 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOver-the-Air Adversarial Attack Detection: from Datasets to Defenses
Sep 11, 2025



Automatic Speaker Verification (ASV) systems can be used for voice-enabled applications for identity verification. However, recent studies have exposed these systems' vulnerabilities to both over-the-line (OTL) and over-the-air (OTA) adversarial attacks. Although various detection methods have been proposed to counter these threats, they have not been thoroughly tested due to the lack of a comprehensive data set. To address this gap, we developed the AdvSV 2.0 dataset, which contains 628k samples with a total duration of 800 hours. This dataset incorporates classical adversarial attack algorithms, ASV systems, and encompasses both OTL and OTA scenarios. Furthermore, we introduce a novel adversarial attack method based on a Neural Replay Simulator (NRS), which enhances the potency of adversarial OTA attacks, thereby presenting a greater threat to ASV systems. To defend against these attacks, we propose CODA-OCC, a contrastive learning approach within the one-class classification framework. Experimental results show that CODA-OCC achieves an EER of 11.2% and an AUC of 0.95 on the AdvSV 2.0 dataset, outperforming several state-of-the-art detection methods.
SingNet: Towards a Large-Scale, Diverse, and In-the-Wild Singing Voice Dataset
May 14, 2025The lack of a publicly-available large-scale and diverse dataset has long been a significant bottleneck for singing voice applications like Singing Voice Synthesis (SVS) and Singing Voice Conversion (SVC). To tackle this problem, we present SingNet, an extensive, diverse, and in-the-wild singing voice dataset. Specifically, we propose a data processing pipeline to extract ready-to-use training data from sample packs and songs on the internet, forming 3000 hours of singing voices in various languages and styles. Furthermore, to facilitate the use and demonstrate the effectiveness of SingNet, we pre-train and open-source various state-of-the-art (SOTA) models on Wav2vec2, BigVGAN, and NSF-HiFiGAN based on our collected singing voice data. We also conduct benchmark experiments on Automatic Lyric Transcription (ALT), Neural Vocoder, and Singing Voice Conversion (SVC). Audio demos are available at: https://singnet-dataset.github.io/.
Emilia: A Large-Scale, Extensive, Multilingual, and Diverse Dataset for Speech Generation
Jan 27, 2025Recent advancements in speech generation have been driven by the large-scale training datasets. However, current models fall short of capturing the spontaneity and variability inherent in real-world human speech, due to their reliance on audiobook datasets limited to formal read-aloud speech styles. To bridge this gap, we introduce Emilia-Pipe, an open-source preprocessing pipeline to extract high-quality training data from valuable yet underexplored in-the-wild data that capture spontaneous human speech in real-world contexts. By leveraging Emilia-Pipe, we construct Emilia, the first multilingual speech generation dataset derived from in-the-wild speech data. This dataset comprises over 101k hours of speech across six languages: English, Chinese, German, French, Japanese, and Korean. Besides, we expand Emilia to Emilia-Large, a dataset exceeding 216k hours, making it the largest open-source speech generation dataset available. Extensive experiments demonstrate that Emilia significantly outperforms traditional audiobook datasets in generating spontaneous and human-like speech, showcasing superior performance in capturing diverse speaker timbre and speaking styles of real-world human speech. Furthermore, this work underscores the importance of scaling dataset size to advance speech generation research and validates the effectiveness of Emilia for both multilingual and crosslingual speech generation.
Overview of the Amphion Toolkit (v0.2)
Jan 26, 2025



Amphion is an open-source toolkit for Audio, Music, and Speech Generation, designed to lower the entry barrier for junior researchers and engineers in these fields. It provides a versatile framework that supports a variety of generation tasks and models. In this report, we introduce Amphion v0.2, the second major release developed in 2024. This release features a 100K-hour open-source multilingual dataset, a robust data preparation pipeline, and novel models for tasks such as text-to-speech, audio coding, and voice conversion. Furthermore, the report includes multiple tutorials that guide users through the functionalities and usage of the newly released models.
Noro: A Noise-Robust One-shot Voice Conversion System with Hidden Speaker Representation Capabilities
Nov 29, 2024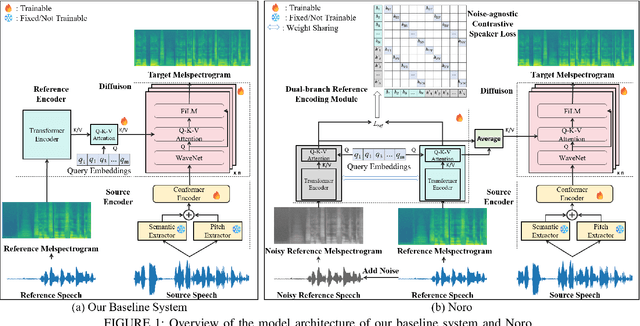
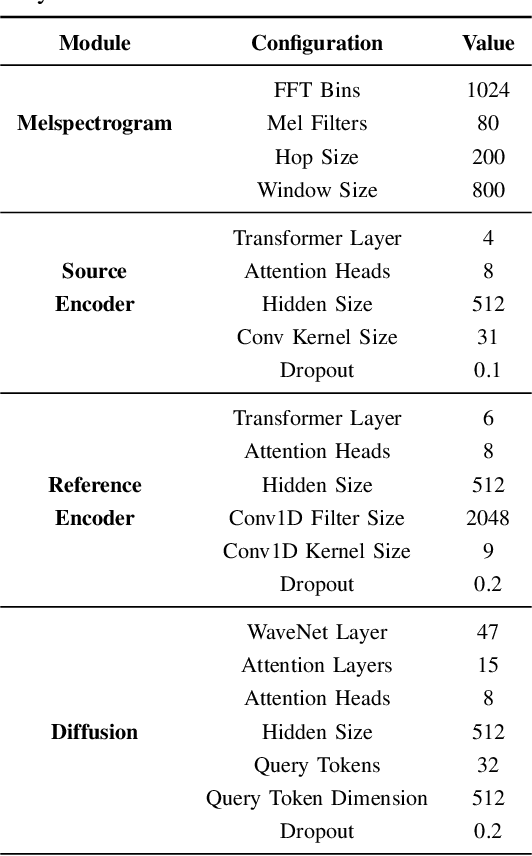
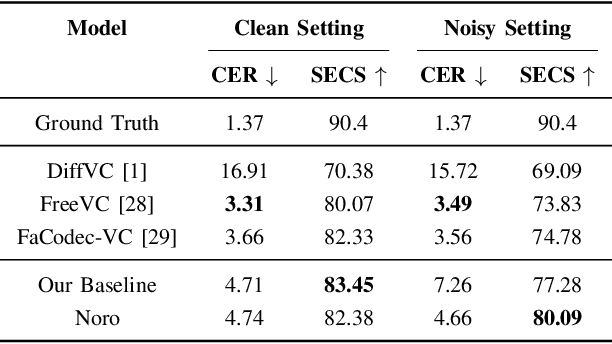

One-shot voice conversion (VC) aims to alter the timbre of speech from a source speaker to match that of a target speaker using just a single reference speech from the target, while preserving the semantic content of the original source speech. Despite advancements in one-shot VC, its effectiveness decreases in real-world scenarios where reference speeches, often sourced from the internet, contain various disturbances like background noise. To address this issue, we introduce Noro, a Noise Robust One-shot VC system. Noro features innovative components tailored for VC using noisy reference speeches, including a dual-branch reference encoding module and a noise-agnostic contrastive speaker loss. Experimental results demonstrate that Noro outperforms our baseline system in both clean and noisy scenarios, highlighting its efficacy for real-world applications. Additionally, we investigate the hidden speaker representation capabilities of our baseline system by repurposing its reference encoder as a speaker encoder. The results shows that it is competitive with several advanced self-supervised learning models for speaker representation under the SUPERB settings, highlighting the potential for advancing speaker representation learning through one-shot VC task.
Debatts: Zero-Shot Debating Text-to-Speech Synthesis
Nov 10, 2024



In debating, rebuttal is one of the most critical stages, where a speaker addresses the arguments presented by the opposing side. During this process, the speaker synthesizes their own persuasive articulation given the context from the opposing side. This work proposes a novel zero-shot text-to-speech synthesis system for rebuttal, namely Debatts. Debatts takes two speech prompts, one from the opposing side (i.e. opponent) and one from the speaker. The prompt from the opponent is supposed to provide debating style prosody, and the prompt from the speaker provides identity information. In particular, we pretrain the Debatts system from in-the-wild dataset, and integrate an additional reference encoder to take debating prompt for style. In addition, we also create a debating dataset to develop Debatts. In this setting, Debatts can generate a debating-style speech in rebuttal for any voices. Experimental results confirm the effectiveness of the proposed system in comparison with the classic zero-shot TTS systems.
SpMis: An Investigation of Synthetic Spoken Misinformation Detection
Sep 17, 2024



In recent years, speech generation technology has advanced rapidly, fueled by generative models and large-scale training techniques. While these developments have enabled the production of high-quality synthetic speech, they have also raised concerns about the misuse of this technology, particularly for generating synthetic misinformation. Current research primarily focuses on distinguishing machine-generated speech from human-produced speech, but the more urgent challenge is detecting misinformation within spoken content. This task requires a thorough analysis of factors such as speaker identity, topic, and synthesis. To address this need, we conduct an initial investigation into synthetic spoken misinformation detection by introducing an open-source dataset, SpMis. SpMis includes speech synthesized from over 1,000 speakers across five common topics, utilizing state-of-the-art text-to-speech systems. Although our results show promising detection capabilities, they also reveal substantial challenges for practical implementation, underscoring the importance of ongoing research in this critical area.
Emilia: An Extensive, Multilingual, and Diverse Speech Dataset for Large-Scale Speech Generation
Jul 07, 2024



Recently, speech generation models have made significant progress by using large-scale training data. However, the research community struggle to produce highly spontaneous and human-like speech due to the lack of large-scale, diverse, and spontaneous speech data. This paper presents \textit{Emilia}, the first multilingual speech generation dataset from in-the-wild speech data, and Emilia-Pipe, the first open-source preprocessing pipeline designed to transform in-the-wild speech data into high-quality training data with annotations for speech generation. Emilia starts with over 101k hours of speech in six languages and features diverse speech with varied speaking styles. To facilitate the scale-up of Emilia, the open-source pipeline Emilia-Pipe can process one hour of raw speech data ready for model training in a few mins, which enables the research community to collaborate on large-scale speech generation research. Experimental results validate the effectiveness of Emilia. Demos are available at: https://emilia-dataset.github.io/Emilia-Demo-Page/.
MCFEND: A Multi-source Benchmark Dataset for Chinese Fake News Detection
Mar 14, 2024
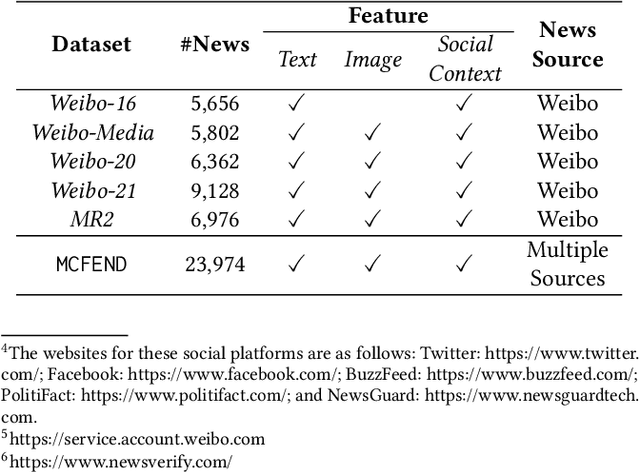
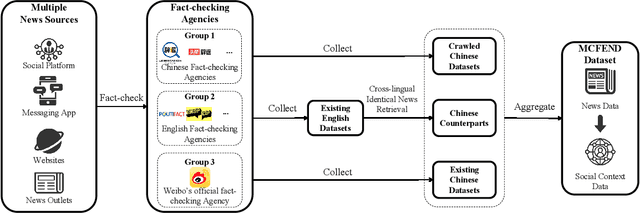
The prevalence of fake news across various online sources has had a significant influence on the public. Existing Chinese fake news detection datasets are limited to news sourced solely from Weibo. However, fake news originating from multiple sources exhibits diversity in various aspects, including its content and social context. Methods trained on purely one single news source can hardly be applicable to real-world scenarios. Our pilot experiment demonstrates that the F1 score of the state-of-the-art method that learns from a large Chinese fake news detection dataset, Weibo-21, drops significantly from 0.943 to 0.470 when the test data is changed to multi-source news data, failing to identify more than one-third of the multi-source fake news. To address this limitation, we constructed the first multi-source benchmark dataset for Chinese fake news detection, termed MCFEND, which is composed of news we collected from diverse sources such as social platforms, messaging apps, and traditional online news outlets. Notably, such news has been fact-checked by 14 authoritative fact-checking agencies worldwide. In addition, various existing Chinese fake news detection methods are thoroughly evaluated on our proposed dataset in cross-source, multi-source, and unseen source ways. MCFEND, as a benchmark dataset, aims to advance Chinese fake news detection approaches in real-world scenarios.
Audio compression-assisted feature extraction for voice replay attack detection
Oct 10, 2023



Replay attack is one of the most effective and simplest voice spoofing attacks. Detecting replay attacks is challenging, according to the Automatic Speaker Verification Spoofing and Countermeasures Challenge 2021 (ASVspoof 2021), because they involve a loudspeaker, a microphone, and acoustic conditions (e.g., background noise). One obstacle to detecting replay attacks is finding robust feature representations that reflect the channel noise information added to the replayed speech. This study proposes a feature extraction approach that uses audio compression for assistance. Audio compression compresses audio to preserve content and speaker information for transmission. The missed information after decompression is expected to contain content- and speaker-independent information (e.g., channel noise added during the replay process). We conducted a comprehensive experiment with a few data augmentation techniques and 3 classifiers on the ASVspoof 2021 physical access (PA) set and confirmed the effectiveness of the proposed feature extraction approach. To the best of our knowledge, the proposed approach achieves the lowest EER at 22.71% on the ASVspoof 2021 PA evaluation set.