 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynLeaF: A Dual-Stage Multimodal Fusion Framework for Synthetic Lethality Prediction Across Pan- and Single-Cancer Contexts
Mar 23, 2026Accurate prediction of synthetic lethality (SL) is important for guiding the development of cancer drugs and therapies. SL prediction faces significant challenges in the effective fusion of heterogeneous multi-source data. Existing multimodal methods often suffer from "modality laziness" due to disparate convergence speeds, which hinders the exploitation of complementary information. This is also one reason why most existing SL prediction models cannot perform well on both pan-cancer and single-cancer SL pair prediction. In this study, we propose SynLeaF, a dual-stage multimodal fusion framework for SL prediction across pan- and single-cancer contexts. The framework employs a VAE-based cross-encoder with a product of experts mechanism to fuse four omics data types (gene expression, mutation, methylation, and CNV), while simultaneously utilizing a relational graph convolutional network to capture structured gene representations from biomedical knowledge graphs. To mitigate modality laziness, SynLeaF introduces a dual-stage training mechanism employing featurelevel knowledge distillation with adaptive uni-modal teacher and ensemble strategies. In extensive experiments across eight specific cancer types and a pancancer dataset, SynLeaF achieves superior performance in 17 out of 19 scenarios. Ablation studies and gradient analyses further validate the critical contributions of the proposed fusion and distillation mechanisms to model robustness and generalization. To facilitate community use, a web server is available at https://synleaf.bioinformatics-lilab.cn.
LLM-Guided Quantified SMT Solving over Uninterpreted Functions
Jan 08, 2026Quantified formulas with Uninterpreted Functions (UFs) over non-linear real arithmetic pose fundamental challenges for Satisfiability Modulo Theories (SMT) solving. Traditional quantifier instantiation methods struggle because they lack semantic understanding of UF constraints, forcing them to search through unbounded solution spaces with limited guidance. We present AquaForte, a framework that leverages Large Language Models to provide semantic guidance for UF instantiation by generating instantiated candidates for function definitions that satisfy the constraints, thereby significantly reducing the search space and complexity for solvers. Our approach preprocesses formulas through constraint separation, uses structured prompts to extract mathematical reasoning from LLMs, and integrates the results with traditional SMT algorithms through adaptive instantiation. AquaForte maintains soundness through systematic validation: LLM-guided instantiations yielding SAT solve the original problem, while UNSAT results generate exclusion clauses for iterative refinement. Completeness is preserved by fallback to traditional solvers augmented with learned constraints. Experimental evaluation on SMT-COMP benchmarks demonstrates that AquaForte solves numerous instances where state-of-the-art solvers like Z3 and CVC5 timeout, with particular effectiveness on satisfiable formulas. Our work shows that LLMs can provide valuable mathematical intuition for symbolic reasoning, establishing a new paradigm for SMT constraint solving.
FullPart: Generating each 3D Part at Full Resolution
Oct 30, 2025Part-based 3D generation holds great potential for various applications. Previous part generators that represent parts using implicit vector-set tokens often suffer from insufficient geometric details. Another line of work adopts an explicit voxel representation but shares a global voxel grid among all parts; this often causes small parts to occupy too few voxels, leading to degraded quality. In this paper, we propose FullPart, a novel framework that combines both implicit and explicit paradigms. It first derives the bounding box layout through an implicit box vector-set diffusion process, a task that implicit diffusion handles effectively since box tokens contain little geometric detail. Then, it generates detailed parts, each within its own fixed full-resolution voxel grid. Instead of sharing a global low-resolution space, each part in our method - even small ones - is generated at full resolution, enabling the synthesis of intricate details. We further introduce a center-point encoding strategy to address the misalignment issue when exchanging information between parts of different actual sizes, thereby maintaining global coherence. Moreover, to tackle the scarcity of reliable part data, we present PartVerse-XL, the largest human-annotated 3D part dataset to date with 40K objects and 320K parts. Extensive experiments demonstrate that FullPart achieves state-of-the-art results in 3D part generation. We will release all code, data, and model to benefit future research in 3D part generation.
From Gallery to Wrist: Realistic 3D Bracelet Insertion in Videos
Jul 27, 2025Inserting 3D objects into videos is a longstanding challenge in computer graphics with applications in augmented reality, virtual try-on, and video composition. Achieving both temporal consistency, or realistic lighting remains difficult, particularly in dynamic scenarios with complex object motion, perspective changes, and varying illumination. While 2D diffusion models have shown promise for producing photorealistic edits, they often struggle with maintaining temporal coherence across frames. Conversely, traditional 3D rendering methods excel in spatial and temporal consistency but fall short in achieving photorealistic lighting. In this work, we propose a hybrid object insertion pipeline that combines the strengths of both paradigms. Specifically, we focus on inserting bracelets into dynamic wrist scenes, leveraging the high temporal consistency of 3D Gaussian Splatting (3DGS) for initial rendering and refining the results using a 2D diffusion-based enhancement model to ensure realistic lighting interactions. Our method introduces a shading-driven pipeline that separates intrinsic object properties (albedo, shading, reflectance) and refines both shading and sRGB images for photorealism. To maintain temporal coherence, we optimize the 3DGS model with multi-frame weighted adjustments. This is the first approach to synergize 3D rendering and 2D diffusion for video object insertion, offering a robust solution for realistic and consistent video editing. Project Page: https://cjeen.github.io/BraceletPaper/
Shining Yourself: High-Fidelity Ornaments Virtual Try-on with Diffusion Model
Mar 20, 2025While virtual try-on for clothes and shoes with diffusion models has gained attraction, virtual try-on for ornaments, such as bracelets, rings, earrings, and necklaces, remains largely unexplored. Due to the intricate tiny patterns and repeated geometric sub-structures in most ornaments, it is much more difficult to guarantee identity and appearance consistency under large pose and scale variances between ornaments and models. This paper proposes the task of virtual try-on for ornaments and presents a method to improve the geometric and appearance preservation of ornament virtual try-ons. Specifically, we estimate an accurate wearing mask to improve the alignments between ornaments and models in an iterative scheme alongside the denoising process. To preserve structure details, we further regularize attention layers to map the reference ornament mask to the wearing mask in an implicit way. Experimental results demonstrate that our method successfully wears ornaments from reference images onto target models, handling substantial differences in scale and pose while preserving identity and achieving realistic visual effects.
Let Curves Speak: A Continuous Glucose Monitor based Large Sensor Foundation Model for Diabetes Management
Dec 12, 2024



While previous studies of AI in diabetes management focus on long-term risk, research on near-future glucose prediction remains limited but important as it enables timely diabetes self-management. Integrating AI with continuous glucose monitoring (CGM) holds promise for near-future glucose prediction. However, existing models have limitations in capturing patterns of blood glucose fluctuations and demonstrate poor generalizability. A robust approach is needed to leverage massive CGM data for near-future glucose prediction. We propose large sensor models (LSMs) to capture knowledge in CGM data by modeling patients as sequences of glucose. CGM-LSM is pretrained on 15.96 million glucose records from 592 diabetes patients for near-future glucose prediction. We evaluated CGM-LSM against state-of-the-art methods using the OhioT1DM dataset across various metrics, prediction horizons, and unseen patients. Additionally, we assessed its generalizability across factors like diabetes type, age, gender, and hour of day. CGM-LSM achieved exceptional performance, with an rMSE of 29.81 mg/dL for type 1 diabetes patients and 23.49 mg/dL for type 2 diabetes patients in a two-hour prediction horizon. For the OhioT1DM dataset, CGM-LSM achieved a one-hour rMSE of 15.64 mg/dL, halving the previous best of 31.97 mg/dL. Robustness analyses revealed consistent performance not only for unseen patients and future periods, but also across diabetes type, age, and gender. The model demonstrated adaptability to different hours of day, maintaining accuracy across periods of various activity intensity levels. CGM-LSM represents a transformative step in diabetes management by leveraging pretraining to uncover latent glucose generation patterns in sensor data. Our findings also underscore the broader potential of LSMs to drive innovation across domains involving complex sensor data.
RTMPose: Real-Time Multi-Person Pose Estimation based on MMPose
Mar 13, 2023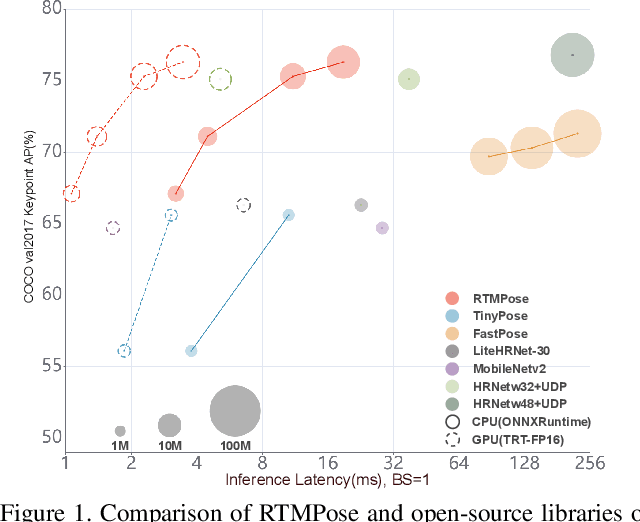
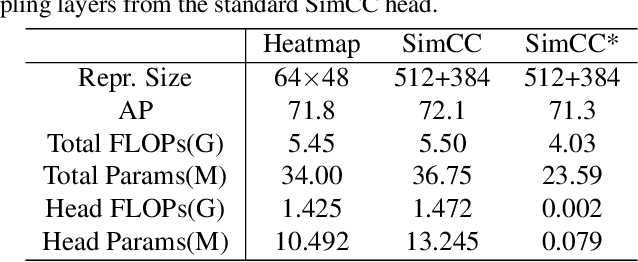
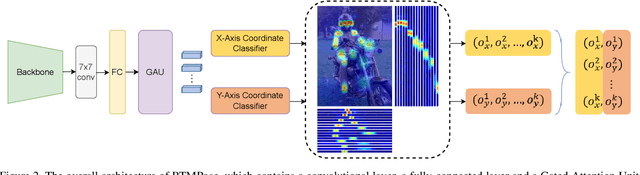

Recent studies on 2D pose estimation have achieved excellent performance on public benchmarks, yet its application in the industrial community still suffers from heavy model parameters and high latency. In order to bridge this gap, we empirically explore key factors in pose estimation including paradigm, model architecture, training strategy, and deployment, and present a high-performance real-time multi-person pose estimation framework, RTMPose, based on MMPose. Our RTMPose-m achieves 75.8% AP on COCO with 90+ FPS on an Intel i7-11700 CPU and 430+ FPS on an NVIDIA GTX 1660 Ti GPU, and RTMPose-l achieves 67.0% AP on COCO-WholeBody with 130+ FPS. To further evaluate RTMPose's capability in critical real-time applications, we also report the performance after deploying on the mobile device. Our RTMPose-s achieves 72.2% AP on COCO with 70+ FPS on a Snapdragon 865 chip, outperforming existing open-source libraries. Code and models are released at https://github.com/open-mmlab/mmpose/tree/1.x/projects/rtmpose.
FedKNOW: Federated Continual Learning with Signature Task Knowledge Integration at Edge
Dec 04, 2022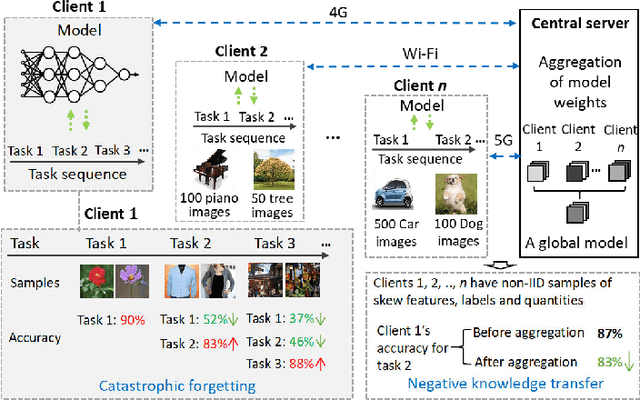
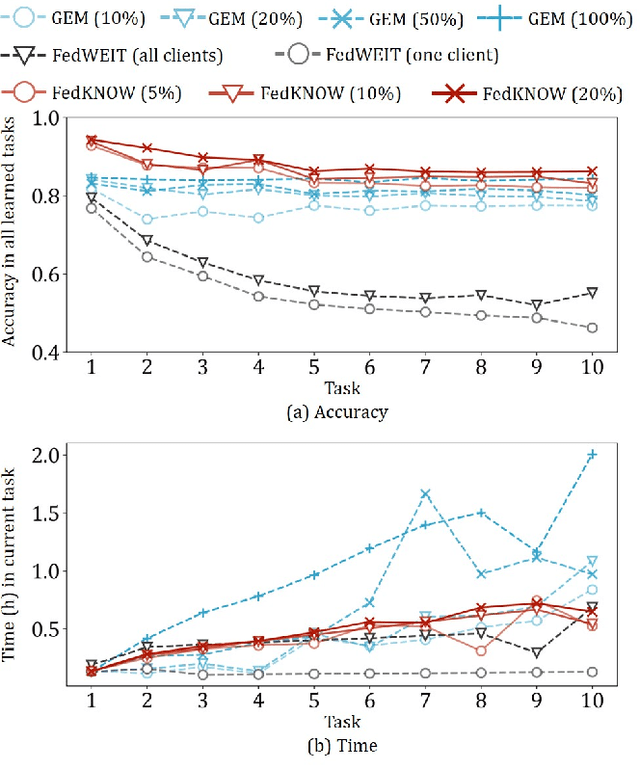
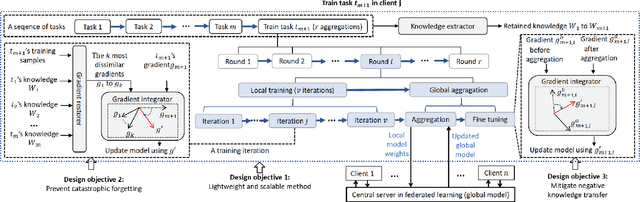
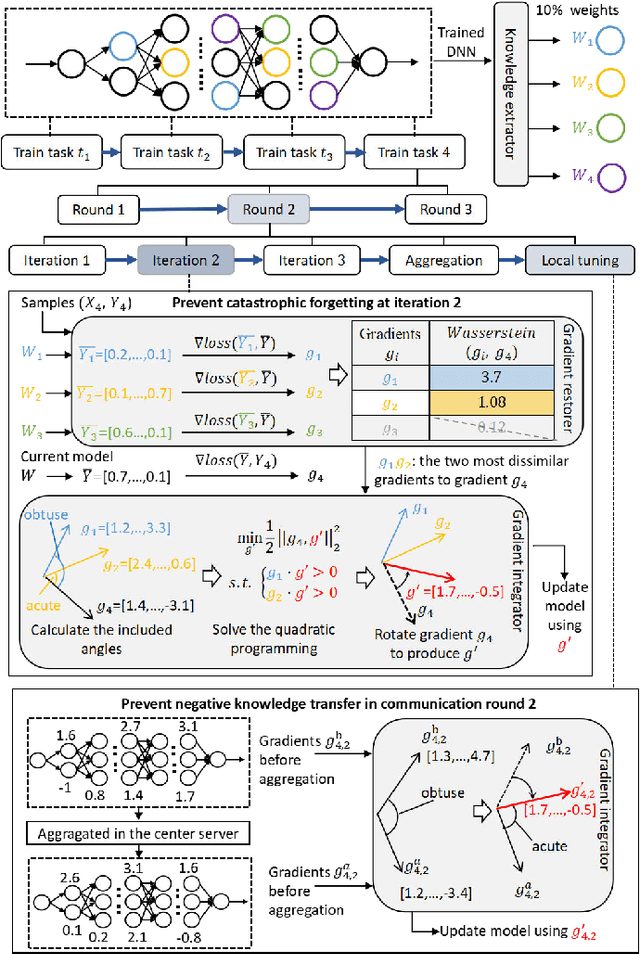
Deep Neural Networks (DNNs) have been ubiquitously adopted in internet of things and are becoming an integral of our daily life. When tackling the evolving learning tasks in real world, such as classifying different types of objects, DNNs face the challenge to continually retrain themselves according to the tasks on different edge devices. Federated continual learning is a promising technique that offers partial solutions but yet to overcome the following difficulties: the significant accuracy loss due to the limited on-device processing, the negative knowledge transfer caused by the limited communication of non-IID data, and the limited scalability on the tasks and edge devices. In this paper, we propose FedKNOW, an accurate and scalable federated continual learning framework, via a novel concept of signature task knowledge. FedKNOW is a client side solution that continuously extracts and integrates the knowledge of signature tasks which are highly influenced by the current task. Each client of FedKNOW is composed of a knowledge extractor, a gradient restorer and, most importantly, a gradient integrator. Upon training for a new task, the gradient integrator ensures the prevention of catastrophic forgetting and mitigation of negative knowledge transfer by effectively combining signature tasks identified from the past local tasks and other clients' current tasks through the global model. We implement FedKNOW in PyTorch and extensively evaluate it against state-of-the-art techniques using popular federated continual learning benchmarks. Extensive evaluation results on heterogeneous edge devices show that FedKNOW improves model accuracy by 63.24% without increasing model training time, reduces communication cost by 34.28%, and achieves more improvements under difficult scenarios such as large numbers of tasks or clients, and training different complex networks.
Atrial Fibrillation Detection Using Weight-Pruned, Log-Quantised Convolutional Neural Networks
Jun 14, 2022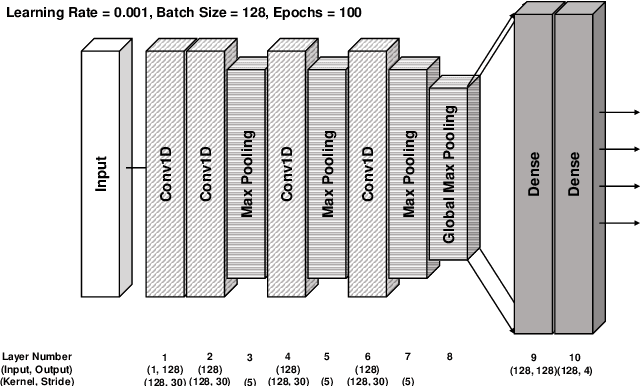
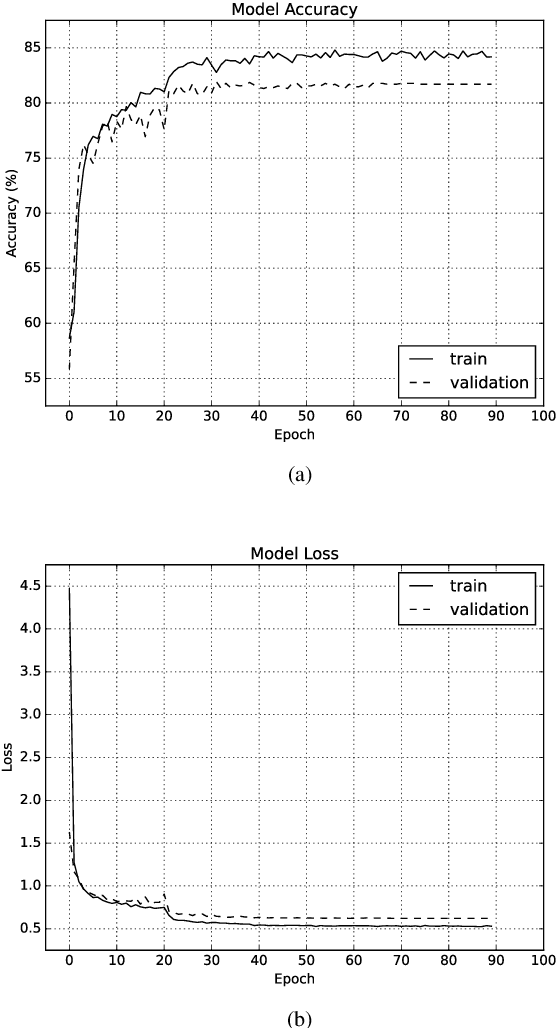

Deep neural networks (DNN) are a promising tool in medical applications. However, the implementation of complex DNNs on battery-powered devices is challenging due to high energy costs for communication. In this work, a convolutional neural network model is developed for detecting atrial fibrillation from electrocardiogram (ECG) signals. The model demonstrates high performance despite being trained on limited, variable-length input data. Weight pruning and logarithmic quantisation are combined to introduce sparsity and reduce model size, which can be exploited for reduced data movement and lower computational complexity. The final model achieved a 91.1% model compression ratio while maintaining high model accuracy of 91.7% and less than 1% loss.
LegoDNN: Block-grained Scaling of Deep Neural Networks for Mobile Vision
Dec 18, 2021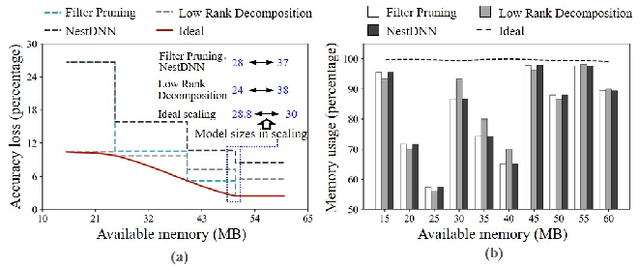
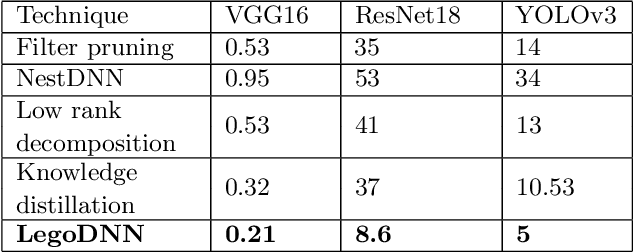
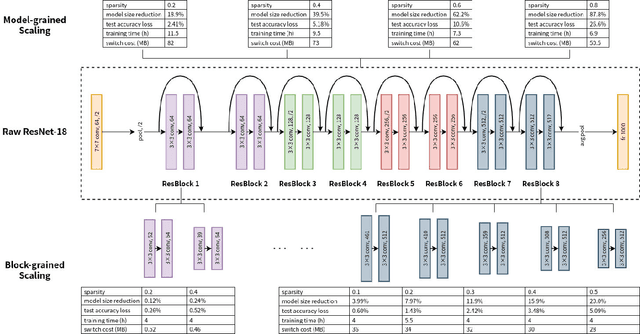
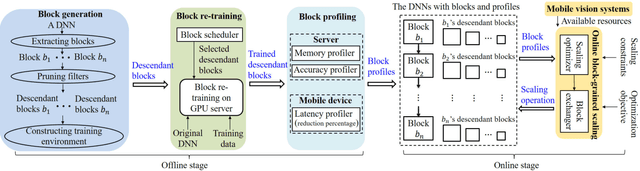
Deep neural networks (DNNs) have become ubiquitous techniques in mobile and embedded systems for applications such as image/object recognition and classification. The trend of executing multiple DNNs simultaneously exacerbate the existing limitations of meeting stringent latency/accuracy requirements on resource constrained mobile devices. The prior art sheds light on exploring the accuracy-resource tradeoff by scaling the model sizes in accordance to resource dynamics. However, such model scaling approaches face to imminent challenges: (i) large space exploration of model sizes, and (ii) prohibitively long training time for different model combinations. In this paper, we present LegoDNN, a lightweight, block-grained scaling solution for running multi-DNN workloads in mobile vision systems. LegoDNN guarantees short model training times by only extracting and training a small number of common blocks (e.g. 5 in VGG and 8 in ResNet) in a DNN. At run-time, LegoDNN optimally combines the descendant models of these blocks to maximize accuracy under specific resources and latency constraints, while reducing switching overhead via smart block-level scaling of the DNN. We implement LegoDNN in TensorFlow Lite and extensively evaluate it against state-of-the-art techniques (FLOP scaling, knowledge distillation and model compression) using a set of 12 popular DNN models. Evaluation results show that LegoDNN provides 1,296x to 279,936x more options in model sizes without increasing training time, thus achieving as much as 31.74% improvement in inference accuracy and 71.07% reduction in scaling energy consumptions.
* 13 pages, 15 figures