 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Inversion of Federated Diffusion Models
May 30, 2024Diffusion models are becoming defector generative models, which generate exceptionally high-resolution image data. Training effective diffusion models require massive real data, which is privately owned by distributed parties. Each data party can collaboratively train diffusion models in a federated learning manner by sharing gradients instead of the raw data. In this paper, we study the privacy leakage risk of gradient inversion attacks. First, we design a two-phase fusion optimization, GIDM, to leverage the well-trained generative model itself as prior knowledge to constrain the inversion search (latent) space, followed by pixel-wise fine-tuning. GIDM is shown to be able to reconstruct images almost identical to the original ones. Considering a more privacy-preserving training scenario, we then argue that locally initialized private training noise $\epsilon$ and sampling step t may raise additional challenges for the inversion attack. To solve this, we propose a triple-optimization GIDM+ that coordinates the optimization of the unknown data, $\epsilon$ and $t$. Our extensive evaluation results demonstrate the vulnerability of sharing gradient for data protection of diffusion models, even high-resolution images can be reconstructed with high quality.
SFDDM: Single-fold Distillation for Diffusion models
May 23, 2024While diffusion models effectively generate remarkable synthetic images, a key limitation is the inference inefficiency, requiring numerous sampling steps. To accelerate inference and maintain high-quality synthesis, teacher-student distillation is applied to compress the diffusion models in a progressive and binary manner by retraining, e.g., reducing the 1024-step model to a 128-step model in 3 folds. In this paper, we propose a single-fold distillation algorithm, SFDDM, which can flexibly compress the teacher diffusion model into a student model of any desired step, based on reparameterization of the intermediate inputs from the teacher model. To train the student diffusion, we minimize not only the output distance but also the distribution of the hidden variables between the teacher and student model. Extensive experiments on four datasets demonstrate that our student model trained by the proposed SFDDM is able to sample high-quality data with steps reduced to as little as approximately 1%, thus, trading off inference time. Our remarkable performance highlights that SFDDM effectively transfers knowledge in single-fold distillation, achieving semantic consistency and meaningful image interpolation.
AGIC: Approximate Gradient Inversion Attack on Federated Learning
Apr 28, 2022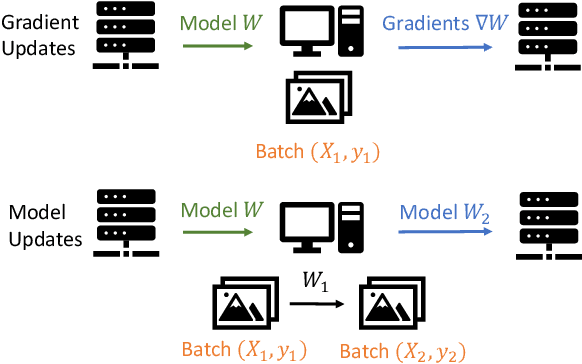

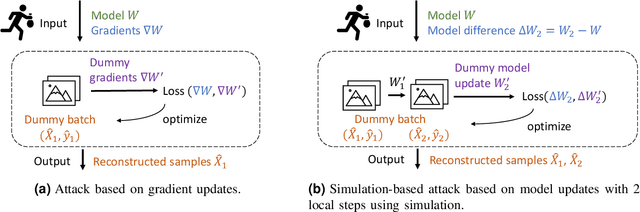
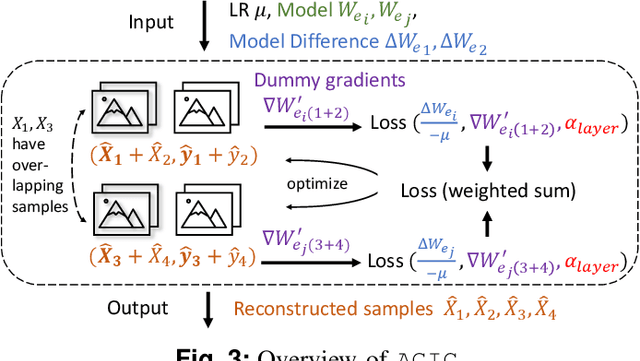
Federated learning is a private-by-design distributed learning paradigm where clients train local models on their own data before a central server aggregates their local updates to compute a global model. Depending on the aggregation method used, the local updates are either the gradients or the weights of local learning models. Recent reconstruction attacks apply a gradient inversion optimization on the gradient update of a single minibatch to reconstruct the private data used by clients during training. As the state-of-the-art reconstruction attacks solely focus on single update, realistic adversarial scenarios are overlooked, such as observation across multiple updates and updates trained from multiple mini-batches. A few studies consider a more challenging adversarial scenario where only model updates based on multiple mini-batches are observable, and resort to computationally expensive simulation to untangle the underlying samples for each local step. In this paper, we propose AGIC, a novel Approximate Gradient Inversion Attack that efficiently and effectively reconstructs images from both model or gradient updates, and across multiple epochs. In a nutshell, AGIC (i) approximates gradient updates of used training samples from model updates to avoid costly simulation procedures, (ii) leverages gradient/model updates collected from multiple epochs, and (iii) assigns increasing weights to layers with respect to the neural network structure for reconstruction quality. We extensively evaluate AGIC on three datasets, CIFAR-10, CIFAR-100 and ImageNet. Our results show that AGIC increases the peak signal-to-noise ratio (PSNR) by up to 50% compared to two representative state-of-the-art gradient inversion attacks. Furthermore, AGIC is faster than the state-of-the-art simulation based attack, e.g., it is 5x faster when attacking FedAvg with 8 local steps in between model updates.
MEGA: Model Stealing via Collaborative Generator-Substitute Networks
Jan 31, 2022



Deep machine learning models are increasingly deployedin the wild for providing services to users. Adversaries maysteal the knowledge of these valuable models by trainingsubstitute models according to the inference results of thetargeted deployed models. Recent data-free model stealingmethods are shown effective to extract the knowledge of thetarget model without using real query examples, but they as-sume rich inference information, e.g., class probabilities andlogits. However, they are all based on competing generator-substitute networks and hence encounter training instability.In this paper we propose a data-free model stealing frame-work,MEGA, which is based on collaborative generator-substitute networks and only requires the target model toprovide label prediction for synthetic query examples. Thecore of our method is a model stealing optimization con-sisting of two collaborative models (i) the substitute modelwhich imitates the target model through the synthetic queryexamples and their inferred labels and (ii) the generatorwhich synthesizes images such that the confidence of thesubstitute model over each query example is maximized. Wepropose a novel coordinate descent training procedure andanalyze its convergence. We also empirically evaluate thetrained substitute model on three datasets and its applicationon black-box adversarial attacks. Our results show that theaccuracy of our trained substitute model and the adversarialattack success rate over it can be up to 33% and 40% higherthan state-of-the-art data-free black-box attacks.
Is Shapley Value fair? Improving Client Selection for Mavericks in Federated Learning
Jun 20, 2021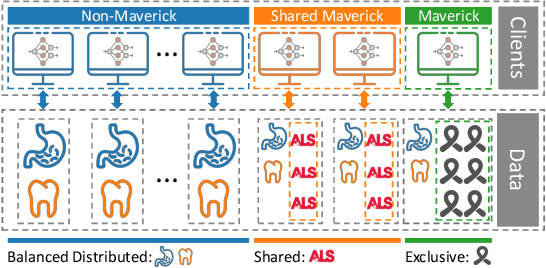
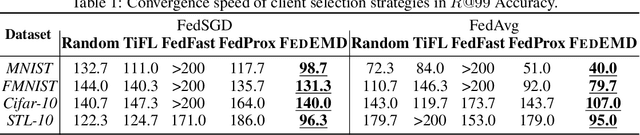


Shapley Value is commonly adopted to measure and incentivize client participation in federated learning. In this paper, we show -- theoretically and through simulations -- that Shapley Value underestimates the contribution of a common type of client: the Maverick. Mavericks are clients that differ both in data distribution and data quantity and can be the sole owners of certain types of data. Selecting the right clients at the right moment is important for federated learning to reduce convergence times and improve accuracy. We propose FedEMD, an adaptive client selection strategy based on the Wasserstein distance between the local and global data distributions. As FedEMD adapts the selection probability such that Mavericks are preferably selected when the model benefits from improvement on rare classes, it consistently ensures the fast convergence in the presence of different types of Mavericks. Compared to existing strategies, including Shapley Value-based ones, FedEMD improves the convergence of neural network classifiers by at least 26.9% for FedAvg aggregation compared with the state of the art.
End-to-End Learning from Noisy Crowd to Supervised Machine Learning Models
Nov 13, 2020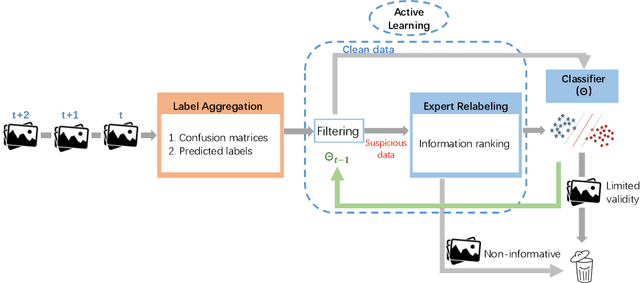
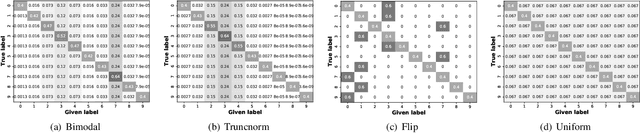
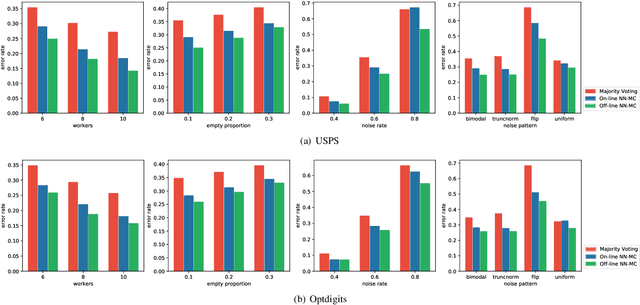
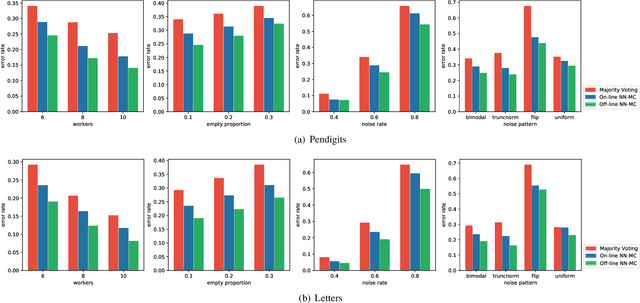
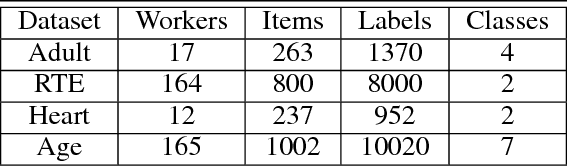
Labeling real-world datasets is time consuming but indispensable for supervised machine learning models. A common solution is to distribute the labeling task across a large number of non-expert workers via crowd-sourcing. Due to the varying background and experience of crowd workers, the obtained labels are highly prone to errors and even detrimental to the learning models. In this paper, we advocate using hybrid intelligence, i.e., combining deep models and human experts, to design an end-to-end learning framework from noisy crowd-sourced data, especially in an on-line scenario. We first summarize the state-of-the-art solutions that address the challenges of noisy labels from non-expert crowd and learn from multiple annotators. We show how label aggregation can benefit from estimating the annotators' confusion matrices to improve the learning process. Moreover, with the help of an expert labeler as well as classifiers, we cleanse aggregated labels of highly informative samples to enhance the final classification accuracy. We demonstrate the effectiveness of our strategies on several image datasets, i.e. UCI and CIFAR-10, using SVM and deep neural networks. Our evaluation shows that our on-line label aggregation with confusion matrix estimation reduces the error rate of labels by over 30%. Furthermore, relabeling only 10% of the data using the expert's results in over 90% classification accuracy with SVM.
Label Aggregation via Finding Consensus Between Models
Jul 19, 2018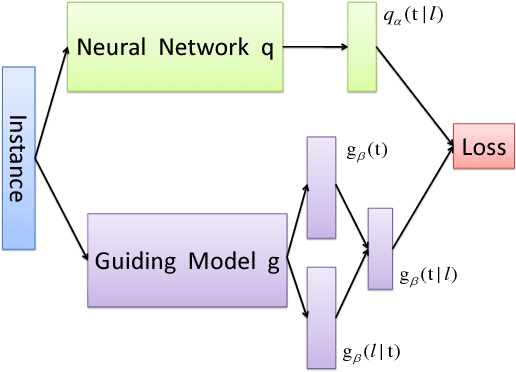
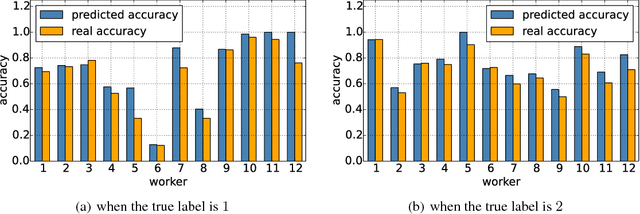

Label aggregation is an efficient and low cost way to make large datasets for supervised learning. It takes the noisy labels provided by non-experts and infers the unknown true labels. In this paper, we propose a novel label aggregation algorithm which includes a label aggregation neural network. The learning task in this paper is unsupervised. In order to train the neural network, we try to design a suitable guiding model to define the loss function. The optimization goal of our algorithm is to find the consensus between the predictions of the neural network and the guiding model. This algorithm is easy to optimize using mini-batch stochastic optimization methods. Since the choices of the neural network and the guiding model are very flexible, our label aggregation algorithm is easy to extend. According to the algorithm framework, we design two novel models to aggregate noisy labels. Experimental results show that our models achieve better results than state-of-the-art label aggregation methods.
Generative Models for Learning from Crowds
Oct 03, 2017



In this paper, we propose generative probabilistic models for label aggregation. We use Gibbs sampling and a novel variational inference algorithm to perform the posterior inference. Empirical results show that our methods consistently outperform state-of-the-art methods.