 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactorPortrait: Controllable Portrait Animation via Disentangled Expression, Pose, and Viewpoint
Dec 12, 2025We introduce FactorPortrait, a video diffusion method for controllable portrait animation that enables lifelike synthesis from disentangled control signals of facial expressions, head movement, and camera viewpoints. Given a single portrait image, a driving video, and camera trajectories, our method animates the portrait by transferring facial expressions and head movements from the driving video while simultaneously enabling novel view synthesis from arbitrary viewpoints. We utilize a pre-trained image encoder to extract facial expression latents from the driving video as control signals for animation generation. Such latents implicitly capture nuanced facial expression dynamics with identity and pose information disentangled, and they are efficiently injected into the video diffusion transformer through our proposed expression controller. For camera and head pose control, we employ Plücker ray maps and normal maps rendered from 3D body mesh tracking. To train our model, we curate a large-scale synthetic dataset containing diverse combinations of camera viewpoints, head poses, and facial expression dynamics. Extensive experiments demonstrate that our method outperforms existing approaches in realism, expressiveness, control accuracy, and view consistency.
FRESA:Feedforward Reconstruction of Personalized Skinned Avatars from Few Images
Mar 24, 2025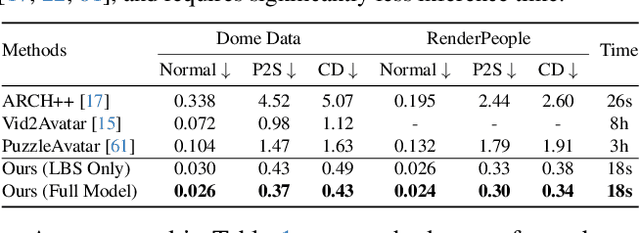
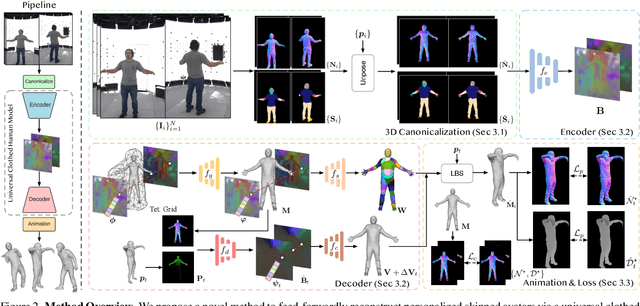
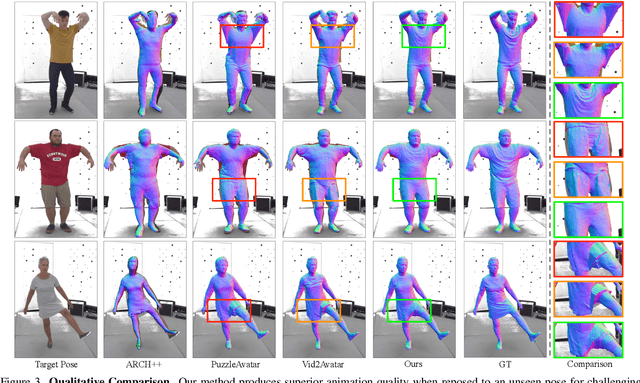
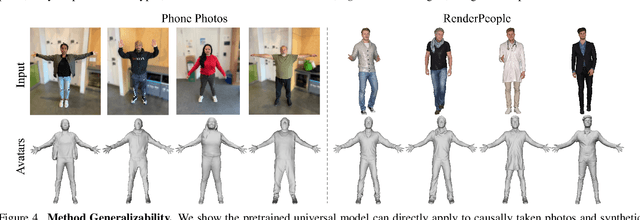
We present a novel method for reconstructing personalized 3D human avatars with realistic animation from only a few images. Due to the large variations in body shapes, poses, and cloth types, existing methods mostly require hours of per-subject optimization during inference, which limits their practical applications. In contrast, we learn a universal prior from over a thousand clothed humans to achieve instant feedforward generation and zero-shot generalization. Specifically, instead of rigging the avatar with shared skinning weights, we jointly infer personalized avatar shape, skinning weights, and pose-dependent deformations, which effectively improves overall geometric fidelity and reduces deformation artifacts. Moreover, to normalize pose variations and resolve coupled ambiguity between canonical shapes and skinning weights, we design a 3D canonicalization process to produce pixel-aligned initial conditions, which helps to reconstruct fine-grained geometric details. We then propose a multi-frame feature aggregation to robustly reduce artifacts introduced in canonicalization and fuse a plausible avatar preserving person-specific identities. Finally, we train the model in an end-to-end framework on a large-scale capture dataset, which contains diverse human subjects paired with high-quality 3D scans. Extensive experiments show that our method generates more authentic reconstruction and animation than state-of-the-arts, and can be directly generalized to inputs from casually taken phone photos. Project page and code is available at https://github.com/rongakowang/FRESA.
ACL-QL: Adaptive Conservative Level in Q-Learning for Offline Reinforcement Learning
Dec 22, 2024Offline Reinforcement Learning (RL), which operates solely on static datasets without further interactions with the environment, provides an appealing alternative to learning a safe and promising control policy. The prevailing methods typically learn a conservative policy to mitigate the problem of Q-value overestimation, but it is prone to overdo it, leading to an overly conservative policy. Moreover, they optimize all samples equally with fixed constraints, lacking the nuanced ability to control conservative levels in a fine-grained manner. Consequently, this limitation results in a performance decline. To address the above two challenges in a united way, we propose a framework, Adaptive Conservative Level in Q-Learning (ACL-QL), which limits the Q-values in a mild range and enables adaptive control on the conservative level over each state-action pair, i.e., lifting the Q-values more for good transitions and less for bad transitions. We theoretically analyze the conditions under which the conservative level of the learned Q-function can be limited in a mild range and how to optimize each transition adaptively. Motivated by the theoretical analysis, we propose a novel algorithm, ACL-QL, which uses two learnable adaptive weight functions to control the conservative level over each transition. Subsequently, we design a monotonicity loss and surrogate losses to train the adaptive weight functions, Q-function, and policy network alternatively. We evaluate ACL-QL on the commonly used D4RL benchmark and conduct extensive ablation studies to illustrate the effectiveness and state-of-the-art performance compared to existing offline DRL baselines.
Cross-Modal Reasoning with Event Correlation for Video Question Answering
Dec 20, 2023Video Question Answering (VideoQA) is a very attractive and challenging research direction aiming to understand complex semantics of heterogeneous data from two domains, i.e., the spatio-temporal video content and the word sequence in question. Although various attention mechanisms have been utilized to manage contextualized representations by modeling intra- and inter-modal relationships of the two modalities, one limitation of the predominant VideoQA methods is the lack of reasoning with event correlation, that is, sensing and analyzing relationships among abundant and informative events contained in the video. In this paper, we introduce the dense caption modality as a new auxiliary and distill event-correlated information from it to infer the correct answer. To this end, we propose a novel end-to-end trainable model, Event-Correlated Graph Neural Networks (EC-GNNs), to perform cross-modal reasoning over information from the three modalities (i.e., caption, video, and question). Besides the exploitation of a brand new modality, we employ cross-modal reasoning modules for explicitly modeling inter-modal relationships and aggregating relevant information across different modalities, and we propose a question-guided self-adaptive multi-modal fusion module to collect the question-oriented and event-correlated evidence through multi-step reasoning. We evaluate our model on two widely-used benchmark datasets and conduct an ablation study to justify the effectiveness of each proposed component.
Multi-Clue Reasoning with Memory Augmentation for Knowledge-based Visual Question Answering
Dec 20, 2023



Visual Question Answering (VQA) has emerged as one of the most challenging tasks in artificial intelligence due to its multi-modal nature. However, most existing VQA methods are incapable of handling Knowledge-based Visual Question Answering (KB-VQA), which requires external knowledge beyond visible contents to answer questions about a given image. To address this issue, we propose a novel framework that endows the model with capabilities of answering more general questions, and achieves a better exploitation of external knowledge through generating Multiple Clues for Reasoning with Memory Neural Networks (MCR-MemNN). Specifically, a well-defined detector is adopted to predict image-question related relation phrases, each of which delivers two complementary clues to retrieve the supporting facts from external knowledge base (KB), which are further encoded into a continuous embedding space using a content-addressable memory. Afterwards, mutual interactions between visual-semantic representation and the supporting facts stored in memory are captured to distill the most relevant information in three modalities (i.e., image, question, and KB). Finally, the optimal answer is predicted by choosing the supporting fact with the highest score. We conduct extensive experiments on two widely-used benchmarks. The experimental results well justify the effectiveness of MCR-MemNN, as well as its superiority over other KB-VQA methods.
Human Pose Transfer with Disentangled Feature Consistency
Aug 06, 2021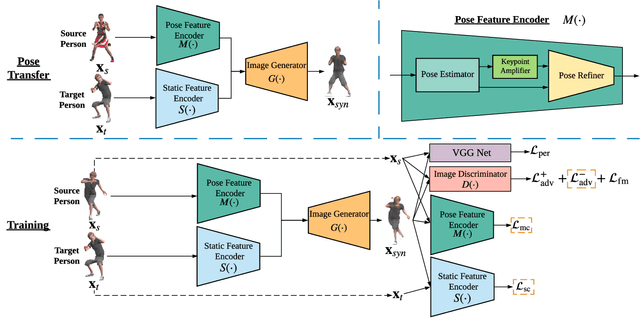



Deep generative models have made great progress in synthesizing images with arbitrary human poses and transferring poses of one person to others. However, most existing approaches explicitly leverage the pose information extracted from the source images as a conditional input for the generative networks. Meanwhile, they usually focus on the visual fidelity of the synthesized images but neglect the inherent consistency, which further confines their performance of pose transfer. To alleviate the current limitations and improve the quality of the synthesized images, we propose a pose transfer network with Disentangled Feature Consistency (DFC-Net) to facilitate human pose transfer. Given a pair of images containing the source and target person, DFC-Net extracts pose and static information from the source and target respectively, then synthesizes an image of the target person with the desired pose from the source. Moreover, DFC-Net leverages disentangled feature consistency losses in the adversarial training to strengthen the transfer coherence and integrates the keypoint amplifier to enhance the pose feature extraction. Additionally, an unpaired support dataset Mixamo-Sup providing more extra pose information has been further utilized during the training to improve the generality and robustness of DFC-Net. Extensive experimental results on Mixamo-Pose and EDN-10k have demonstrated DFC-Net achieves state-of-the-art performance on pose transfer.
Adversarial Meta-Learning
Jun 08, 2018
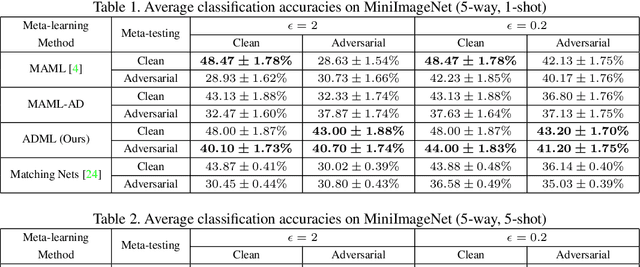
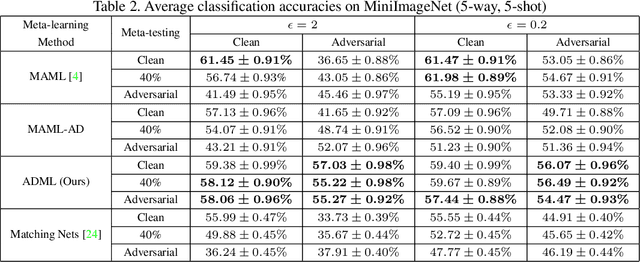
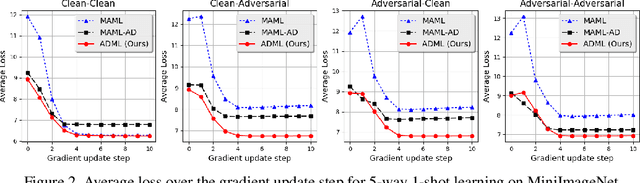
Meta-learning enables a model to learn from very limited data to undertake a new task. In this paper, we study the general meta-learning with adversarial samples. We present a meta-learning algorithm, ADML (ADversarial Meta-Learner), which leverages clean and adversarial samples to optimize the initialization of a learning model in an adversarial manner. ADML leads to the following desirable properties: 1) it turns out to be very effective even in the cases with only clean samples; 2) it is model-agnostic, i.e., it is compatible with any learning model that can be trained with gradient descent; and most importantly, 3) it is robust to adversarial samples, i.e., unlike other meta-learning methods, it only leads to a minor performance degradation when there are adversarial samples. We show via extensive experiments that ADML delivers the state-of-the-art performance on two widely-used image datasets, MiniImageNet and CIFAR100, in terms of both accuracy and robustness.