 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOff-Policy Primal-Dual Safe Reinforcement Learning
Jan 26, 2024



Primal-dual safe RL methods commonly perform iterations between the primal update of the policy and the dual update of the Lagrange Multiplier. Such a training paradigm is highly susceptible to the error in cumulative cost estimation since this estimation serves as the key bond connecting the primal and dual update processes. We show that this problem causes significant underestimation of cost when using off-policy methods, leading to the failure to satisfy the safety constraint. To address this issue, we propose \textit{conservative policy optimization}, which learns a policy in a constraint-satisfying area by considering the uncertainty in cost estimation. This improves constraint satisfaction but also potentially hinders reward maximization. We then introduce \textit{local policy convexification} to help eliminate such suboptimality by gradually reducing the estimation uncertainty. We provide theoretical interpretations of the joint coupling effect of these two ingredients and further verify them by extensive experiments. Results on benchmark tasks show that our method not only achieves an asymptotic performance comparable to state-of-the-art on-policy methods while using much fewer samples, but also significantly reduces constraint violation during training. Our code is available at https://github.com/ZifanWu/CAL.
HiBid: A Cross-Channel Constrained Bidding System with Budget Allocation by Hierarchical Offline Deep Reinforcement Learning
Dec 29, 2023



Online display advertising platforms service numerous advertisers by providing real-time bidding (RTB) for the scale of billions of ad requests every day. The bidding strategy handles ad requests cross multiple channels to maximize the number of clicks under the set financial constraints, i.e., total budget and cost-per-click (CPC), etc. Different from existing works mainly focusing on single channel bidding, we explicitly consider cross-channel constrained bidding with budget allocation. Specifically, we propose a hierarchical offline deep reinforcement learning (DRL) framework called ``HiBid'', consisted of a high-level planner equipped with auxiliary loss for non-competitive budget allocation, and a data augmentation enhanced low-level executor for adaptive bidding strategy in response to allocated budgets. Additionally, a CPC-guided action selection mechanism is introduced to satisfy the cross-channel CPC constraint. Through extensive experiments on both the large-scale log data and online A/B testing, we confirm that HiBid outperforms six baselines in terms of the number of clicks, CPC satisfactory ratio, and return-on-investment (ROI). We also deploy HiBid on Meituan advertising platform to already service tens of thousands of advertisers every day.
Safe Offline Reinforcement Learning with Real-Time Budget Constraints
Jun 01, 2023


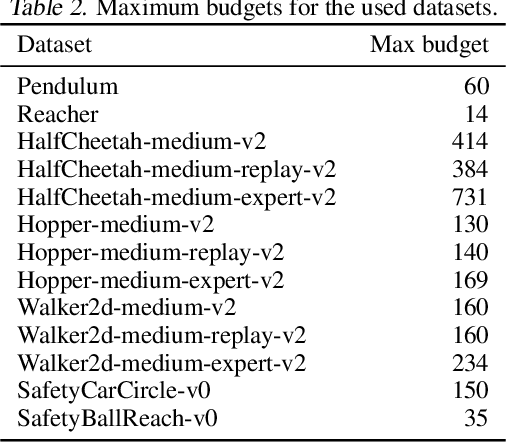
Aiming at promoting the safe real-world deployment of Reinforcement Learning (RL), research on safe RL has made significant progress in recent years. However, most existing works in the literature still focus on the online setting where risky violations of the safety budget are likely to be incurred during training. Besides, in many real-world applications, the learned policy is required to respond to dynamically determined safety budgets (i.e., constraint threshold) in real time. In this paper, we target at the above real-time budget constraint problem under the offline setting, and propose Trajectory-based REal-time Budget Inference (TREBI) as a novel solution that approaches this problem from the perspective of trajectory distribution. Theoretically, we prove an error bound of the estimation on the episodic reward and cost under the offline setting and thus provide a performance guarantee for TREBI. Empirical results on a wide range of simulation tasks and a real-world large-scale advertising application demonstrate the capability of TREBI in solving real-time budget constraint problems under offline settings.