 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Semi-Supervised Scene Text Recognition via Viewing and Summarizing
Paper and Code
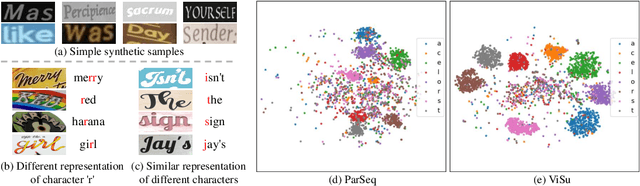
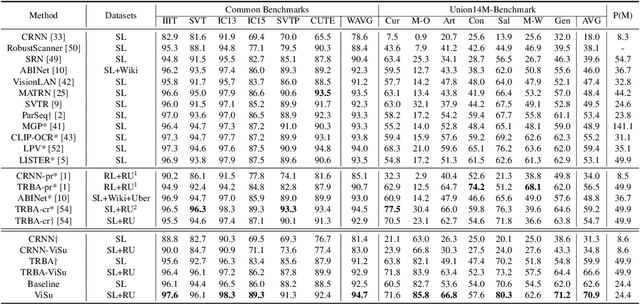


Existing scene text recognition (STR) methods struggle to recognize challenging texts, especially for artistic and severely distorted characters. The limitation lies in the insufficient exploration of character morphologies, including the monotonousness of widely used synthetic training data and the sensitivity of the model to character morphologies. To address these issues, inspired by the human learning process of viewing and summarizing, we facilitate the contrastive learning-based STR framework in a self-motivated manner by leveraging synthetic and real unlabeled data without any human cost. In the viewing process, to compensate for the simplicity of synthetic data and enrich character morphology diversity, we propose an Online Generation Strategy to generate background-free samples with diverse character styles. By excluding background noise distractions, the model is encouraged to focus on character morphology and generalize the ability to recognize complex samples when trained with only simple synthetic data. To boost the summarizing process, we theoretically demonstrate the derivation error in the previous character contrastive loss, which mistakenly causes the sparsity in the intra-class distribution and exacerbates ambiguity on challenging samples. Therefore, a new Character Unidirectional Alignment Loss is proposed to correct this error and unify the representation of the same characters in all samples by aligning the character features in the student model with the reference features in the teacher model. Extensive experiment results show that our method achieves SOTA performance (94.7\% and 70.9\% average accuracy on common benchmarks and Union14M-Benchmark). Code will be available at https://github.com/qqqyd/ViSu.