 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Label Gold Asymmetric Loss Correction with Single-Label Regulators
Aug 04, 2021



Multi-label learning is an emerging extension of the multi-class classification where an image contains multiple labels. Not only acquiring a clean and fully labeled dataset in multi-label learning is extremely expensive, but also many of the actual labels are corrupted or missing due to the automated or non-expert annotation techniques. Noisy label data decrease the prediction performance drastically. In this paper, we propose a novel Gold Asymmetric Loss Correction with Single-Label Regulators (GALC-SLR) that operates robust against noisy labels. GALC-SLR estimates the noise confusion matrix using single-label samples, then constructs an asymmetric loss correction via estimated confusion matrix to avoid overfitting to the noisy labels. Empirical results show that our method outperforms the state-of-the-art original asymmetric loss multi-label classifier under all corruption levels, showing mean average precision improvement up to 28.67% on a real world dataset of MS-COCO, yielding a better generalization of the unseen data and increased prediction performance.
End-to-End Learning from Noisy Crowd to Supervised Machine Learning Models
Nov 13, 2020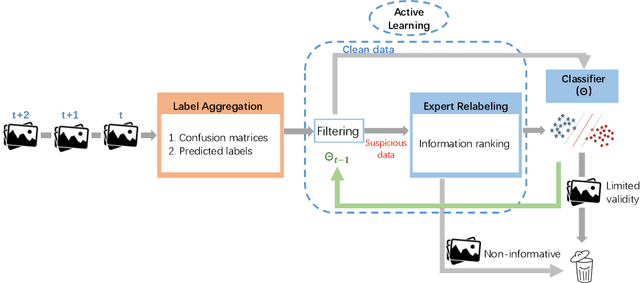
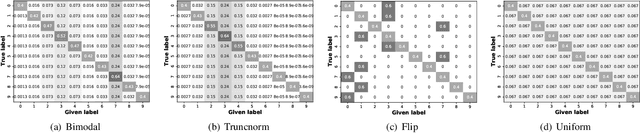
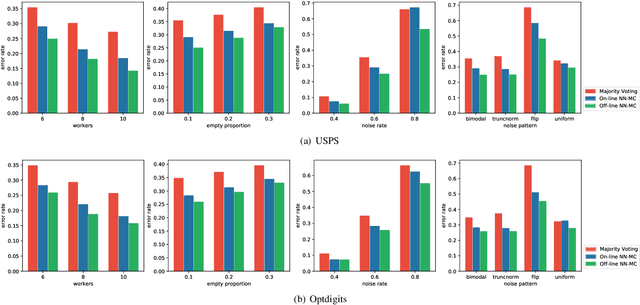
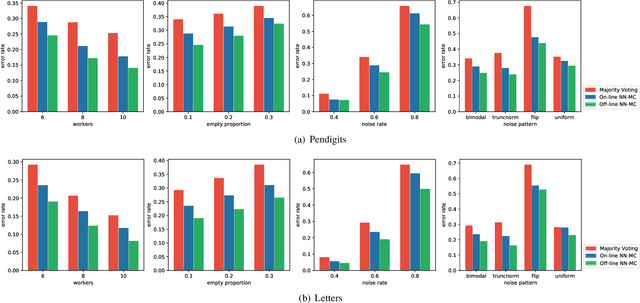
Labeling real-world datasets is time consuming but indispensable for supervised machine learning models. A common solution is to distribute the labeling task across a large number of non-expert workers via crowd-sourcing. Due to the varying background and experience of crowd workers, the obtained labels are highly prone to errors and even detrimental to the learning models. In this paper, we advocate using hybrid intelligence, i.e., combining deep models and human experts, to design an end-to-end learning framework from noisy crowd-sourced data, especially in an on-line scenario. We first summarize the state-of-the-art solutions that address the challenges of noisy labels from non-expert crowd and learn from multiple annotators. We show how label aggregation can benefit from estimating the annotators' confusion matrices to improve the learning process. Moreover, with the help of an expert labeler as well as classifiers, we cleanse aggregated labels of highly informative samples to enhance the final classification accuracy. We demonstrate the effectiveness of our strategies on several image datasets, i.e. UCI and CIFAR-10, using SVM and deep neural networks. Our evaluation shows that our on-line label aggregation with confusion matrix estimation reduces the error rate of labels by over 30%. Furthermore, relabeling only 10% of the data using the expert's results in over 90% classification accuracy with SVM.
TrustNet: Learning from Trusted Data Against (A)symmetric Label Noise
Jul 13, 2020
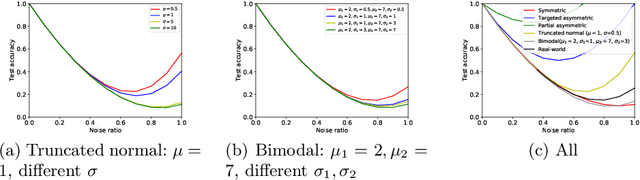

Robustness to label noise is a critical property for weakly-supervised classifiers trained on massive datasets. Robustness to label noise is a critical property for weakly-supervised classifiers trained on massive datasets. In this paper, we first derive analytical bound for any given noise patterns. Based on the insights, we design TrustNet that first adversely learns the pattern of noise corruption, being it both symmetric or asymmetric, from a small set of trusted data. Then, TrustNet is trained via a robust loss function, which weights the given labels against the inferred labels from the learned noise pattern. The weight is adjusted based on model uncertainty across training epochs. We evaluate TrustNet on synthetic label noise for CIFAR-10 and CIFAR-100, and real-world data with label noise, i.e., Clothing1M. We compare against state-of-the-art methods demonstrating the strong robustness of TrustNet under a diverse set of noise patterns.
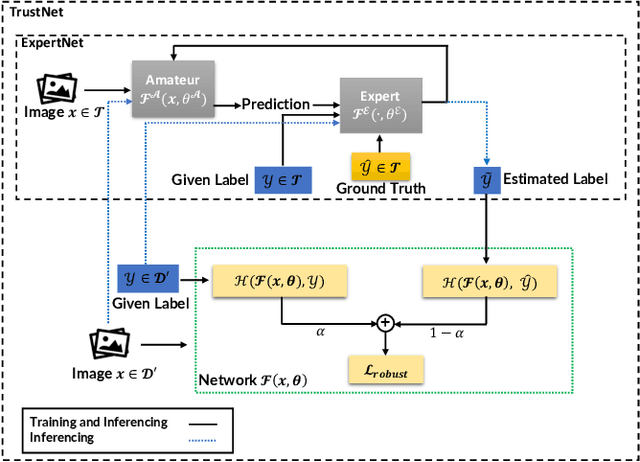
ExpertNet: Adversarial Learning and Recovery Against Noisy Labels
Jul 13, 2020
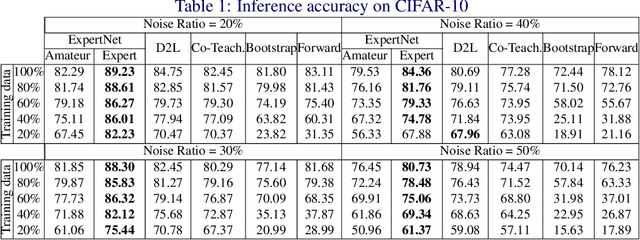
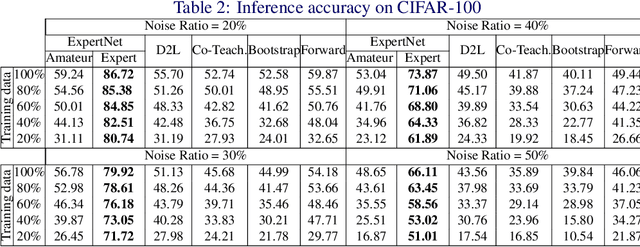
Today's available datasets in the wild, e.g., from social media and open platforms, present tremendous opportunities and challenges for deep learning, as there is a significant portion of tagged images, but often with noisy, i.e. erroneous, labels. Recent studies improve the robustness of deep models against noisy labels without the knowledge of true labels. In this paper, we advocate to derive a stronger classifier which proactively makes use of the noisy labels in addition to the original images - turning noisy labels into learning features. To such an end, we propose a novel framework, ExpertNet, composed of Amateur and Expert, which iteratively learn from each other. Amateur is a regular image classifier trained by the feedback of Expert, which imitates how human experts would correct the predicted labels from Amateur using the noise pattern learnt from the knowledge of both the noisy and ground truth labels. The trained Amateur and Expert proactively leverage the images and their noisy labels to infer image classes. Our empirical evaluations on noisy versions of CIFAR-10, CIFAR-100 and real-world data of Clothing1M show that the proposed model can achieve robust classification against a wide range of noise ratios and with as little as 20-50% training data, compared to state-of-the-art deep models that solely focus on distilling the impact of noisy labels.
QActor: On-line Active Learning for Noisy Labeled Stream Data
Jan 28, 2020
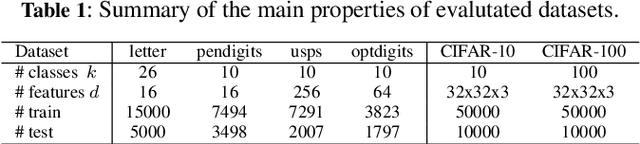

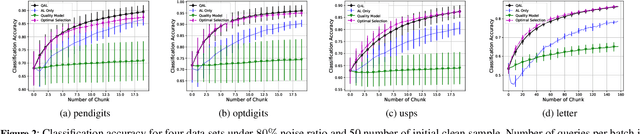
Noisy labeled data is more a norm than a rarity for self-generated content that is continuously published on the web and social media. Due to privacy concerns and governmental regulations, such a data stream can only be stored and used for learning purposes in a limited duration. To overcome the noise in this on-line scenario we propose QActor which novel combines: the selection of supposedly clean samples via quality models and actively querying an oracle for the most informative true labels. While the former can suffer from low data volumes of on-line scenarios, the latter is constrained by the availability and costs of human experts. QActor swiftly combines the merits of quality models for data filtering and oracle queries for cleaning the most informative data. The objective of QActor is to leverage the stringent oracle budget to robustly maximize the learning accuracy. QActor explores various strategies combining different query allocations and uncertainty measures. A central feature of QActor is to dynamically adjust the query limit according to the learning loss for each data batch. We extensively evaluate different image datasets fed into the classifier that can be standard machine learning (ML) models or deep neural networks (DNN) with noise label ratios ranging between 30% and 80%. Our results show that QActor can nearly match the optimal accuracy achieved using only clean data at the cost of at most an additional 6% of ground truth data from the oracle.