 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOVERLORD: Ultimate Scaling of DataLoader for Multi-Source Large Foundation Model Training
Apr 14, 2025Modern frameworks for training large foundation models (LFMs) employ data loaders in a data parallel paradigm. While this design offers implementation simplicity, it introduces two fundamental challenges. First, due to the quadratic computational complexity of the attention operator, the non-uniform sample distribution over data-parallel ranks leads to a significant workload imbalance among loaders, which degrades the training efficiency. This paradigm also impedes the implementation of data mixing algorithms (e.g., curriculum learning) over different datasets. Second, to acquire a broad range of capability, LFMs training ingests data from diverse sources, each with distinct file access states. Colocating massive datasets within loader instances can easily exceed local pod memory capacity. Additionally, heavy sources with higher transformation latency require larger worker pools, further exacerbating memory consumption. We present OVERLORD, an industrial-grade distributed data loading architecture with three innovations: (1) A centralized and declarative data plane, which facilitates elastic data orchestration strategy, such as long-short context, multimodal, and curriculum learning; (2) Disaggregated multisource preprocessing through role-specific actors, i.e., Source Loaders and Data Constructors, leveraging autoscaling for Source Loaders towards heterogeneous and evolving source preprocessing cost; (3) Shadow Loaders with differential checkpointing for uninterrupted fault recovery. Deployed on production clusters scaling to multi-thousand GPU, OVERLORD achieves: (1) 4.5x end-to-end training throughput improvement, (2) a minimum 3.6x reduction in CPU memory usage, with further improvements to be added in later experiments.
One-Shot Segmentation of Novel White Matter Tracts via Extensive Data Augmentation
Mar 13, 2023Deep learning based methods have achieved state-of-the-art performance for automated white matter (WM) tract segmentation. In these methods, the segmentation model needs to be trained with a large number of manually annotated scans, which can be accumulated throughout time. When novel WM tracts, i.e., tracts not included in the existing annotated WM tracts, are to be segmented, additional annotations of these novel WM tracts need to be collected. Since tract annotation is time-consuming and costly, it is desirable to make only a few annotations of novel WM tracts for training the segmentation model, and previous work has addressed this problem by transferring the knowledge learned for segmenting existing WM tracts to the segmentation of novel WM tracts. However, accurate segmentation of novel WM tracts can still be challenging in the one-shot setting, where only one scan is annotated for the novel WM tracts. In this work, we explore the problem of one-shot segmentation of novel WM tracts. Since in the one-shot setting the annotated training data is extremely scarce, based on the existing knowledge transfer framework, we propose to further perform extensive data augmentation for the single annotated scan, where synthetic annotated training data is produced. We have designed several different strategies that mask out regions in the single annotated scan for data augmentation. Our method was evaluated on public and in-house datasets. The experimental results show that our method improves the accuracy of one-shot segmentation of novel WM tracts.
CADRE: A Cascade Deep Reinforcement Learning Framework for Vision-based Autonomous Urban Driving
Feb 17, 2022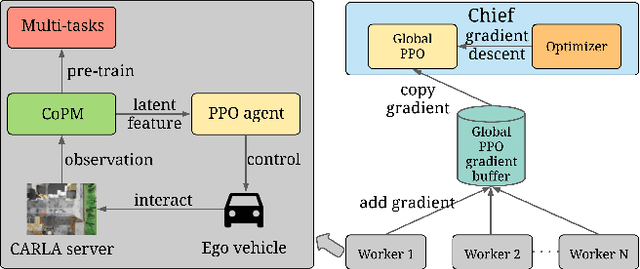
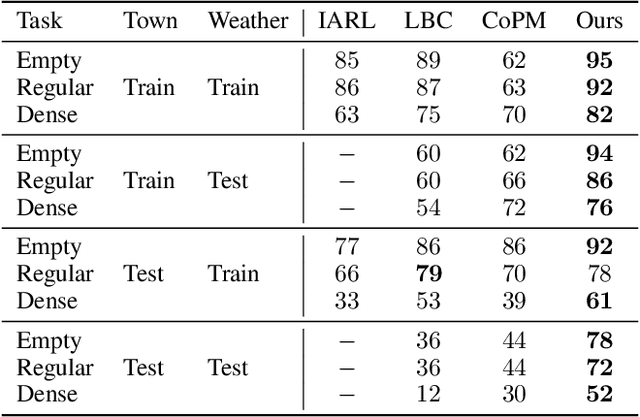
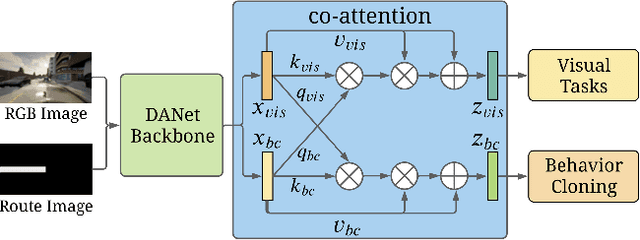
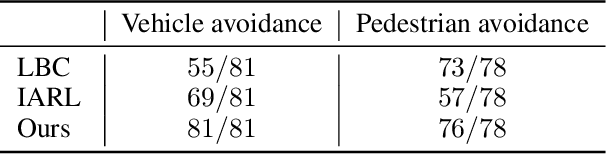
Vision-based autonomous urban driving in dense traffic is quite challenging due to the complicated urban environment and the dynamics of the driving behaviors. Widely-applied methods either heavily rely on hand-crafted rules or learn from limited human experience, which makes them hard to generalize to rare but critical scenarios. In this paper, we present a novel CAscade Deep REinforcement learning framework, CADRE, to achieve model-free vision-based autonomous urban driving. In CADRE, to derive representative latent features from raw observations, we first offline train a Co-attention Perception Module (CoPM) that leverages the co-attention mechanism to learn the inter-relationships between the visual and control information from a pre-collected driving dataset. Cascaded by the frozen CoPM, we then present an efficient distributed proximal policy optimization framework to online learn the driving policy under the guidance of particularly designed reward functions. We perform a comprehensive empirical study with the CARLA NoCrash benchmark as well as specific obstacle avoidance scenarios in autonomous urban driving tasks. The experimental results well justify the effectiveness of CADRE and its superiority over the state-of-the-art by a wide margin.
Knowledge Transfer for Few-shot Segmentation of Novel White Matter Tracts
Jun 01, 2021
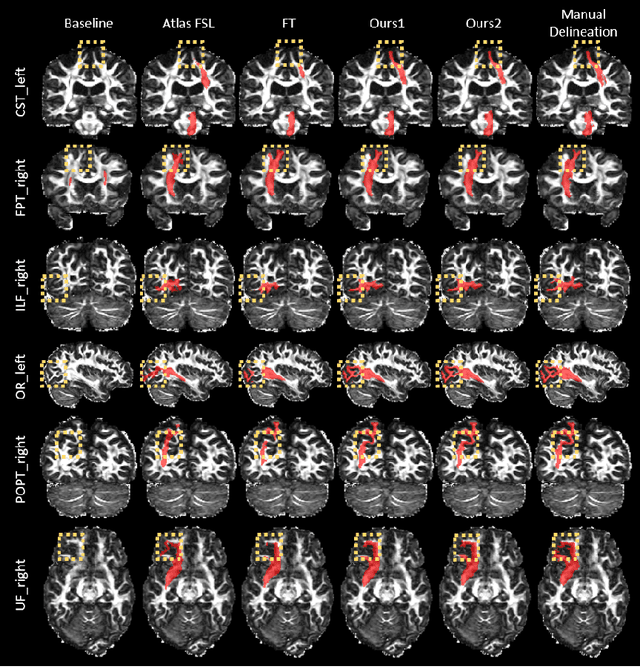
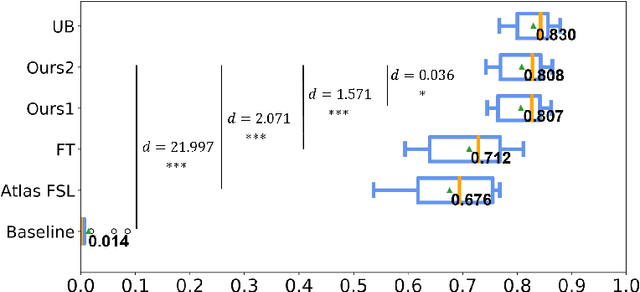
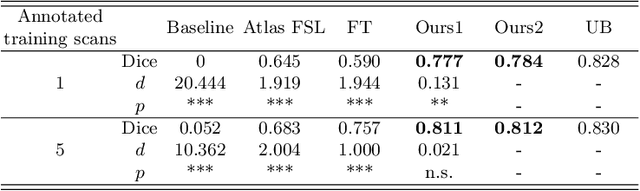
Convolutional neural networks (CNNs) have achieved stateof-the-art performance for white matter (WM) tract segmentation based on diffusion magnetic resonance imaging (dMRI). These CNNs require a large number of manual delineations of the WM tracts of interest for training, which are generally labor-intensive and costly. The expensive manual delineation can be a particular disadvantage when novel WM tracts, i.e., tracts that have not been included in existing manual delineations, are to be analyzed. To accurately segment novel WM tracts, it is desirable to transfer the knowledge learned about existing WM tracts, so that even with only a few delineations of the novel WM tracts, CNNs can learn adequately for the segmentation. In this paper, we explore the transfer of such knowledge to the segmentation of novel WM tracts in the few-shot setting. Although a classic fine-tuning strategy can be used for the purpose, the information in the last task-specific layer for segmenting existing WM tracts is completely discarded. We hypothesize that the weights of this last layer can bear valuable information for segmenting the novel WM tracts and thus completely discarding the information is not optimal. In particular, we assume that the novel WM tracts can correlate with existing WM tracts and the segmentation of novel WM tracts can be predicted with the logits of existing WM tracts. In this way, better initialization of the last layer than random initialization can be achieved for fine-tuning. Further, we show that a more adaptive use of the knowledge in the last layer for segmenting existing WM tracts can be conveniently achieved by simply inserting a warmup stage before classic fine-tuning. The proposed method was evaluated on a publicly available dMRI dataset, where we demonstrate the benefit of our method for few-shot segmentation of novel WM tracts.
BigDL: A Distributed Deep Learning Framework for Big Data
Jun 25, 2018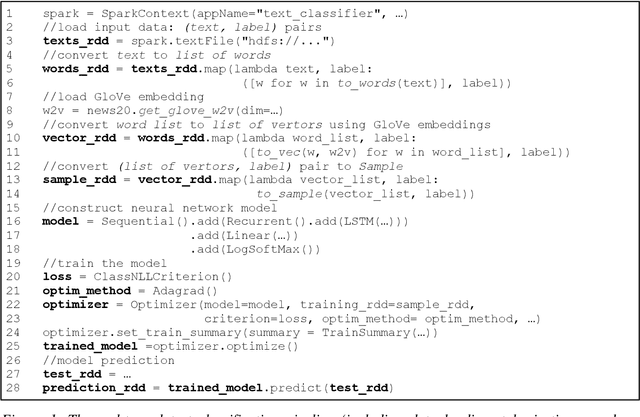
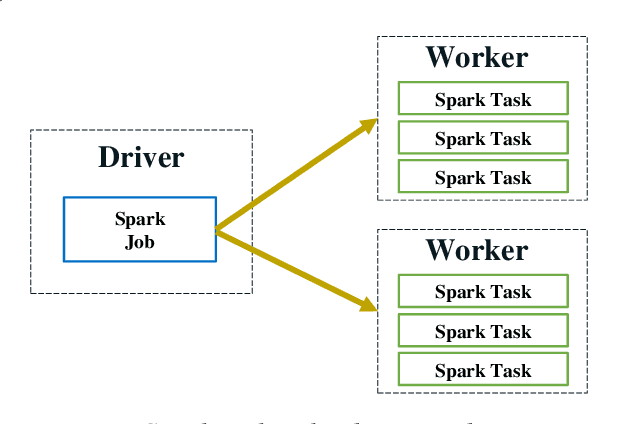

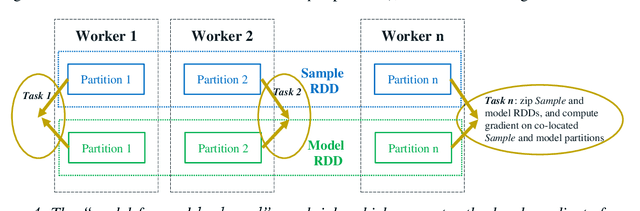
In this paper, we present BigDL, a distributed deep learning framework for Big Data platforms and workflows. It is implemented on top of Apache Spark, and allows users to write their deep learning applications as standard Spark programs (running directly on large-scale big data clusters in a distributed fashion). It provides an expressive, "data-analytics integrated" deep learning programming model, so that users can easily build the end-to-end analytics + AI pipelines under a unified programming paradigm; by implementing an AllReduce like operation using existing primitives in Spark (e.g., shuffle, broadcast, and in-memory data persistence), it also provides a highly efficient "parameter server" style architecture, so as to achieve highly scalable, data-parallel distributed training. Since its initial open source release, BigDL users have built many analytics and deep learning applications (e.g., object detection, sequence-to-sequence generation, visual similarity, neural recommendations, fraud detection, etc.) on Spark.
A Scalable and Adaptable Multiple-Place Foraging Algorithm for Ant-Inspired Robot Swarms
Dec 01, 2016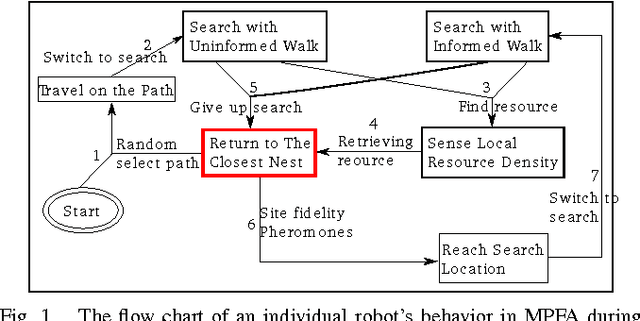
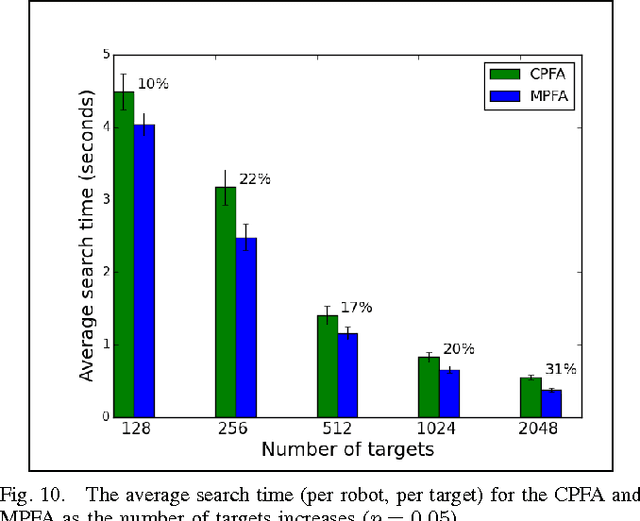
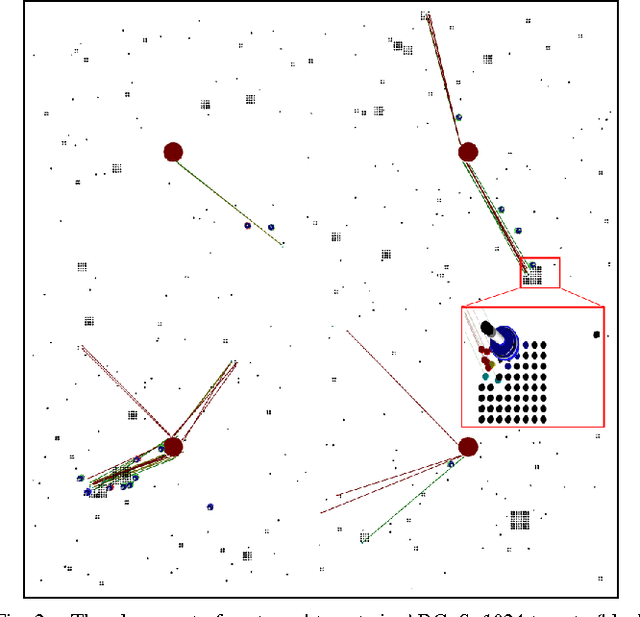
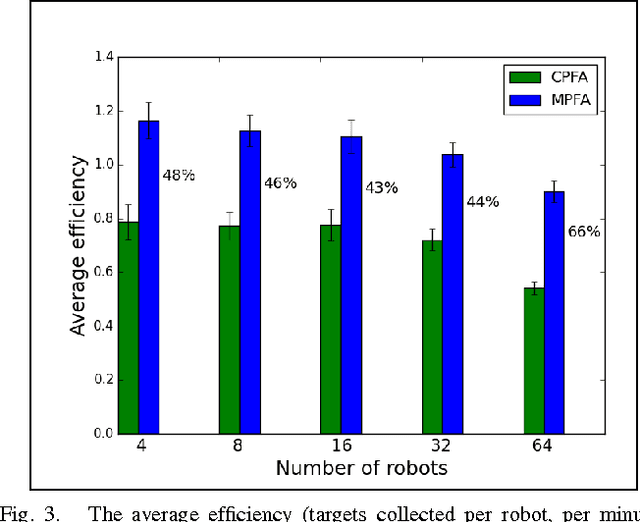
Individual robots are not effective at exploring large unmapped areas. An alternate approach is to use a swarm of simple robots that work together, rather than a single highly capable robot. The central-place foraging algorithm (CPFA) is effective for coordinating robot swarm search and collection tasks. Robots start at a centrally placed location (nest), explore potential targets in the area without global localization or central control, and return the targets to the nest. The scalability of the CPFA is limited because large numbers of robots produce more inter-robot collisions and large search areas result in substantial travel costs. We address these problems with the multiple-place foraging algorithm (MPFA), which uses multiple nests distributed throughout the search area. Robots start from a randomly assigned home nest but return to the closest nest with found targets. We simulate the foraging behavior of robot swarms in the robot simulator ARGoS and employ a genetic algorithm to discover different optimized foraging strategies as swarm sizes and the number of targets are scaled up. In our experiments, the MPFA always produces higher foraging rates, fewer collisions, and lower travel and search time compared to the CPFA for the partially clustered targets distribution. The main contribution of this paper is that we systematically quantify the advantages of the MPFA (reduced travel time and collisions), the potential disadvantages (less communication among robots), and the ability of a genetic algorithm to tune MPFA parameters to mitigate search inefficiency due to less communication.