 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Benchmark: LLMs Evaluation with an Anthropomorphic and Value-oriented Roadmap
Aug 26, 2025For Large Language Models (LLMs), a disconnect persists between benchmark performance and real-world utility. Current evaluation frameworks remain fragmented, prioritizing technical metrics while neglecting holistic assessment for deployment. This survey introduces an anthropomorphic evaluation paradigm through the lens of human intelligence, proposing a novel three-dimensional taxonomy: Intelligence Quotient (IQ)-General Intelligence for foundational capacity, Emotional Quotient (EQ)-Alignment Ability for value-based interactions, and Professional Quotient (PQ)-Professional Expertise for specialized proficiency. For practical value, we pioneer a Value-oriented Evaluation (VQ) framework assessing economic viability, social impact, ethical alignment, and environmental sustainability. Our modular architecture integrates six components with an implementation roadmap. Through analysis of 200+ benchmarks, we identify key challenges including dynamic assessment needs and interpretability gaps. It provides actionable guidance for developing LLMs that are technically proficient, contextually relevant, and ethically sound. We maintain a curated repository of open-source evaluation resources at: https://github.com/onejune2018/Awesome-LLM-Eval.
Siamese Foundation Models for Crystal Structure Prediction
Mar 13, 2025



Crystal Structure Prediction (CSP), which aims to generate stable crystal structures from compositions, represents a critical pathway for discovering novel materials. While structure prediction tasks in other domains, such as proteins, have seen remarkable progress, CSP remains a relatively underexplored area due to the more complex geometries inherent in crystal structures. In this paper, we propose Siamese foundation models specifically designed to address CSP. Our pretrain-finetune framework, named DAO, comprises two complementary foundation models: DAO-G for structure generation and DAO-P for energy prediction. Experiments on CSP benchmarks (MP-20 and MPTS-52) demonstrate that our DAO-G significantly surpasses state-of-the-art (SOTA) methods across all metrics. Extensive ablation studies further confirm that DAO-G excels in generating diverse polymorphic structures, and the dataset relaxation and energy guidance provided by DAO-P are essential for enhancing DAO-G's performance. When applied to three real-world superconductors ($\text{CsV}_3\text{Sb}_5$, $ \text{Zr}_{16}\text{Rh}_8\text{O}_4$ and $\text{Zr}_{16}\text{Pd}_8\text{O}_4$) that are known to be challenging to analyze, our foundation models achieve accurate critical temperature predictions and structure generations. For instance, on $\text{CsV}_3\text{Sb}_5$, DAO-G generates a structure close to the experimental one with an RMSE of 0.0085; DAO-P predicts the $T_c$ value with high accuracy (2.26 K vs. the ground-truth value of 2.30 K). In contrast, conventional DFT calculators like Quantum Espresso only successfully derive the structure of the first superconductor within an acceptable time, while the RMSE is nearly 8 times larger, and the computation speed is more than 1000 times slower. These compelling results collectively highlight the potential of our approach for advancing materials science research and development.
Emilia: A Large-Scale, Extensive, Multilingual, and Diverse Dataset for Speech Generation
Jan 27, 2025Recent advancements in speech generation have been driven by the large-scale training datasets. However, current models fall short of capturing the spontaneity and variability inherent in real-world human speech, due to their reliance on audiobook datasets limited to formal read-aloud speech styles. To bridge this gap, we introduce Emilia-Pipe, an open-source preprocessing pipeline to extract high-quality training data from valuable yet underexplored in-the-wild data that capture spontaneous human speech in real-world contexts. By leveraging Emilia-Pipe, we construct Emilia, the first multilingual speech generation dataset derived from in-the-wild speech data. This dataset comprises over 101k hours of speech across six languages: English, Chinese, German, French, Japanese, and Korean. Besides, we expand Emilia to Emilia-Large, a dataset exceeding 216k hours, making it the largest open-source speech generation dataset available. Extensive experiments demonstrate that Emilia significantly outperforms traditional audiobook datasets in generating spontaneous and human-like speech, showcasing superior performance in capturing diverse speaker timbre and speaking styles of real-world human speech. Furthermore, this work underscores the importance of scaling dataset size to advance speech generation research and validates the effectiveness of Emilia for both multilingual and crosslingual speech generation.
GDiffRetro: Retrosynthesis Prediction with Dual Graph Enhanced Molecular Representation and Diffusion Generation
Jan 14, 2025



Retrosynthesis prediction focuses on identifying reactants capable of synthesizing a target product. Typically, the retrosynthesis prediction involves two phases: Reaction Center Identification and Reactant Generation. However, we argue that most existing methods suffer from two limitations in the two phases: (i) Existing models do not adequately capture the ``face'' information in molecular graphs for the reaction center identification. (ii) Current approaches for the reactant generation predominantly use sequence generation in a 2D space, which lacks versatility in generating reasonable distributions for completed reactive groups and overlooks molecules' inherent 3D properties. To overcome the above limitations, we propose GDiffRetro. For the reaction center identification, GDiffRetro uniquely integrates the original graph with its corresponding dual graph to represent molecular structures, which helps guide the model to focus more on the faces in the graph. For the reactant generation, GDiffRetro employs a conditional diffusion model in 3D to further transform the obtained synthon into a complete reactant. Our experimental findings reveal that GDiffRetro outperforms state-of-the-art semi-template models across various evaluative metrics.
MaskGCT: Zero-Shot Text-to-Speech with Masked Generative Codec Transformer
Sep 01, 2024Nowadays, large-scale text-to-speech (TTS) systems are primarily divided into two types: autoregressive and non-autoregressive. The autoregressive systems have certain deficiencies in robustness and cannot control speech duration. In contrast, non-autoregressive systems require explicit prediction of phone-level duration, which may compromise their naturalness. We introduce the Masked Generative Codec Transformer (MaskGCT), a fully non-autoregressive model for TTS that does not require precise alignment information between text and speech. MaskGCT is a two-stage model: in the first stage, the model uses text to predict semantic tokens extracted from a speech self-supervised learning (SSL) model, and in the second stage, the model predicts acoustic tokens conditioned on these semantic tokens. MaskGCT follows the \textit{mask-and-predict} learning paradigm. During training, MaskGCT learns to predict masked semantic or acoustic tokens based on given conditions and prompts. During inference, the model generates tokens of a specified length in a parallel manner. We scale MaskGCT to a large-scale multilingual dataset with 100K hours of in-the-wild speech. Our experiments demonstrate that MaskGCT achieves superior or competitive performance compared to state-of-the-art zero-shot TTS systems in terms of quality, similarity, and intelligibility while offering higher generation efficiency than diffusion-based or autoregressive TTS models. Audio samples are available at https://maskgct.github.io.
Token-Mol 1.0: Tokenized drug design with large language model
Jul 10, 2024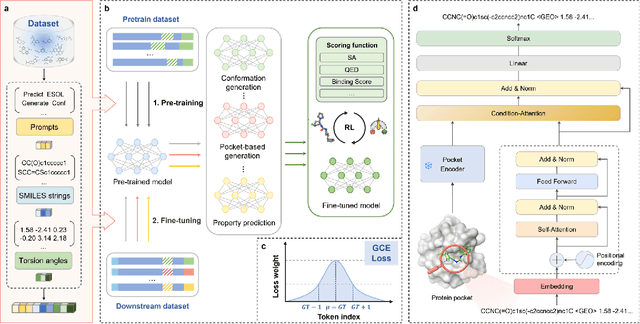

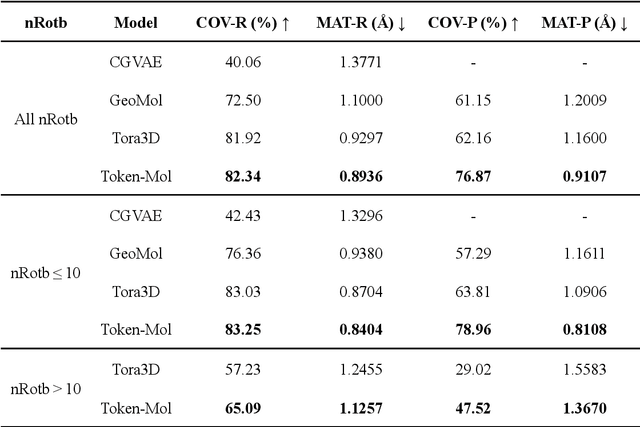
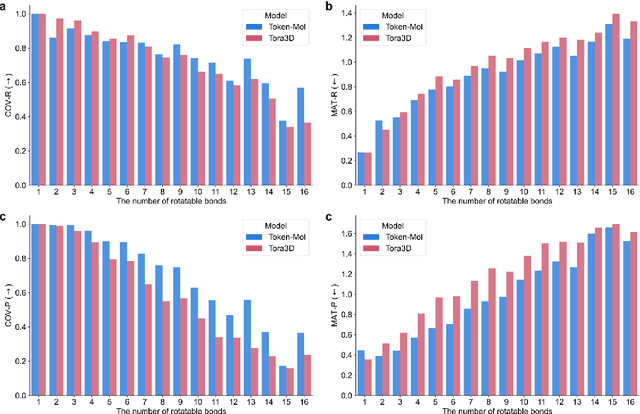
Significant interests have recently risen in leveraging sequence-based large language models (LLMs) for drug design. However, most current applications of LLMs in drug discovery lack the ability to comprehend three-dimensional (3D) structures, thereby limiting their effectiveness in tasks that explicitly involve molecular conformations. In this study, we introduced Token-Mol, a token-only 3D drug design model. This model encodes all molecular information, including 2D and 3D structures, as well as molecular property data, into tokens, which transforms classification and regression tasks in drug discovery into probabilistic prediction problems, thereby enabling learning through a unified paradigm. Token-Mol is built on the transformer decoder architecture and trained using random causal masking techniques. Additionally, we proposed the Gaussian cross-entropy (GCE) loss function to overcome the challenges in regression tasks, significantly enhancing the capacity of LLMs to learn continuous numerical values. Through a combination of fine-tuning and reinforcement learning (RL), Token-Mol achieves performance comparable to or surpassing existing task-specific methods across various downstream tasks, including pocket-based molecular generation, conformation generation, and molecular property prediction. Compared to existing molecular pre-trained models, Token-Mol exhibits superior proficiency in handling a wider range of downstream tasks essential for drug design. Notably, our approach improves regression task accuracy by approximately 30% compared to similar token-only methods. Token-Mol overcomes the precision limitations of token-only models and has the potential to integrate seamlessly with general models such as ChatGPT, paving the way for the development of a universal artificial intelligence drug design model that facilitates rapid and high-quality drug design by experts.
Emilia: An Extensive, Multilingual, and Diverse Speech Dataset for Large-Scale Speech Generation
Jul 07, 2024



Recently, speech generation models have made significant progress by using large-scale training data. However, the research community struggle to produce highly spontaneous and human-like speech due to the lack of large-scale, diverse, and spontaneous speech data. This paper presents \textit{Emilia}, the first multilingual speech generation dataset from in-the-wild speech data, and Emilia-Pipe, the first open-source preprocessing pipeline designed to transform in-the-wild speech data into high-quality training data with annotations for speech generation. Emilia starts with over 101k hours of speech in six languages and features diverse speech with varied speaking styles. To facilitate the scale-up of Emilia, the open-source pipeline Emilia-Pipe can process one hour of raw speech data ready for model training in a few mins, which enables the research community to collaborate on large-scale speech generation research. Experimental results validate the effectiveness of Emilia. Demos are available at: https://emilia-dataset.github.io/Emilia-Demo-Page/.