 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhispEar: A Bi-directional Framework for Scaling Whispered Speech Conversion via Pseudo-Parallel Whisper Generation
Mar 09, 2026Whispered speech lacks vocal fold vibration and fundamental frequency, resulting in degraded acoustic cues and making whisper-to-normal (W2N) conversion challenging, especially with limited parallel data. We propose WhispEar, a bidirectional framework based on unified semantic representations that capture speaking-mode-invariant information shared by whispered and normal speech. The framework contains both W2N and normal-to-whisper (N2W) models. Notably, the N2W model enables zero-shot pseudo-parallel whisper generation from abundant normal speech, allowing scalable data augmentation for W2N training. Increasing generated data consistently improves performance. We also release the largest bilingual (Chinese-English) whispered-normal parallel corpus to date. Experiments demonstrate that WhispEar outperforms strong baselines and benefits significantly from scalable pseudo-parallel data.
SingNet: Towards a Large-Scale, Diverse, and In-the-Wild Singing Voice Dataset
May 14, 2025The lack of a publicly-available large-scale and diverse dataset has long been a significant bottleneck for singing voice applications like Singing Voice Synthesis (SVS) and Singing Voice Conversion (SVC). To tackle this problem, we present SingNet, an extensive, diverse, and in-the-wild singing voice dataset. Specifically, we propose a data processing pipeline to extract ready-to-use training data from sample packs and songs on the internet, forming 3000 hours of singing voices in various languages and styles. Furthermore, to facilitate the use and demonstrate the effectiveness of SingNet, we pre-train and open-source various state-of-the-art (SOTA) models on Wav2vec2, BigVGAN, and NSF-HiFiGAN based on our collected singing voice data. We also conduct benchmark experiments on Automatic Lyric Transcription (ALT), Neural Vocoder, and Singing Voice Conversion (SVC). Audio demos are available at: https://singnet-dataset.github.io/.
AnyEnhance: A Unified Generative Model with Prompt-Guidance and Self-Critic for Voice Enhancement
Jan 26, 2025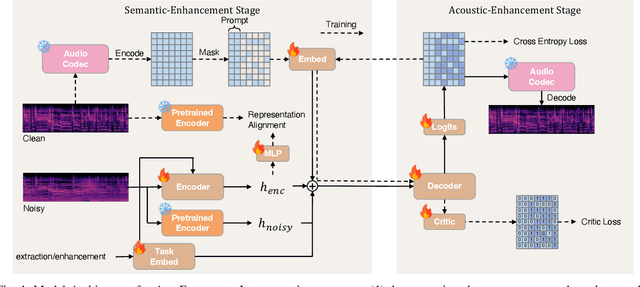
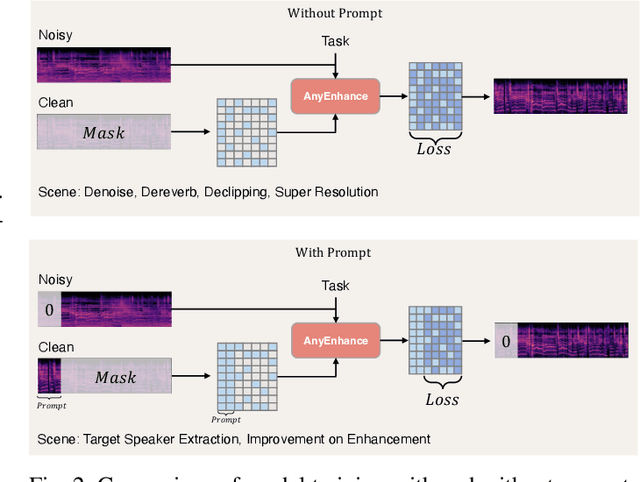
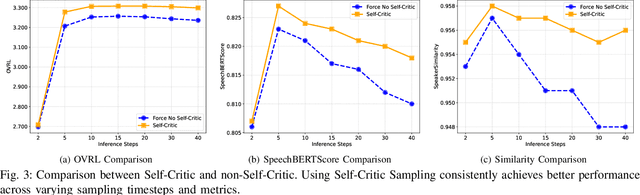

We introduce AnyEnhance, a unified generative model for voice enhancement that processes both speech and singing voices. Based on a masked generative model, AnyEnhance is capable of handling both speech and singing voices, supporting a wide range of enhancement tasks including denoising, dereverberation, declipping, super-resolution, and target speaker extraction, all simultaneously and without fine-tuning. AnyEnhance introduces a prompt-guidance mechanism for in-context learning, which allows the model to natively accept a reference speaker's timbre. In this way, it could boost enhancement performance when a reference audio is available and enable the target speaker extraction task without altering the underlying architecture. Moreover, we also introduce a self-critic mechanism into the generative process for masked generative models, yielding higher-quality outputs through iterative self-assessment and refinement. Extensive experiments on various enhancement tasks demonstrate AnyEnhance outperforms existing methods in terms of both objective metrics and subjective listening tests. Demo audios are publicly available at https://amphionspace.github.io/anyenhance/.
Amphion: An Open-Source Audio, Music and Speech Generation Toolkit
Dec 15, 2023

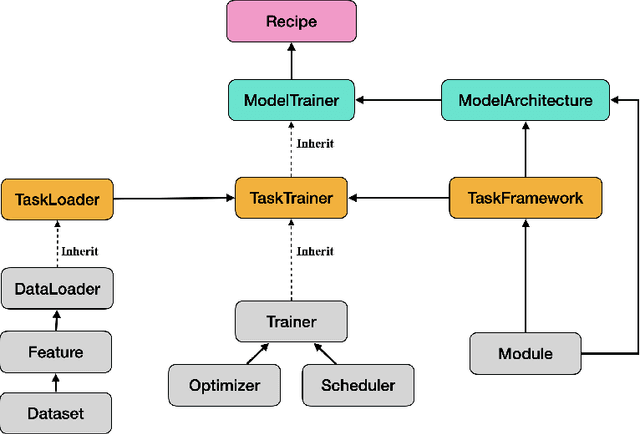

Amphion is a toolkit for Audio, Music, and Speech Generation. Its purpose is to support reproducible research and help junior researchers and engineers get started in the field of audio, music, and speech generation research and development. Amphion offers a unique feature: visualizations of classic models or architectures. We believe that these visualizations are beneficial for junior researchers and engineers who wish to gain a better understanding of the model. The North-Star objective of Amphion is to offer a platform for studying the conversion of any inputs into general audio. Amphion is designed to support individual generation tasks. In addition to the specific generation tasks, Amphion also includes several vocoders and evaluation metrics. A vocoder is an important module for producing high-quality audio signals, while evaluation metrics are critical for ensuring consistent metrics in generation tasks. In this paper, we provide a high-level overview of Amphion.
Leveraging Content-based Features from Multiple Acoustic Models for Singing Voice Conversion
Oct 17, 2023



Singing voice conversion (SVC) is a technique to enable an arbitrary singer to sing an arbitrary song. To achieve that, it is important to obtain speaker-agnostic representations from source audio, which is a challenging task. A common solution is to extract content-based features (e.g., PPGs) from a pretrained acoustic model. However, the choices for acoustic models are vast and varied. It is yet to be explored what characteristics of content features from different acoustic models are, and whether integrating multiple content features can help each other. Motivated by that, this study investigates three distinct content features, sourcing from WeNet, Whisper, and ContentVec, respectively. We explore their complementary roles in intelligibility, prosody, and conversion similarity for SVC. By integrating the multiple content features with a diffusion-based SVC model, our SVC system achieves superior conversion performance on both objective and subjective evaluation in comparison to a single source of content features. Our demo page and code can be available https://www.zhangxueyao.com/data/MultipleContentsSVC/index.html.