 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQActor: On-line Active Learning for Noisy Labeled Stream Data
Paper and Code
Jan 28, 2020

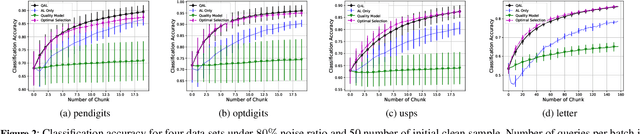
Noisy labeled data is more a norm than a rarity for self-generated content that is continuously published on the web and social media. Due to privacy concerns and governmental regulations, such a data stream can only be stored and used for learning purposes in a limited duration. To overcome the noise in this on-line scenario we propose QActor which novel combines: the selection of supposedly clean samples via quality models and actively querying an oracle for the most informative true labels. While the former can suffer from low data volumes of on-line scenarios, the latter is constrained by the availability and costs of human experts. QActor swiftly combines the merits of quality models for data filtering and oracle queries for cleaning the most informative data. The objective of QActor is to leverage the stringent oracle budget to robustly maximize the learning accuracy. QActor explores various strategies combining different query allocations and uncertainty measures. A central feature of QActor is to dynamically adjust the query limit according to the learning loss for each data batch. We extensively evaluate different image datasets fed into the classifier that can be standard machine learning (ML) models or deep neural networks (DNN) with noise label ratios ranging between 30% and 80%. Our results show that QActor can nearly match the optimal accuracy achieved using only clean data at the cost of at most an additional 6% of ground truth data from the oracle.