 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboAug: One Annotation to Hundreds of Scenes via Region-Contrastive Data Augmentation for Robotic Manipulation
Feb 15, 2026Enhancing the generalization capability of robotic learning to enable robots to operate effectively in diverse, unseen scenes is a fundamental and challenging problem. Existing approaches often depend on pretraining with large-scale data collection, which is labor-intensive and time-consuming, or on semantic data augmentation techniques that necessitate an impractical assumption of flawless upstream object detection in real-world scenarios. In this work, we propose RoboAug, a novel generative data augmentation framework that significantly minimizes the reliance on large-scale pretraining and the perfect visual recognition assumption by requiring only the bounding box annotation of a single image during training. Leveraging this minimal information, RoboAug employs pre-trained generative models for precise semantic data augmentation and integrates a plug-and-play region-contrastive loss to help models focus on task-relevant regions, thereby improving generalization and boosting task success rates. We conduct extensive real-world experiments on three robots, namely UR-5e, AgileX, and Tien Kung 2.0, spanning over 35k rollouts. Empirical results demonstrate that RoboAug significantly outperforms state-of-the-art data augmentation baselines. Specifically, when evaluating generalization capabilities in unseen scenes featuring diverse combinations of backgrounds, distractors, and lighting conditions, our method achieves substantial gains over the baseline without augmentation. The success rates increase from 0.09 to 0.47 on UR-5e, from 0.16 to 0.60 on AgileX, and from 0.19 to 0.67 on Tien Kung 2.0. These results highlight the superior generalization and effectiveness of RoboAug in real-world manipulation tasks. Our project is available at https://x-roboaug.github.io/.
Real-world Reinforcement Learning from Suboptimal Interventions
Dec 30, 2025Real-world reinforcement learning (RL) offers a promising approach to training precise and dexterous robotic manipulation policies in an online manner, enabling robots to learn from their own experience while gradually reducing human labor. However, prior real-world RL methods often assume that human interventions are optimal across the entire state space, overlooking the fact that even expert operators cannot consistently provide optimal actions in all states or completely avoid mistakes. Indiscriminately mixing intervention data with robot-collected data inherits the sample inefficiency of RL, while purely imitating intervention data can ultimately degrade the final performance achievable by RL. The question of how to leverage potentially suboptimal and noisy human interventions to accelerate learning without being constrained by them thus remains open. To address this challenge, we propose SiLRI, a state-wise Lagrangian reinforcement learning algorithm for real-world robot manipulation tasks. Specifically, we formulate the online manipulation problem as a constrained RL optimization, where the constraint bound at each state is determined by the uncertainty of human interventions. We then introduce a state-wise Lagrange multiplier and solve the problem via a min-max optimization, jointly optimizing the policy and the Lagrange multiplier to reach a saddle point. Built upon a human-as-copilot teleoperation system, our algorithm is evaluated through real-world experiments on diverse manipulation tasks. Experimental results show that SiLRI effectively exploits human suboptimal interventions, reducing the time required to reach a 90% success rate by at least 50% compared with the state-of-the-art RL method HIL-SERL, and achieving a 100% success rate on long-horizon manipulation tasks where other RL methods struggle to succeed. Project website: https://silri-rl.github.io/.
ArtVIP: Articulated Digital Assets of Visual Realism, Modular Interaction, and Physical Fidelity for Robot Learning
Jun 06, 2025Robot learning increasingly relies on simulation to advance complex ability such as dexterous manipulations and precise interactions, necessitating high-quality digital assets to bridge the sim-to-real gap. However, existing open-source articulated-object datasets for simulation are limited by insufficient visual realism and low physical fidelity, which hinder their utility for training models mastering robotic tasks in real world. To address these challenges, we introduce ArtVIP, a comprehensive open-source dataset comprising high-quality digital-twin articulated objects, accompanied by indoor-scene assets. Crafted by professional 3D modelers adhering to unified standards, ArtVIP ensures visual realism through precise geometric meshes and high-resolution textures, while physical fidelity is achieved via fine-tuned dynamic parameters. Meanwhile, the dataset pioneers embedded modular interaction behaviors within assets and pixel-level affordance annotations. Feature-map visualization and optical motion capture are employed to quantitatively demonstrate ArtVIP's visual and physical fidelity, with its applicability validated across imitation learning and reinforcement learning experiments. Provided in USD format with detailed production guidelines, ArtVIP is fully open-source, benefiting the research community and advancing robot learning research. Our project is at https://x-humanoid-artvip.github.io/ .
HACTS: a Human-As-Copilot Teleoperation System for Robot Learning
Mar 31, 2025Teleoperation is essential for autonomous robot learning, especially in manipulation tasks that require human demonstrations or corrections. However, most existing systems only offer unilateral robot control and lack the ability to synchronize the robot's status with the teleoperation hardware, preventing real-time, flexible intervention. In this work, we introduce HACTS (Human-As-Copilot Teleoperation System), a novel system that establishes bilateral, real-time joint synchronization between a robot arm and teleoperation hardware. This simple yet effective feedback mechanism, akin to a steering wheel in autonomous vehicles, enables the human copilot to intervene seamlessly while collecting action-correction data for future learning. Implemented using 3D-printed components and low-cost, off-the-shelf motors, HACTS is both accessible and scalable. Our experiments show that HACTS significantly enhances performance in imitation learning (IL) and reinforcement learning (RL) tasks, boosting IL recovery capabilities and data efficiency, and facilitating human-in-the-loop RL. HACTS paves the way for more effective and interactive human-robot collaboration and data-collection, advancing the capabilities of robot manipulation.
ACL-QL: Adaptive Conservative Level in Q-Learning for Offline Reinforcement Learning
Dec 22, 2024Offline Reinforcement Learning (RL), which operates solely on static datasets without further interactions with the environment, provides an appealing alternative to learning a safe and promising control policy. The prevailing methods typically learn a conservative policy to mitigate the problem of Q-value overestimation, but it is prone to overdo it, leading to an overly conservative policy. Moreover, they optimize all samples equally with fixed constraints, lacking the nuanced ability to control conservative levels in a fine-grained manner. Consequently, this limitation results in a performance decline. To address the above two challenges in a united way, we propose a framework, Adaptive Conservative Level in Q-Learning (ACL-QL), which limits the Q-values in a mild range and enables adaptive control on the conservative level over each state-action pair, i.e., lifting the Q-values more for good transitions and less for bad transitions. We theoretically analyze the conditions under which the conservative level of the learned Q-function can be limited in a mild range and how to optimize each transition adaptively. Motivated by the theoretical analysis, we propose a novel algorithm, ACL-QL, which uses two learnable adaptive weight functions to control the conservative level over each transition. Subsequently, we design a monotonicity loss and surrogate losses to train the adaptive weight functions, Q-function, and policy network alternatively. We evaluate ACL-QL on the commonly used D4RL benchmark and conduct extensive ablation studies to illustrate the effectiveness and state-of-the-art performance compared to existing offline DRL baselines.
RoboMIND: Benchmark on Multi-embodiment Intelligence Normative Data for Robot Manipulation
Dec 18, 2024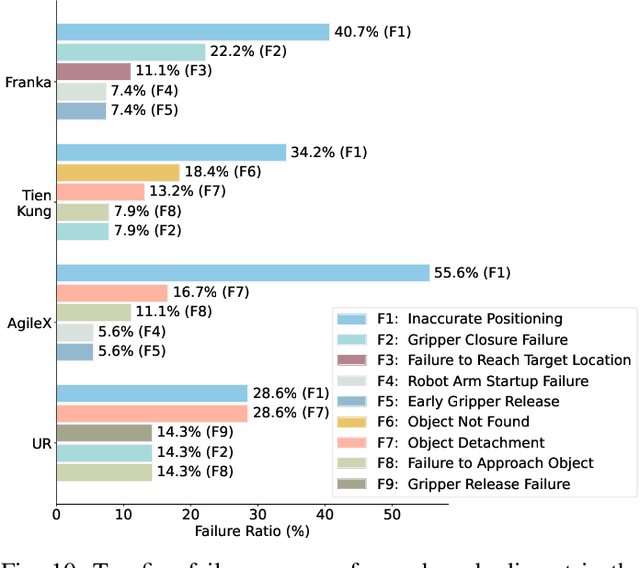
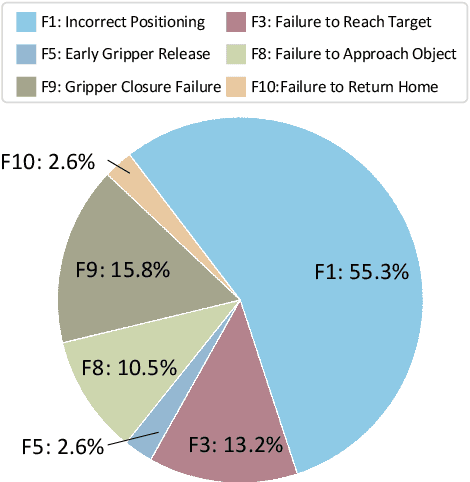
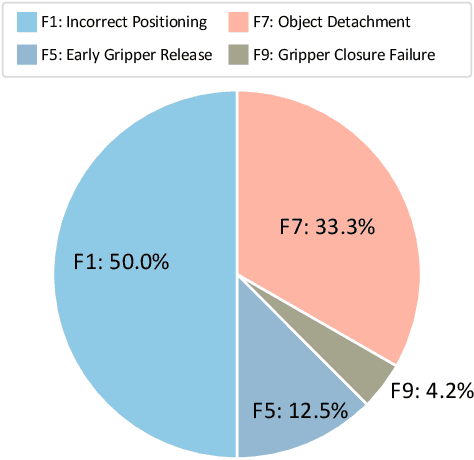
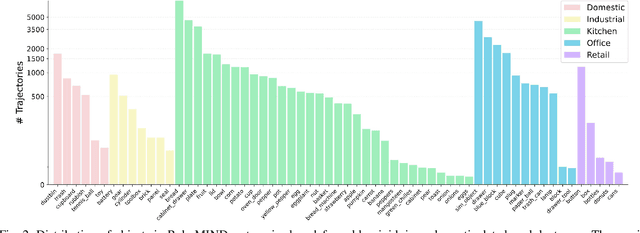
Developing robust and general-purpose robotic manipulation policies is a key goal in the field of robotics. To achieve effective generalization, it is essential to construct comprehensive datasets that encompass a large number of demonstration trajectories and diverse tasks. Unlike vision or language data that can be collected from the Internet, robotic datasets require detailed observations and manipulation actions, necessitating significant investment in hardware-software infrastructure and human labor. While existing works have focused on assembling various individual robot datasets, there remains a lack of a unified data collection standard and insufficient diversity in tasks, scenarios, and robot types. In this paper, we introduce RoboMIND (Multi-embodiment Intelligence Normative Data for Robot manipulation), featuring 55k real-world demonstration trajectories across 279 diverse tasks involving 61 different object classes. RoboMIND is collected through human teleoperation and encompasses comprehensive robotic-related information, including multi-view RGB-D images, proprioceptive robot state information, end effector details, and linguistic task descriptions. To ensure dataset consistency and reliability during policy learning, RoboMIND is built on a unified data collection platform and standardized protocol, covering four distinct robotic embodiments. We provide a thorough quantitative and qualitative analysis of RoboMIND across multiple dimensions, offering detailed insights into the diversity of our datasets. In our experiments, we conduct extensive real-world testing with four state-of-the-art imitation learning methods, demonstrating that training with RoboMIND data results in a high manipulation success rate and strong generalization. Our project is at https://x-humanoid-robomind.github.io/.
An Efficient Generalizable Framework for Visuomotor Policies via Control-aware Augmentation and Privilege-guided Distillation
Jan 17, 2024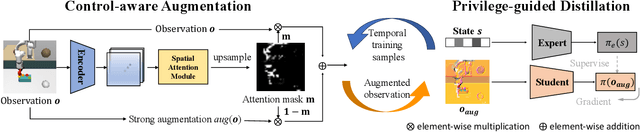
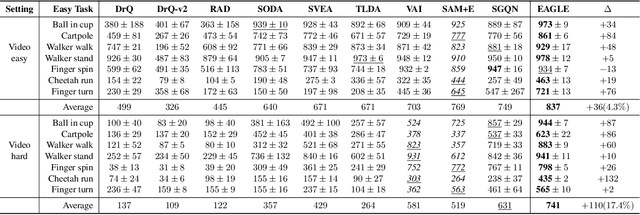
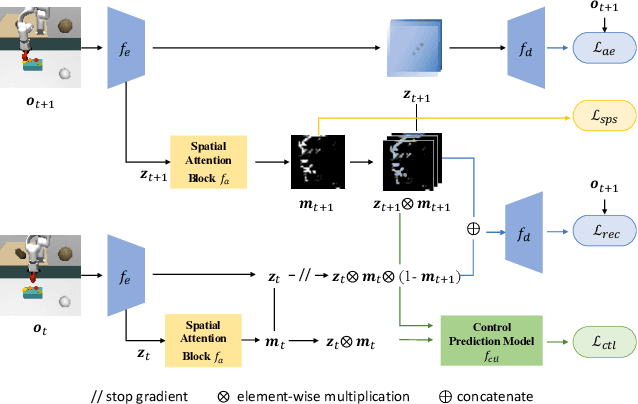
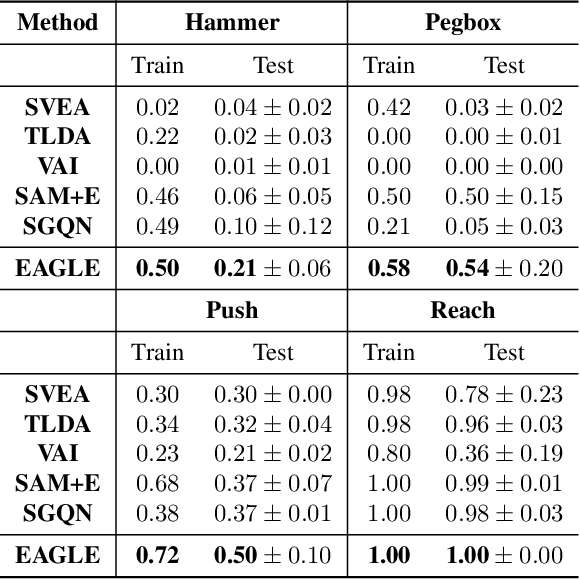
Visuomotor policies, which learn control mechanisms directly from high-dimensional visual observations, confront challenges in adapting to new environments with intricate visual variations. Data augmentation emerges as a promising method for bridging these generalization gaps by enriching data variety. However, straightforwardly augmenting the entire observation shall impose excessive burdens on policy learning and may even result in performance degradation. In this paper, we propose to improve the generalization ability of visuomotor policies as well as preserve training stability from two aspects: 1) We learn a control-aware mask through a self-supervised reconstruction task with three auxiliary losses and then apply strong augmentation only to those control-irrelevant regions based on the mask to reduce the generalization gaps. 2) To address training instability issues prevalent in visual reinforcement learning (RL), we distill the knowledge from a pretrained RL expert processing low-level environment states, to the student visuomotor policy. The policy is subsequently deployed to unseen environments without any further finetuning. We conducted comparison and ablation studies across various benchmarks: the DMControl Generalization Benchmark (DMC-GB), the enhanced Robot Manipulation Distraction Benchmark (RMDB), and a specialized long-horizontal drawer-opening robotic task. The extensive experimental results well demonstrate the effectiveness of our method, e.g., showing a 17\% improvement over previous methods in the video-hard setting of DMC-GB.
CADRE: A Cascade Deep Reinforcement Learning Framework for Vision-based Autonomous Urban Driving
Feb 17, 2022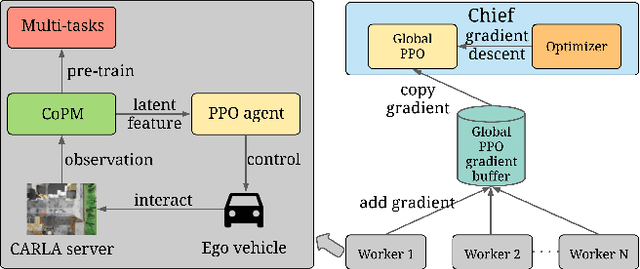
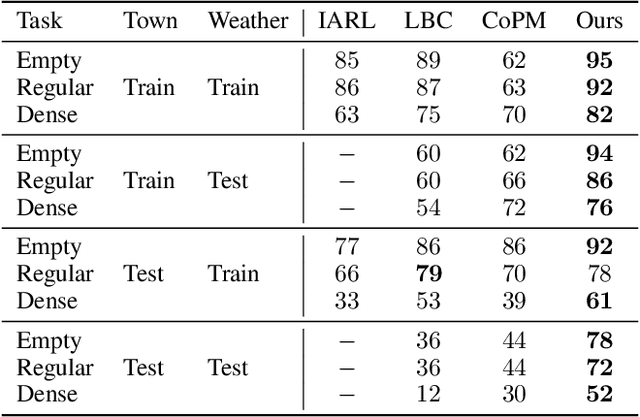
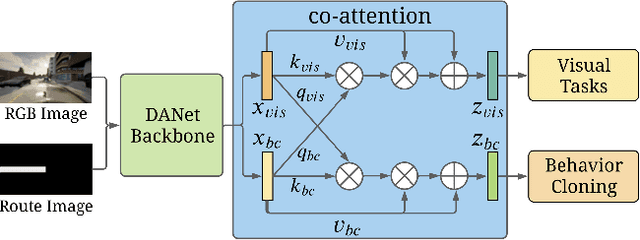
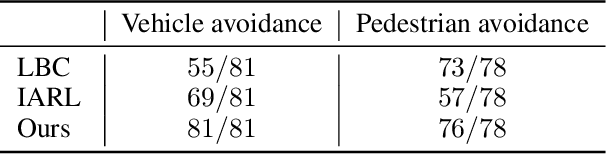
Vision-based autonomous urban driving in dense traffic is quite challenging due to the complicated urban environment and the dynamics of the driving behaviors. Widely-applied methods either heavily rely on hand-crafted rules or learn from limited human experience, which makes them hard to generalize to rare but critical scenarios. In this paper, we present a novel CAscade Deep REinforcement learning framework, CADRE, to achieve model-free vision-based autonomous urban driving. In CADRE, to derive representative latent features from raw observations, we first offline train a Co-attention Perception Module (CoPM) that leverages the co-attention mechanism to learn the inter-relationships between the visual and control information from a pre-collected driving dataset. Cascaded by the frozen CoPM, we then present an efficient distributed proximal policy optimization framework to online learn the driving policy under the guidance of particularly designed reward functions. We perform a comprehensive empirical study with the CARLA NoCrash benchmark as well as specific obstacle avoidance scenarios in autonomous urban driving tasks. The experimental results well justify the effectiveness of CADRE and its superiority over the state-of-the-art by a wide margin.