 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePEMNet: Towards Autonomous and Enhanced Environment-Aware Mobile Networks
Jan 16, 2026With 5G deployment and the evolution toward 6G, mobile networks must make decisions in highly dynamic environments under strict latency, energy, and spectrum constraints. Achieving this goal, however, depends on prior knowledge of spatial-temporal variations in wireless channels and traffic demands. This motivates a joint, site-specific representation of radio propagation and user demand that is queryable at low online overhead. In this work, we propose the perception embedding map (PEM), a localized framework that embeds fine-grained channel statistics together with grid-level spatial-temporal traffic patterns over a base station's coverage. PEM is built from standard-compliant measurements -- such as measurement report and scheduling/quality-of-service logs -- so it can be deployed and maintained at scale with low cost. Integrated into PEM, this joint knowledge supports enhanced environment-aware optimization across PHY, MAC, and network layers while substantially reducing training overhead and signaling. Compared with existing site-specific channel maps and digital-twin replicas, PEM distinctively emphasizes (i) joint channel-traffic embedding, which is essential for network optimization, and (ii) practical construction using standard measurements, enabling network autonomy while striking a favorable fidelity-cost balance.
Small Symbols, Big Risks: Exploring Emoticon Semantic Confusion in Large Language Models
Jan 12, 2026Emoticons are widely used in digital communication to convey affective intent, yet their safety implications for Large Language Models (LLMs) remain largely unexplored. In this paper, we identify emoticon semantic confusion, a vulnerability where LLMs misinterpret ASCII-based emoticons to perform unintended and even destructive actions. To systematically study this phenomenon, we develop an automated data generation pipeline and construct a dataset containing 3,757 code-oriented test cases spanning 21 meta-scenarios, four programming languages, and varying contextual complexities. Our study on six LLMs reveals that emoticon semantic confusion is pervasive, with an average confusion ratio exceeding 38%. More critically, over 90% of confused responses yield 'silent failures', which are syntactically valid outputs but deviate from user intent, potentially leading to destructive security consequences. Furthermore, we observe that this vulnerability readily transfers to popular agent frameworks, while existing prompt-based mitigations remain largely ineffective. We call on the community to recognize this emerging vulnerability and develop effective mitigation methods to uphold the safety and reliability of the LLM system.
Pay Less Attention to Function Words for Free Robustness of Vision-Language Models
Dec 09, 2025To address the trade-off between robustness and performance for robust VLM, we observe that function words could incur vulnerability of VLMs against cross-modal adversarial attacks, and propose Function-word De-Attention (FDA) accordingly to mitigate the impact of function words. Similar to differential amplifiers, our FDA calculates the original and the function-word cross-attention within attention heads, and differentially subtracts the latter from the former for more aligned and robust VLMs. Comprehensive experiments include 2 SOTA baselines under 6 different attacks on 2 downstream tasks, 3 datasets, and 3 models. Overall, our FDA yields an average 18/13/53% ASR drop with only 0.2/0.3/0.6% performance drops on the 3 tested models on retrieval, and a 90% ASR drop with a 0.3% performance gain on visual grounding. We demonstrate the scalability, generalization, and zero-shot performance of FDA experimentally, as well as in-depth ablation studies and analysis. Code will be made publicly at https://github.com/michaeltian108/FDA.
T2I-Based Physical-World Appearance Attack against Traffic Sign Recognition Systems in Autonomous Driving
Nov 17, 2025Traffic Sign Recognition (TSR) systems play a critical role in Autonomous Driving (AD) systems, enabling real-time detection of road signs, such as STOP and speed limit signs. While these systems are increasingly integrated into commercial vehicles, recent research has exposed their vulnerability to physical-world adversarial appearance attacks. In such attacks, carefully crafted visual patterns are misinterpreted by TSR models as legitimate traffic signs, while remaining inconspicuous or benign to human observers. However, existing adversarial appearance attacks suffer from notable limitations. Pixel-level perturbation-based methods often lack stealthiness and tend to overfit to specific surrogate models, resulting in poor transferability to real-world TSR systems. On the other hand, text-to-image (T2I) diffusion model-based approaches demonstrate limited effectiveness and poor generalization to out-of-distribution sign types. In this paper, we present DiffSign, a novel T2I-based appearance attack framework designed to generate physically robust, highly effective, transferable, practical, and stealthy appearance attacks against TSR systems. To overcome the limitations of prior approaches, we propose a carefully designed attack pipeline that integrates CLIP-based loss and masked prompts to improve attack focus and controllability. We also propose two novel style customization methods to guide visual appearance and improve out-of-domain traffic sign attack generalization and attack stealthiness. We conduct extensive evaluations of DiffSign under varied real-world conditions, including different distances, angles, light conditions, and sign categories. Our method achieves an average physical-world attack success rate of 83.3%, leveraging DiffSign's high effectiveness in attack transferability.
Multi-modal Deepfake Detection and Localization with FPN-Transformer
Nov 11, 2025The rapid advancement of generative adversarial networks (GANs) and diffusion models has enabled the creation of highly realistic deepfake content, posing significant threats to digital trust across audio-visual domains. While unimodal detection methods have shown progress in identifying synthetic media, their inability to leverage cross-modal correlations and precisely localize forged segments limits their practicality against sophisticated, fine-grained manipulations. To address this, we introduce a multi-modal deepfake detection and localization framework based on a Feature Pyramid-Transformer (FPN-Transformer), addressing critical gaps in cross-modal generalization and temporal boundary regression. The proposed approach utilizes pre-trained self-supervised models (WavLM for audio, CLIP for video) to extract hierarchical temporal features. A multi-scale feature pyramid is constructed through R-TLM blocks with localized attention mechanisms, enabling joint analysis of cross-context temporal dependencies. The dual-branch prediction head simultaneously predicts forgery probabilities and refines temporal offsets of manipulated segments, achieving frame-level localization precision. We evaluate our approach on the test set of the IJCAI'25 DDL-AV benchmark, showing a good performance with a final score of 0.7535 for cross-modal deepfake detection and localization in challenging environments. Experimental results confirm the effectiveness of our approach and provide a novel way for generalized deepfake detection. Our code is available at https://github.com/Zig-HS/MM-DDL
AutoEmpirical: LLM-Based Automated Research for Empirical Software Fault Analysis
Oct 06, 2025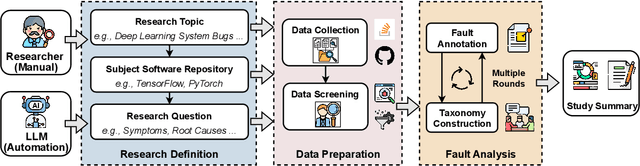

Understanding software faults is essential for empirical research in software development and maintenance. However, traditional fault analysis, while valuable, typically involves multiple expert-driven steps such as collecting potential faults, filtering, and manual investigation. These processes are both labor-intensive and time-consuming, creating bottlenecks that hinder large-scale fault studies in complex yet critical software systems and slow the pace of iterative empirical research. In this paper, we decompose the process of empirical software fault study into three key phases: (1) research objective definition, (2) data preparation, and (3) fault analysis, and we conduct an initial exploration study of applying Large Language Models (LLMs) for fault analysis of open-source software. Specifically, we perform the evaluation on 3,829 software faults drawn from a high-quality empirical study. Our results show that LLMs can substantially improve efficiency in fault analysis, with an average processing time of about two hours, compared to the weeks of manual effort typically required. We conclude by outlining a detailed research plan that highlights both the potential of LLMs for advancing empirical fault studies and the open challenges that required be addressed to achieve fully automated, end-to-end software fault analysis.
JADES: A Universal Framework for Jailbreak Assessment via Decompositional Scoring
Aug 28, 2025Accurately determining whether a jailbreak attempt has succeeded is a fundamental yet unresolved challenge. Existing evaluation methods rely on misaligned proxy indicators or naive holistic judgments. They frequently misinterpret model responses, leading to inconsistent and subjective assessments that misalign with human perception. To address this gap, we introduce JADES (Jailbreak Assessment via Decompositional Scoring), a universal jailbreak evaluation framework. Its key mechanism is to automatically decompose an input harmful question into a set of weighted sub-questions, score each sub-answer, and weight-aggregate the sub-scores into a final decision. JADES also incorporates an optional fact-checking module to strengthen the detection of hallucinations in jailbreak responses. We validate JADES on JailbreakQR, a newly introduced benchmark proposed in this work, consisting of 400 pairs of jailbreak prompts and responses, each meticulously annotated by humans. In a binary setting (success/failure), JADES achieves 98.5% agreement with human evaluators, outperforming strong baselines by over 9%. Re-evaluating five popular attacks on four LLMs reveals substantial overestimation (e.g., LAA's attack success rate on GPT-3.5-Turbo drops from 93% to 69%). Our results show that JADES could deliver accurate, consistent, and interpretable evaluations, providing a reliable basis for measuring future jailbreak attacks.
Adversarial Video Promotion Against Text-to-Video Retrieval
Aug 12, 2025Thanks to the development of cross-modal models, text-to-video retrieval (T2VR) is advancing rapidly, but its robustness remains largely unexamined. Existing attacks against T2VR are designed to push videos away from queries, i.e., suppressing the ranks of videos, while the attacks that pull videos towards selected queries, i.e., promoting the ranks of videos, remain largely unexplored. These attacks can be more impactful as attackers may gain more views/clicks for financial benefits and widespread (mis)information. To this end, we pioneer the first attack against T2VR to promote videos adversarially, dubbed the Video Promotion attack (ViPro). We further propose Modal Refinement (MoRe) to capture the finer-grained, intricate interaction between visual and textual modalities to enhance black-box transferability. Comprehensive experiments cover 2 existing baselines, 3 leading T2VR models, 3 prevailing datasets with over 10k videos, evaluated under 3 scenarios. All experiments are conducted in a multi-target setting to reflect realistic scenarios where attackers seek to promote the video regarding multiple queries simultaneously. We also evaluated our attacks for defences and imperceptibility. Overall, ViPro surpasses other baselines by over $30/10/4\%$ for white/grey/black-box settings on average. Our work highlights an overlooked vulnerability, provides a qualitative analysis on the upper/lower bound of our attacks, and offers insights into potential counterplays. Code will be publicly available at https://github.com/michaeltian108/ViPro.
D3: Training-Free AI-Generated Video Detection Using Second-Order Features
Aug 01, 2025The evolution of video generation techniques, such as Sora, has made it increasingly easy to produce high-fidelity AI-generated videos, raising public concern over the dissemination of synthetic content. However, existing detection methodologies remain limited by their insufficient exploration of temporal artifacts in synthetic videos. To bridge this gap, we establish a theoretical framework through second-order dynamical analysis under Newtonian mechanics, subsequently extending the Second-order Central Difference features tailored for temporal artifact detection. Building on this theoretical foundation, we reveal a fundamental divergence in second-order feature distributions between real and AI-generated videos. Concretely, we propose Detection by Difference of Differences (D3), a novel training-free detection method that leverages the above second-order temporal discrepancies. We validate the superiority of our D3 on 4 open-source datasets (Gen-Video, VideoPhy, EvalCrafter, VidProM), 40 subsets in total. For example, on GenVideo, D3 outperforms the previous best method by 10.39% (absolute) mean Average Precision. Additional experiments on time cost and post-processing operations demonstrate D3's exceptional computational efficiency and strong robust performance. Our code is available at https://github.com/Zig-HS/D3.
Revisiting Adversarial Patch Defenses on Object Detectors: Unified Evaluation, Large-Scale Dataset, and New Insights
Aug 01, 2025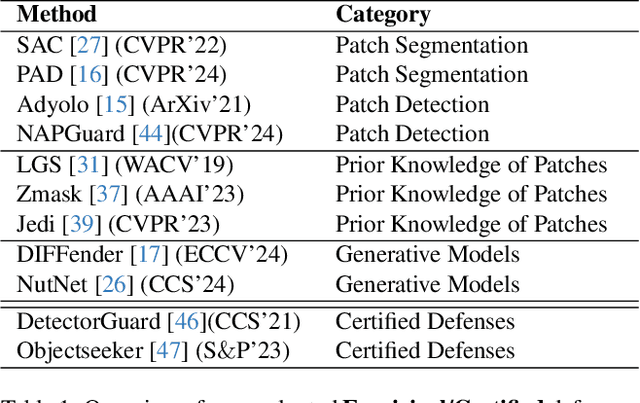

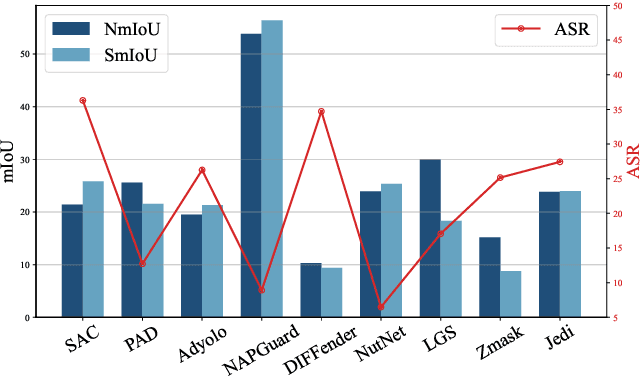
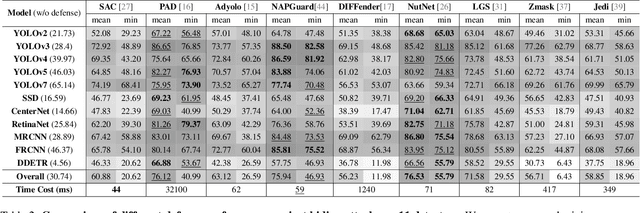
Developing reliable defenses against patch attacks on object detectors has attracted increasing interest. However, we identify that existing defense evaluations lack a unified and comprehensive framework, resulting in inconsistent and incomplete assessments of current methods. To address this issue, we revisit 11 representative defenses and present the first patch defense benchmark, involving 2 attack goals, 13 patch attacks, 11 object detectors, and 4 diverse metrics. This leads to the large-scale adversarial patch dataset with 94 types of patches and 94,000 images. Our comprehensive analyses reveal new insights: (1) The difficulty in defending against naturalistic patches lies in the data distribution, rather than the commonly believed high frequencies. Our new dataset with diverse patch distributions can be used to improve existing defenses by 15.09% AP@0.5. (2) The average precision of the attacked object, rather than the commonly pursued patch detection accuracy, shows high consistency with defense performance. (3) Adaptive attacks can substantially bypass existing defenses, and defenses with complex/stochastic models or universal patch properties are relatively robust. We hope that our analyses will serve as guidance on properly evaluating patch attacks/defenses and advancing their design. Code and dataset are available at https://github.com/Gandolfczjh/APDE, where we will keep integrating new attacks/defenses.