 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Inversion of Federated Diffusion Models
May 30, 2024Diffusion models are becoming defector generative models, which generate exceptionally high-resolution image data. Training effective diffusion models require massive real data, which is privately owned by distributed parties. Each data party can collaboratively train diffusion models in a federated learning manner by sharing gradients instead of the raw data. In this paper, we study the privacy leakage risk of gradient inversion attacks. First, we design a two-phase fusion optimization, GIDM, to leverage the well-trained generative model itself as prior knowledge to constrain the inversion search (latent) space, followed by pixel-wise fine-tuning. GIDM is shown to be able to reconstruct images almost identical to the original ones. Considering a more privacy-preserving training scenario, we then argue that locally initialized private training noise $\epsilon$ and sampling step t may raise additional challenges for the inversion attack. To solve this, we propose a triple-optimization GIDM+ that coordinates the optimization of the unknown data, $\epsilon$ and $t$. Our extensive evaluation results demonstrate the vulnerability of sharing gradient for data protection of diffusion models, even high-resolution images can be reconstructed with high quality.
SFDDM: Single-fold Distillation for Diffusion models
May 23, 2024



While diffusion models effectively generate remarkable synthetic images, a key limitation is the inference inefficiency, requiring numerous sampling steps. To accelerate inference and maintain high-quality synthesis, teacher-student distillation is applied to compress the diffusion models in a progressive and binary manner by retraining, e.g., reducing the 1024-step model to a 128-step model in 3 folds. In this paper, we propose a single-fold distillation algorithm, SFDDM, which can flexibly compress the teacher diffusion model into a student model of any desired step, based on reparameterization of the intermediate inputs from the teacher model. To train the student diffusion, we minimize not only the output distance but also the distribution of the hidden variables between the teacher and student model. Extensive experiments on four datasets demonstrate that our student model trained by the proposed SFDDM is able to sample high-quality data with steps reduced to as little as approximately 1%, thus, trading off inference time. Our remarkable performance highlights that SFDDM effectively transfers knowledge in single-fold distillation, achieving semantic consistency and meaningful image interpolation.
Blind leads Blind: A Zero-Knowledge Attack on Federated Learning
Feb 07, 2022Attacks on Federated Learning (FL) can severely reduce the quality of the generated models and limit the usefulness of this emerging learning paradigm that enables on-premise decentralized learning. There have been various untargeted attacks on FL, but they are not widely applicable as they i) assume that the attacker knows every update of benign clients, which is indeed sent in encrypted form to the central server, or ii) assume that the attacker has a large dataset and sufficient resources to locally train updates imitating benign parties. In this paper, we design a zero-knowledge untargeted attack (ZKA), which synthesizes malicious data to craft adversarial models without eavesdropping on the transmission of benign clients at all or requiring a large quantity of task-specific training data. To inject malicious input into the FL system by synthetic data, ZKA has two variants. ZKA-R generates adversarial ambiguous data by reversing engineering from the global models. To enable stealthiness, ZKA-G trains the local model on synthetic data from the generator that aims to synthesize images different from a randomly chosen class. Furthermore, we add a novel distance-based regularization term for both attacks to further enhance stealthiness. Experimental results on Fashion-MNIST and CIFAR-10 show that the ZKA achieves similar or even higher attack success rate than the state-of-the-art untargeted attacks against various defense mechanisms, namely more than 50% for Cifar-10 for all considered defense mechanisms. As expected, ZKA-G is better at circumventing defenses, even showing a defense pass rate of close to 90% when ZKA-R only achieves 70%. Higher data heterogeneity favours ZKA-R since detection becomes harder.
Attacks and Defenses for Free-Riders in Multi-Discriminator GAN
Jan 24, 2022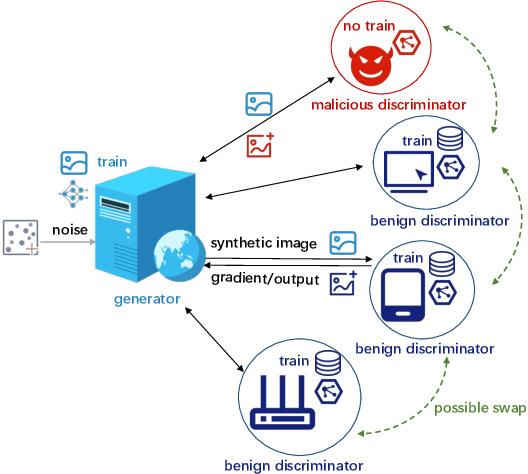
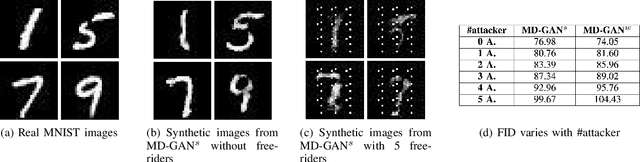
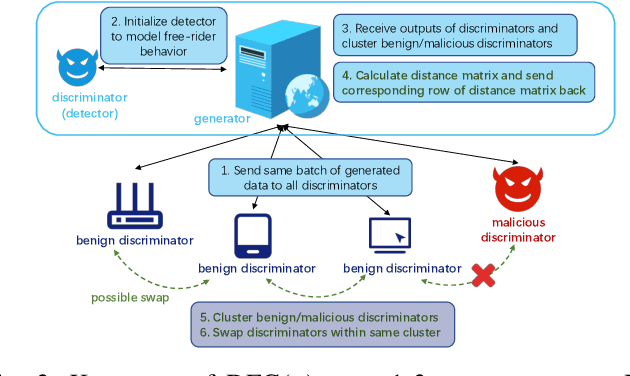

Generative Adversarial Networks (GANs) are increasingly adopted by the industry to synthesize realistic images. Due to data not being centrally available, Multi-Discriminator (MD)-GANs training framework employs multiple discriminators that have direct access to the real data. Distributedly training a joint GAN model entails the risk of free-riders, i.e., participants that aim to benefit from the common model while only pretending to participate in the training process. In this paper, we conduct the first characterization study of the impact of free-riders on MD-GAN. Based on two production prototypes of MD-GAN, we find that free-riders drastically reduce the ability of MD-GANs to produce images that are indistinguishable from real data, i.e., they increase the FID score -- the standard measure to assess the quality of generated images. To mitigate the model degradation, we propose a defense strategy against free-riders in MD-GAN, termed DFG. DFG distinguishes free-riders and benign participants through periodic probing and clustering of discriminators' responses based on a reference response of free-riders, which then allows the generator to exclude the detected free-riders from the training. Furthermore, we extend our defense, termed DFG+, to enable discriminators to filter out free-riders at the variant of MD-GAN that allows peer exchanges of discriminators networks. Extensive evaluation on various scenarios of free-riders, MD-GAN architecture, and three datasets show that our defenses effectively detect free-riders. With 1 to 5 free-riders, DFG and DFG+ averagely decreases FID by 5.22% to 11.53% for CIFAR10 and 5.79% to 13.22% for CIFAR100 in comparison to an attack without defense. In a shell, the proposed DFG(+) can effectively defend against free-riders without affecting benign clients at a negligible computation overhead.
Is Shapley Value fair? Improving Client Selection for Mavericks in Federated Learning
Jun 20, 2021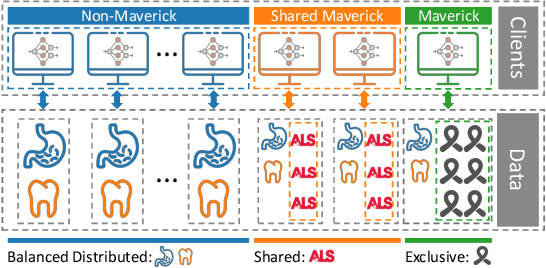
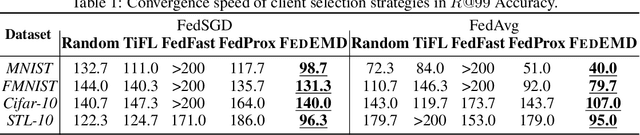


Shapley Value is commonly adopted to measure and incentivize client participation in federated learning. In this paper, we show -- theoretically and through simulations -- that Shapley Value underestimates the contribution of a common type of client: the Maverick. Mavericks are clients that differ both in data distribution and data quantity and can be the sole owners of certain types of data. Selecting the right clients at the right moment is important for federated learning to reduce convergence times and improve accuracy. We propose FedEMD, an adaptive client selection strategy based on the Wasserstein distance between the local and global data distributions. As FedEMD adapts the selection probability such that Mavericks are preferably selected when the model benefits from improvement on rare classes, it consistently ensures the fast convergence in the presence of different types of Mavericks. Compared to existing strategies, including Shapley Value-based ones, FedEMD improves the convergence of neural network classifiers by at least 26.9% for FedAvg aggregation compared with the state of the art.