm that generates code to represent layouts, which are then rendered by graphic engines to produce final images. However, they are blind to the rendered visual outcome, making it difficult to guarantee readability and aesthetics. In this paper, we identify visual feedback as a critical factor in layout generation and propose Visual Feedback Layout Model (VFLM), a self-improving framework that leverages visual feedback iterative refinement. VFLM is capable of performing adaptive reflective generation, which leverages visual information to reflect on previous issues and iteratively generates outputs until satisfactory quality is achieved. It is achieved through reinforcement learning with a visually grounded reward model that incorporates OCR accuracy. By rewarding only the final generated outcome, we can effectively stimulate the model's iterative and reflective generative capabilities. Experiments across multiple benchmarks show that VFLM consistently outperforms advanced MLLMs, existing layout models, and code-only baselines, establishing visual feedback as critical for design-oriented MLLMs. Our code and data are available at https://github.com/FolSpark/VFLM.
Boosting Semi-Supervised Scene Text Recognition via Viewing and Summarizing
Nov 23, 2024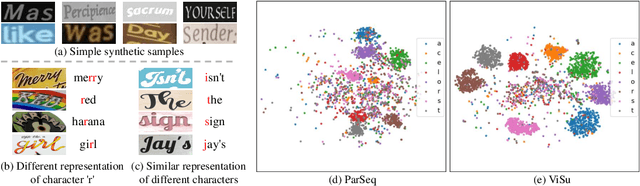
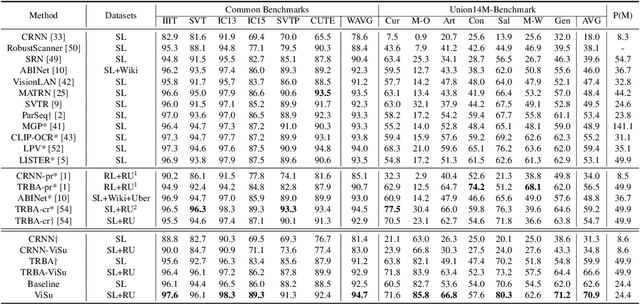


Existing scene text recognition (STR) methods struggle to recognize challenging texts, especially for artistic and severely distorted characters. The limitation lies in the insufficient exploration of character morphologies, including the monotonousness of widely used synthetic training data and the sensitivity of the model to character morphologies. To address these issues, inspired by the human learning process of viewing and summarizing, we facilitate the contrastive learning-based STR framework in a self-motivated manner by leveraging synthetic and real unlabeled data without any human cost. In the viewing process, to compensate for the simplicity of synthetic data and enrich character morphology diversity, we propose an Online Generation Strategy to generate background-free samples with diverse character styles. By excluding background noise distractions, the model is encouraged to focus on character morphology and generalize the ability to recognize complex samples when trained with only simple synthetic data. To boost the summarizing process, we theoretically demonstrate the derivation error in the previous character contrastive loss, which mistakenly causes the sparsity in the intra-class distribution and exacerbates ambiguity on challenging samples. Therefore, a new Character Unidirectional Alignment Loss is proposed to correct this error and unify the representation of the same characters in all samples by aligning the character features in the student model with the reference features in the teacher model. Extensive experiment results show that our method achieves SOTA performance (94.7\% and 70.9\% average accuracy on common benchmarks and Union14M-Benchmark). Code will be available at https://github.com/qqqyd/ViSu.
How Control Information Influences Multilingual Text Image Generation and Editing?
Jul 16, 2024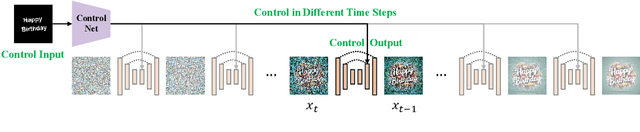

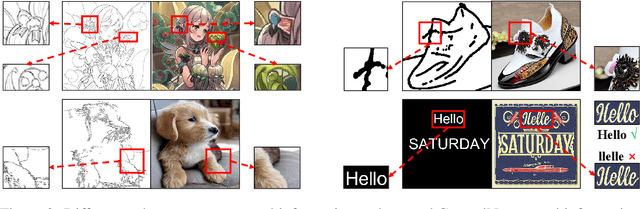

Visual text generation has significantly advanced through diffusion models aimed at producing images with readable and realistic text. Recent works primarily use a ControlNet-based framework, employing standard font text images to control diffusion models. Recognizing the critical role of control information in generating high-quality text, we investigate its influence from three perspectives: input encoding, role at different stages, and output features. Our findings reveal that: 1) Input control information has unique characteristics compared to conventional inputs like Canny edges and depth maps. 2) Control information plays distinct roles at different stages of the denoising process. 3) Output control features significantly differ from the base and skip features of the U-Net decoder in the frequency domain. Based on these insights, we propose TextGen, a novel framework designed to enhance generation quality by optimizing control information. We improve input and output features using Fourier analysis to emphasize relevant information and reduce noise. Additionally, we employ a two-stage generation framework to align the different roles of control information at different stages. Furthermore, we introduce an effective and lightweight dataset for training. Our method achieves state-of-the-art performance in both Chinese and English text generation. The code and dataset will be made available.
Focus on the Whole Character: Discriminative Character Modeling for Scene Text Recognition
Jul 08, 2024Recently, scene text recognition (STR) models have shown significant performance improvements. However, existing models still encounter difficulties in recognizing challenging texts that involve factors such as severely distorted and perspective characters. These challenging texts mainly cause two problems: (1) Large Intra-Class Variance. (2) Small Inter-Class Variance. An extremely distorted character may prominently differ visually from other characters within the same category, while the variance between characters from different classes is relatively small. To address the above issues, we propose a novel method that enriches the character features to enhance the discriminability of characters. Firstly, we propose the Character-Aware Constraint Encoder (CACE) with multiple blocks stacked. CACE introduces a decay matrix in each block to explicitly guide the attention region for each token. By continuously employing the decay matrix, CACE enables tokens to perceive morphological information at the character level. Secondly, an Intra-Inter Consistency Loss (I^2CL) is introduced to consider intra-class compactness and inter-class separability at feature space. I^2CL improves the discriminative capability of features by learning a long-term memory unit for each character category. Trained with synthetic data, our model achieves state-of-the-art performance on common benchmarks (94.1% accuracy) and Union14M-Benchmark (61.6% accuracy). Code is available at https://github.com/bang123-box/CFE.
Self-Supervised Pre-training with Symmetric Superimposition Modeling for Scene Text Recognition
May 11, 2024



In text recognition, self-supervised pre-training emerges as a good solution to reduce dependence on expansive annotated real data. Previous studies primarily focus on local visual representation by leveraging mask image modeling or sequence contrastive learning. However, they omit modeling the linguistic information in text images, which is crucial for recognizing text. To simultaneously capture local character features and linguistic information in visual space, we propose Symmetric Superimposition Modeling (SSM). The objective of SSM is to reconstruct the direction-specific pixel and feature signals from the symmetrically superimposed input. Specifically, we add the original image with its inverted views to create the symmetrically superimposed inputs. At the pixel level, we reconstruct the original and inverted images to capture character shapes and texture-level linguistic context. At the feature level, we reconstruct the feature of the same original image and inverted image with different augmentations to model the semantic-level linguistic context and the local character discrimination. In our design, we disrupt the character shape and linguistic rules. Consequently, the dual-level reconstruction facilitates understanding character shapes and linguistic information from the perspective of visual texture and feature semantics. Experiments on various text recognition benchmarks demonstrate the effectiveness and generality of SSM, with 4.1% average performance gains and 86.6% new state-of-the-art average word accuracy on Union14M benchmarks. The code is available at https://github.com/FaltingsA/SSM.
Exploring Stroke-Level Modifications for Scene Text Editing
Dec 05, 2022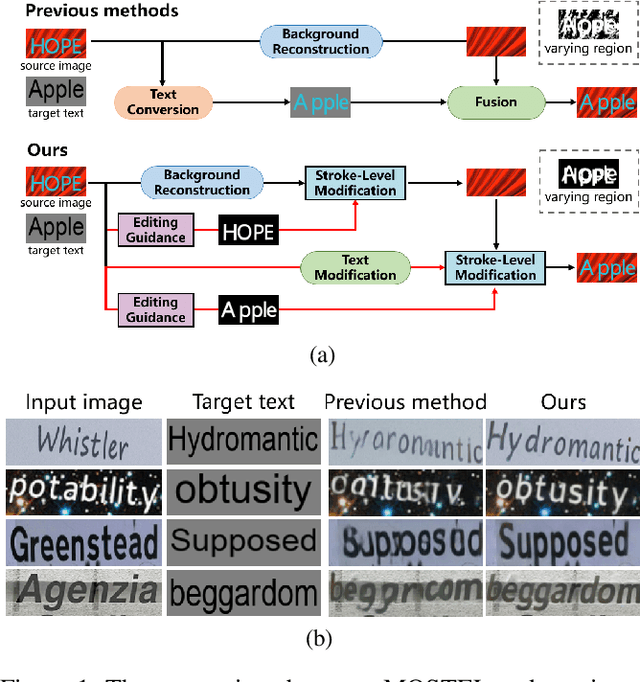
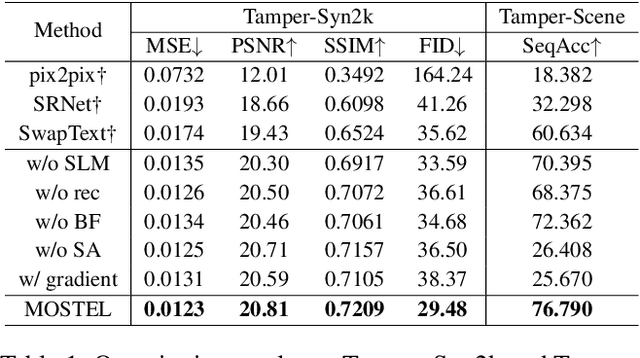
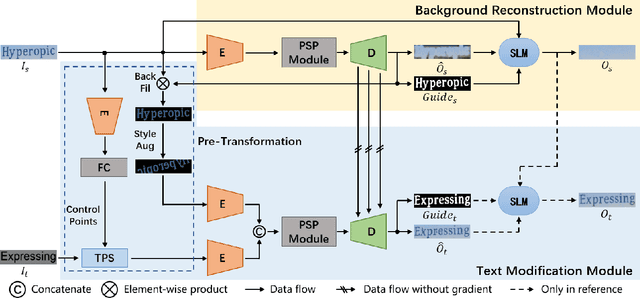
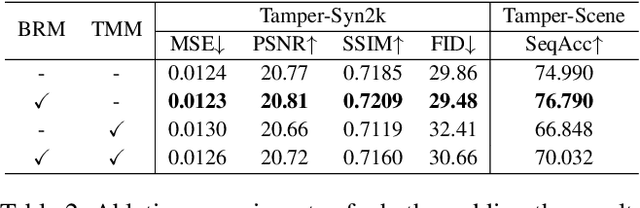
Scene text editing (STE) aims to replace text with the desired one while preserving background and styles of the original text. However, due to the complicated background textures and various text styles, existing methods fall short in generating clear and legible edited text images. In this study, we attribute the poor editing performance to two problems: 1) Implicit decoupling structure. Previous methods of editing the whole image have to learn different translation rules of background and text regions simultaneously. 2) Domain gap. Due to the lack of edited real scene text images, the network can only be well trained on synthetic pairs and performs poorly on real-world images. To handle the above problems, we propose a novel network by MOdifying Scene Text image at strokE Level (MOSTEL). Firstly, we generate stroke guidance maps to explicitly indicate regions to be edited. Different from the implicit one by directly modifying all the pixels at image level, such explicit instructions filter out the distractions from background and guide the network to focus on editing rules of text regions. Secondly, we propose a Semi-supervised Hybrid Learning to train the network with both labeled synthetic images and unpaired real scene text images. Thus, the STE model is adapted to real-world datasets distributions. Moreover, two new datasets (Tamper-Syn2k and Tamper-Scene) are proposed to fill the blank of public evaluation datasets. Extensive experiments demonstrate that our MOSTEL outperforms previous methods both qualitatively and quantitatively. Datasets and code will be available at https://github.com/qqqyd/MOSTEL.
A Simple and Strong Baseline: Progressively Region-based Scene Text Removal Networks
Jun 24, 2021
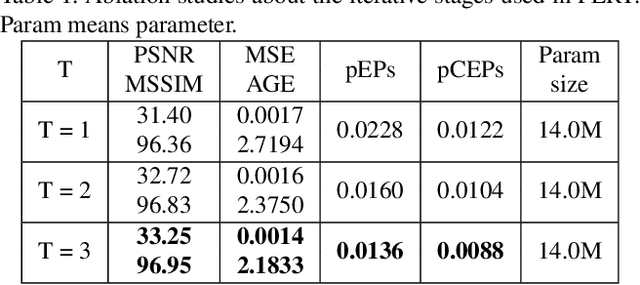
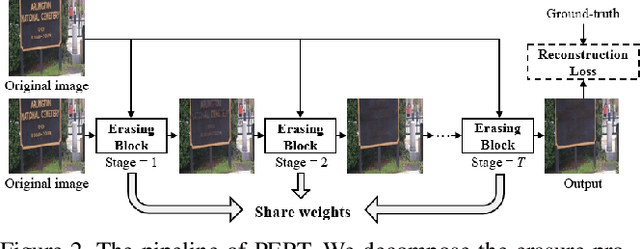
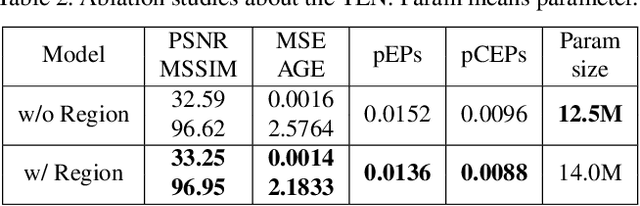
Existing scene text removal methods mainly train an elaborate network with paired images to realize the function of text localization and background reconstruction simultaneously, but there exists two problems: 1) lacking the exhaustive erasure of text region and 2) causing the excessive erasure to text-free areas. To handle these issues, this paper provides a novel ProgrEssively Region-based scene Text eraser (PERT), which introduces region-based modification strategy to progressively erase the pixels in only text region. Firstly, PERT decomposes the STR task to several erasing stages. As each stage aims to take a further step toward the text-removed image rather than directly regress to the final result, the decomposed operation reduces the learning difficulty in each stage, and an exhaustive erasure result can be obtained by iterating over lightweight erasing blocks with shared parameters. Then, PERT introduces a region-based modification strategy to ensure the integrity of text-free areas by decoupling text localization from erasure process to guide the removal. Benefiting from the simplicity architecture, PERT is a simple and strong baseline, and is easy to be followed and developed. Extensive experiments demonstrate that PERT obtains the state-of-the-art results on both synthetic and real-world datasets. Code is available athttps://github.com/wangyuxin87/PERT.