 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking MLLM Itself as a Segmenter with a Single Segmentation Token
Mar 19, 2026Recent segmentation methods leveraging Multi-modal Large Language Models (MLLMs) have shown reliable object-level segmentation and enhanced spatial perception. However, almost all previous methods predominantly rely on specialist mask decoders to interpret masks from generated segmentation-related embeddings and visual features, or incorporate multiple additional tokens to assist. This paper aims to investigate whether and how we can unlock segmentation from MLLM itSELF with 1 segmentation Embedding (SELF1E) while achieving competitive results, which eliminates the need for external decoders. To this end, our approach targets the fundamental limitation of resolution reduction in pixel-shuffled image features from MLLMs. First, we retain image features at their original uncompressed resolution, and refill them with residual features extracted from MLLM-processed compressed features, thereby improving feature precision. Subsequently, we integrate pixel-unshuffle operations on image features with and without LLM processing, respectively, to unleash the details of compressed features and amplify the residual features under uncompressed resolution, which further enhances the resolution of refilled features. Moreover, we redesign the attention mask with dual perception pathways, i.e., image-to-image and image-to-segmentation, enabling rich feature interaction between pixels and the segmentation token. Comprehensive experiments across multiple segmentation tasks validate that SELF1E achieves performance competitive with specialist mask decoder-based methods, demonstrating the feasibility of decoder-free segmentation in MLLMs. Project page: https://github.com/ANDYZAQ/SELF1E.
Real-world Reinforcement Learning from Suboptimal Interventions
Dec 30, 2025Real-world reinforcement learning (RL) offers a promising approach to training precise and dexterous robotic manipulation policies in an online manner, enabling robots to learn from their own experience while gradually reducing human labor. However, prior real-world RL methods often assume that human interventions are optimal across the entire state space, overlooking the fact that even expert operators cannot consistently provide optimal actions in all states or completely avoid mistakes. Indiscriminately mixing intervention data with robot-collected data inherits the sample inefficiency of RL, while purely imitating intervention data can ultimately degrade the final performance achievable by RL. The question of how to leverage potentially suboptimal and noisy human interventions to accelerate learning without being constrained by them thus remains open. To address this challenge, we propose SiLRI, a state-wise Lagrangian reinforcement learning algorithm for real-world robot manipulation tasks. Specifically, we formulate the online manipulation problem as a constrained RL optimization, where the constraint bound at each state is determined by the uncertainty of human interventions. We then introduce a state-wise Lagrange multiplier and solve the problem via a min-max optimization, jointly optimizing the policy and the Lagrange multiplier to reach a saddle point. Built upon a human-as-copilot teleoperation system, our algorithm is evaluated through real-world experiments on diverse manipulation tasks. Experimental results show that SiLRI effectively exploits human suboptimal interventions, reducing the time required to reach a 90% success rate by at least 50% compared with the state-of-the-art RL method HIL-SERL, and achieving a 100% success rate on long-horizon manipulation tasks where other RL methods struggle to succeed. Project website: https://silri-rl.github.io/.
CoMBO: Conflict Mitigation via Branched Optimization for Class Incremental Segmentation
Apr 05, 2025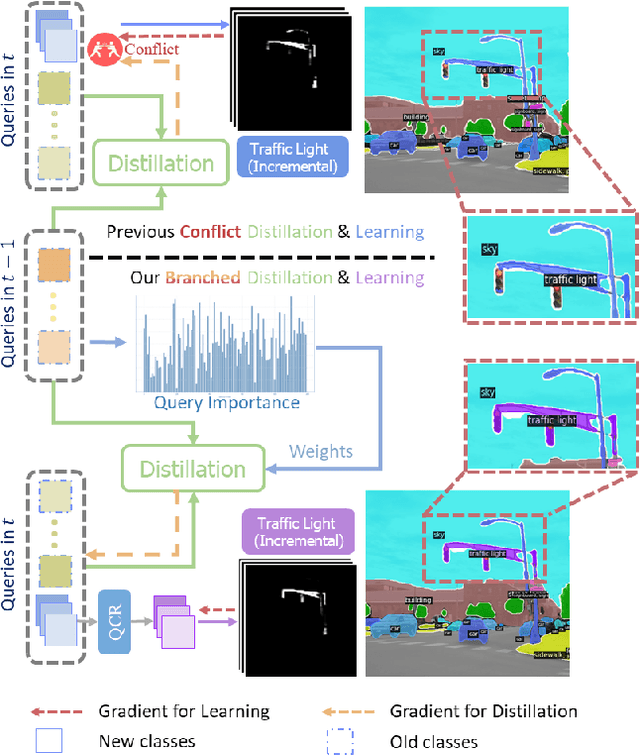
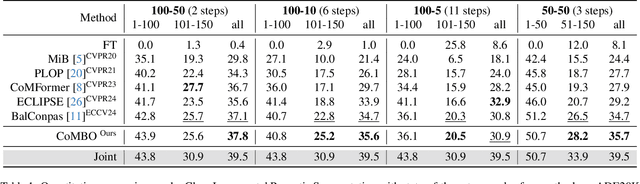
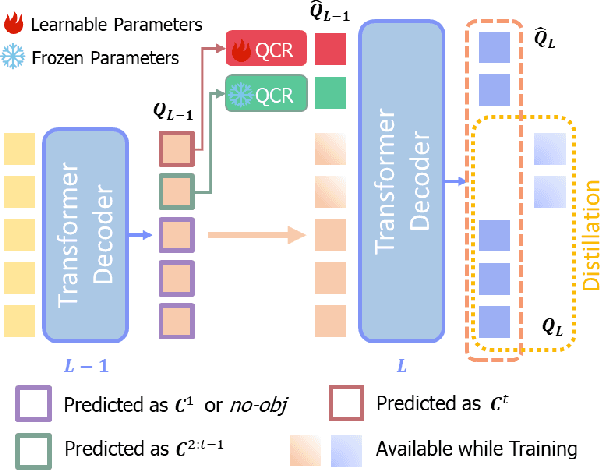
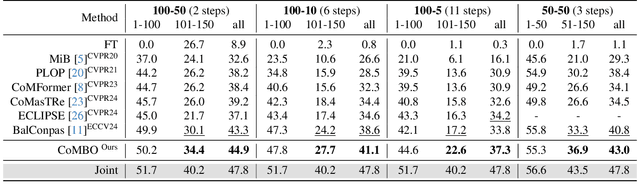
Effective Class Incremental Segmentation (CIS) requires simultaneously mitigating catastrophic forgetting and ensuring sufficient plasticity to integrate new classes. The inherent conflict above often leads to a back-and-forth, which turns the objective into finding the balance between the performance of previous~(old) and incremental~(new) classes. To address this conflict, we introduce a novel approach, Conflict Mitigation via Branched Optimization~(CoMBO). Within this approach, we present the Query Conflict Reduction module, designed to explicitly refine queries for new classes through lightweight, class-specific adapters. This module provides an additional branch for the acquisition of new classes while preserving the original queries for distillation. Moreover, we develop two strategies to further mitigate the conflict following the branched structure, \textit{i.e.}, the Half-Learning Half-Distillation~(HDHL) over classification probabilities, and the Importance-Based Knowledge Distillation~(IKD) over query features. HDHL selectively engages in learning for classification probabilities of queries that match the ground truth of new classes, while aligning unmatched ones to the corresponding old probabilities, thus ensuring retention of old knowledge while absorbing new classes via learning negative samples. Meanwhile, IKD assesses the importance of queries based on their matching degree to old classes, prioritizing the distillation of important features and allowing less critical features to evolve. Extensive experiments in Class Incremental Panoptic and Semantic Segmentation settings have demonstrated the superior performance of CoMBO. Project page: https://guangyu-ryan.github.io/CoMBO.
HACTS: a Human-As-Copilot Teleoperation System for Robot Learning
Mar 31, 2025Teleoperation is essential for autonomous robot learning, especially in manipulation tasks that require human demonstrations or corrections. However, most existing systems only offer unilateral robot control and lack the ability to synchronize the robot's status with the teleoperation hardware, preventing real-time, flexible intervention. In this work, we introduce HACTS (Human-As-Copilot Teleoperation System), a novel system that establishes bilateral, real-time joint synchronization between a robot arm and teleoperation hardware. This simple yet effective feedback mechanism, akin to a steering wheel in autonomous vehicles, enables the human copilot to intervene seamlessly while collecting action-correction data for future learning. Implemented using 3D-printed components and low-cost, off-the-shelf motors, HACTS is both accessible and scalable. Our experiments show that HACTS significantly enhances performance in imitation learning (IL) and reinforcement learning (RL) tasks, boosting IL recovery capabilities and data efficiency, and facilitating human-in-the-loop RL. HACTS paves the way for more effective and interactive human-robot collaboration and data-collection, advancing the capabilities of robot manipulation.
ACL-QL: Adaptive Conservative Level in Q-Learning for Offline Reinforcement Learning
Dec 22, 2024Offline Reinforcement Learning (RL), which operates solely on static datasets without further interactions with the environment, provides an appealing alternative to learning a safe and promising control policy. The prevailing methods typically learn a conservative policy to mitigate the problem of Q-value overestimation, but it is prone to overdo it, leading to an overly conservative policy. Moreover, they optimize all samples equally with fixed constraints, lacking the nuanced ability to control conservative levels in a fine-grained manner. Consequently, this limitation results in a performance decline. To address the above two challenges in a united way, we propose a framework, Adaptive Conservative Level in Q-Learning (ACL-QL), which limits the Q-values in a mild range and enables adaptive control on the conservative level over each state-action pair, i.e., lifting the Q-values more for good transitions and less for bad transitions. We theoretically analyze the conditions under which the conservative level of the learned Q-function can be limited in a mild range and how to optimize each transition adaptively. Motivated by the theoretical analysis, we propose a novel algorithm, ACL-QL, which uses two learnable adaptive weight functions to control the conservative level over each transition. Subsequently, we design a monotonicity loss and surrogate losses to train the adaptive weight functions, Q-function, and policy network alternatively. We evaluate ACL-QL on the commonly used D4RL benchmark and conduct extensive ablation studies to illustrate the effectiveness and state-of-the-art performance compared to existing offline DRL baselines.
Bridge the Points: Graph-based Few-shot Segment Anything Semantically
Oct 09, 2024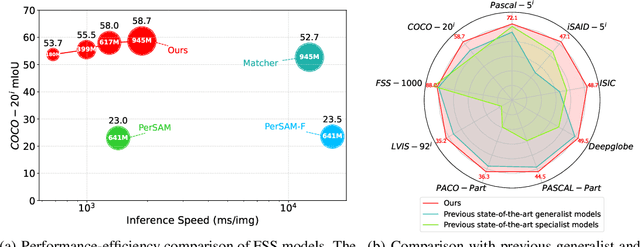
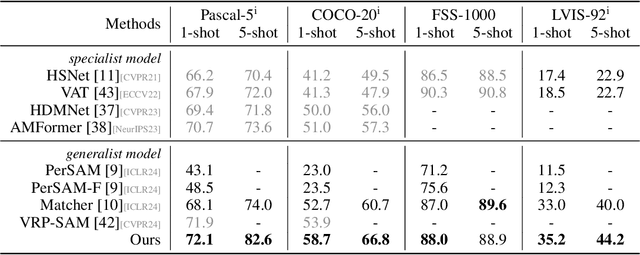
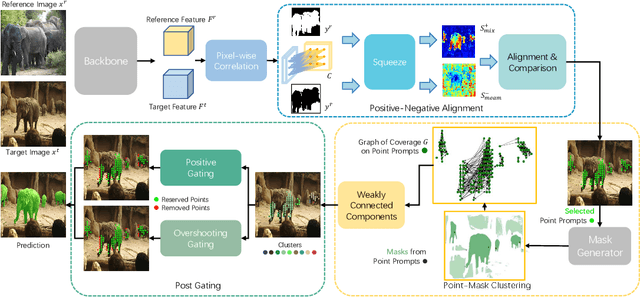
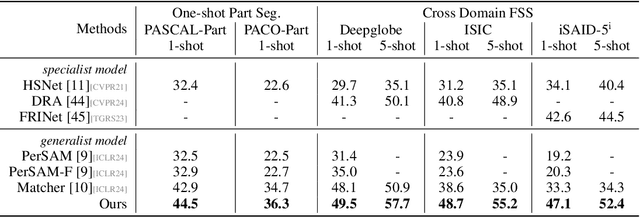
The recent advancements in large-scale pre-training techniques have significantly enhanced the capabilities of vision foundation models, notably the Segment Anything Model (SAM), which can generate precise masks based on point and box prompts. Recent studies extend SAM to Few-shot Semantic Segmentation (FSS), focusing on prompt generation for SAM-based automatic semantic segmentation. However, these methods struggle with selecting suitable prompts, require specific hyperparameter settings for different scenarios, and experience prolonged one-shot inference times due to the overuse of SAM, resulting in low efficiency and limited automation ability. To address these issues, we propose a simple yet effective approach based on graph analysis. In particular, a Positive-Negative Alignment module dynamically selects the point prompts for generating masks, especially uncovering the potential of the background context as the negative reference. Another subsequent Point-Mask Clustering module aligns the granularity of masks and selected points as a directed graph, based on mask coverage over points. These points are then aggregated by decomposing the weakly connected components of the directed graph in an efficient manner, constructing distinct natural clusters. Finally, the positive and overshooting gating, benefiting from graph-based granularity alignment, aggregate high-confident masks and filter out the false-positive masks for final prediction, reducing the usage of additional hyperparameters and redundant mask generation. Extensive experimental analysis across standard FSS, One-shot Part Segmentation, and Cross Domain FSS datasets validate the effectiveness and efficiency of the proposed approach, surpassing state-of-the-art generalist models with a mIoU of 58.7% on COCO-20i and 35.2% on LVIS-92i. The code is available in https://andyzaq.github.io/GF-SAM/.
Benchmarking the Text-to-SQL Capability of Large Language Models: A Comprehensive Evaluation
Mar 06, 2024



Large Language Models (LLMs) have emerged as a powerful tool in advancing the Text-to-SQL task, significantly outperforming traditional methods. Nevertheless, as a nascent research field, there is still no consensus on the optimal prompt templates and design frameworks. Additionally, existing benchmarks inadequately explore the performance of LLMs across the various sub-tasks of the Text-to-SQL process, which hinders the assessment of LLMs' cognitive capabilities and the optimization of LLM-based solutions. To address the aforementioned issues, we firstly construct a new dataset designed to mitigate the risk of overfitting in LLMs. Then we formulate five evaluation tasks to comprehensively assess the performance of diverse methods across various LLMs throughout the Text-to-SQL process.Our study highlights the performance disparities among LLMs and proposes optimal in-context learning solutions tailored to each task. These findings offer valuable insights for enhancing the development of LLM-based Text-to-SQL systems.
An Efficient Generalizable Framework for Visuomotor Policies via Control-aware Augmentation and Privilege-guided Distillation
Jan 17, 2024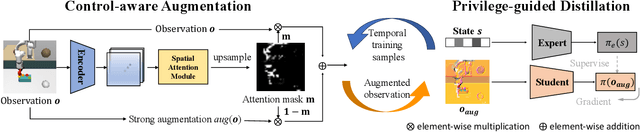
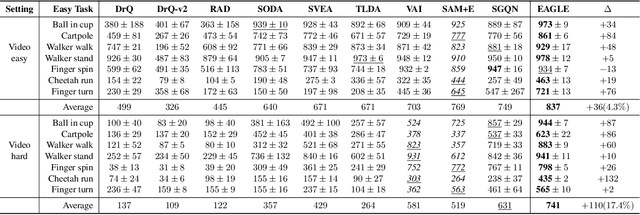
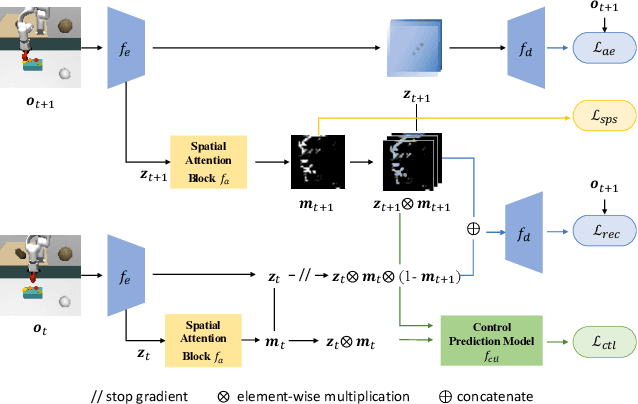
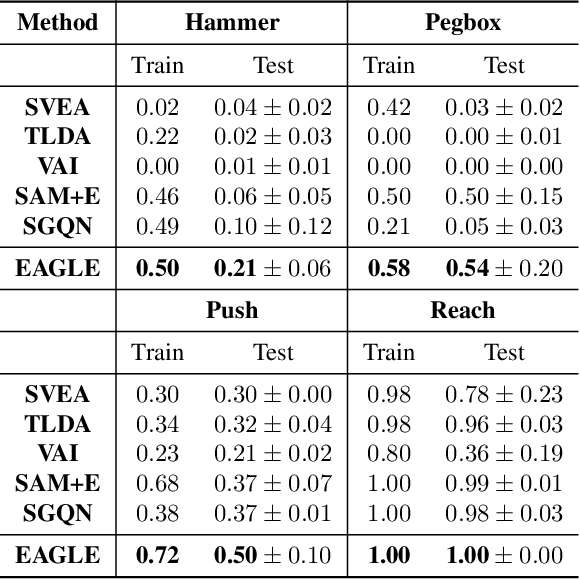
Visuomotor policies, which learn control mechanisms directly from high-dimensional visual observations, confront challenges in adapting to new environments with intricate visual variations. Data augmentation emerges as a promising method for bridging these generalization gaps by enriching data variety. However, straightforwardly augmenting the entire observation shall impose excessive burdens on policy learning and may even result in performance degradation. In this paper, we propose to improve the generalization ability of visuomotor policies as well as preserve training stability from two aspects: 1) We learn a control-aware mask through a self-supervised reconstruction task with three auxiliary losses and then apply strong augmentation only to those control-irrelevant regions based on the mask to reduce the generalization gaps. 2) To address training instability issues prevalent in visual reinforcement learning (RL), we distill the knowledge from a pretrained RL expert processing low-level environment states, to the student visuomotor policy. The policy is subsequently deployed to unseen environments without any further finetuning. We conducted comparison and ablation studies across various benchmarks: the DMControl Generalization Benchmark (DMC-GB), the enhanced Robot Manipulation Distraction Benchmark (RMDB), and a specialized long-horizontal drawer-opening robotic task. The extensive experimental results well demonstrate the effectiveness of our method, e.g., showing a 17\% improvement over previous methods in the video-hard setting of DMC-GB.
HiBid: A Cross-Channel Constrained Bidding System with Budget Allocation by Hierarchical Offline Deep Reinforcement Learning
Dec 29, 2023



Online display advertising platforms service numerous advertisers by providing real-time bidding (RTB) for the scale of billions of ad requests every day. The bidding strategy handles ad requests cross multiple channels to maximize the number of clicks under the set financial constraints, i.e., total budget and cost-per-click (CPC), etc. Different from existing works mainly focusing on single channel bidding, we explicitly consider cross-channel constrained bidding with budget allocation. Specifically, we propose a hierarchical offline deep reinforcement learning (DRL) framework called ``HiBid'', consisted of a high-level planner equipped with auxiliary loss for non-competitive budget allocation, and a data augmentation enhanced low-level executor for adaptive bidding strategy in response to allocated budgets. Additionally, a CPC-guided action selection mechanism is introduced to satisfy the cross-channel CPC constraint. Through extensive experiments on both the large-scale log data and online A/B testing, we confirm that HiBid outperforms six baselines in terms of the number of clicks, CPC satisfactory ratio, and return-on-investment (ROI). We also deploy HiBid on Meituan advertising platform to already service tens of thousands of advertisers every day.
Annotator: A Generic Active Learning Baseline for LiDAR Semantic Segmentation
Oct 31, 2023



Active learning, a label-efficient paradigm, empowers models to interactively query an oracle for labeling new data. In the realm of LiDAR semantic segmentation, the challenges stem from the sheer volume of point clouds, rendering annotation labor-intensive and cost-prohibitive. This paper presents Annotator, a general and efficient active learning baseline, in which a voxel-centric online selection strategy is tailored to efficiently probe and annotate the salient and exemplar voxel girds within each LiDAR scan, even under distribution shift. Concretely, we first execute an in-depth analysis of several common selection strategies such as Random, Entropy, Margin, and then develop voxel confusion degree (VCD) to exploit the local topology relations and structures of point clouds. Annotator excels in diverse settings, with a particular focus on active learning (AL), active source-free domain adaptation (ASFDA), and active domain adaptation (ADA). It consistently delivers exceptional performance across LiDAR semantic segmentation benchmarks, spanning both simulation-to-real and real-to-real scenarios. Surprisingly, Annotator exhibits remarkable efficiency, requiring significantly fewer annotations, e.g., just labeling five voxels per scan in the SynLiDAR-to-SemanticKITTI task. This results in impressive performance, achieving 87.8% fully-supervised performance under AL, 88.5% under ASFDA, and 94.4% under ADA. We envision that Annotator will offer a simple, general, and efficient solution for label-efficient 3D applications. Project page: https://binhuixie.github.io/annotator-web