 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Stroke-Level Modifications for Scene Text Editing
Paper and Code
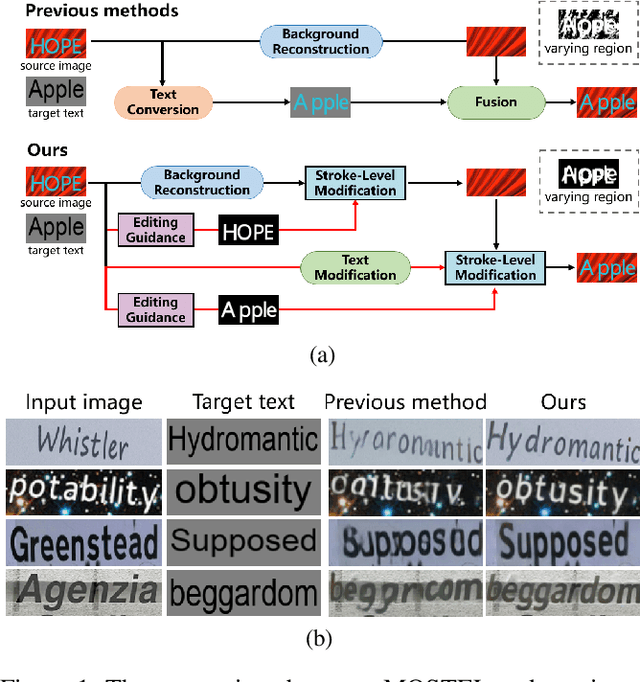
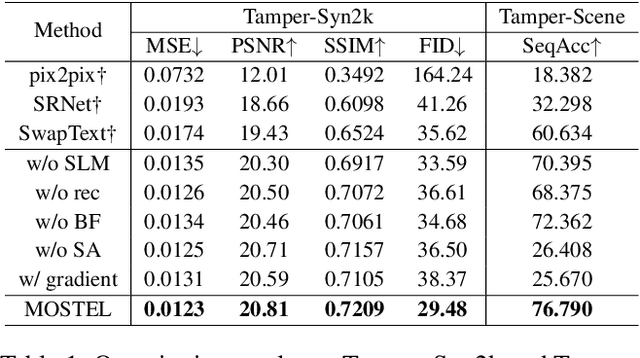
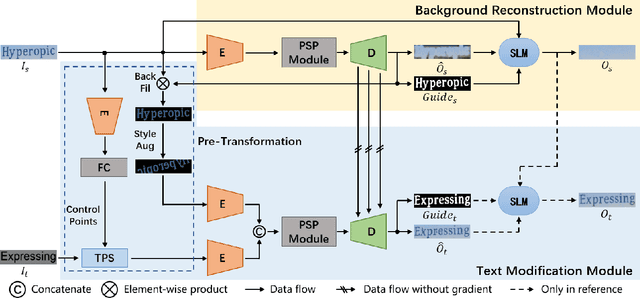
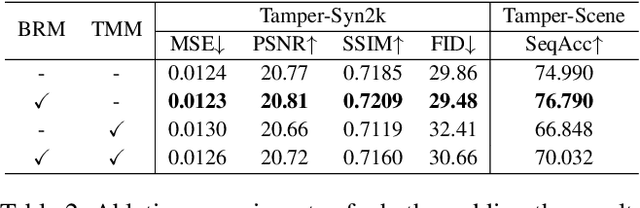
Scene text editing (STE) aims to replace text with the desired one while preserving background and styles of the original text. However, due to the complicated background textures and various text styles, existing methods fall short in generating clear and legible edited text images. In this study, we attribute the poor editing performance to two problems: 1) Implicit decoupling structure. Previous methods of editing the whole image have to learn different translation rules of background and text regions simultaneously. 2) Domain gap. Due to the lack of edited real scene text images, the network can only be well trained on synthetic pairs and performs poorly on real-world images. To handle the above problems, we propose a novel network by MOdifying Scene Text image at strokE Level (MOSTEL). Firstly, we generate stroke guidance maps to explicitly indicate regions to be edited. Different from the implicit one by directly modifying all the pixels at image level, such explicit instructions filter out the distractions from background and guide the network to focus on editing rules of text regions. Secondly, we propose a Semi-supervised Hybrid Learning to train the network with both labeled synthetic images and unpaired real scene text images. Thus, the STE model is adapted to real-world datasets distributions. Moreover, two new datasets (Tamper-Syn2k and Tamper-Scene) are proposed to fill the blank of public evaluation datasets. Extensive experiments demonstrate that our MOSTEL outperforms previous methods both qualitatively and quantitatively. Datasets and code will be available at https://github.com/qqqyd/MOSTEL.