 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
Seed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
OVERLORD: Ultimate Scaling of DataLoader for Multi-Source Large Foundation Model Training
Apr 14, 2025Modern frameworks for training large foundation models (LFMs) employ data loaders in a data parallel paradigm. While this design offers implementation simplicity, it introduces two fundamental challenges. First, due to the quadratic computational complexity of the attention operator, the non-uniform sample distribution over data-parallel ranks leads to a significant workload imbalance among loaders, which degrades the training efficiency. This paradigm also impedes the implementation of data mixing algorithms (e.g., curriculum learning) over different datasets. Second, to acquire a broad range of capability, LFMs training ingests data from diverse sources, each with distinct file access states. Colocating massive datasets within loader instances can easily exceed local pod memory capacity. Additionally, heavy sources with higher transformation latency require larger worker pools, further exacerbating memory consumption. We present OVERLORD, an industrial-grade distributed data loading architecture with three innovations: (1) A centralized and declarative data plane, which facilitates elastic data orchestration strategy, such as long-short context, multimodal, and curriculum learning; (2) Disaggregated multisource preprocessing through role-specific actors, i.e., Source Loaders and Data Constructors, leveraging autoscaling for Source Loaders towards heterogeneous and evolving source preprocessing cost; (3) Shadow Loaders with differential checkpointing for uninterrupted fault recovery. Deployed on production clusters scaling to multi-thousand GPU, OVERLORD achieves: (1) 4.5x end-to-end training throughput improvement, (2) a minimum 3.6x reduction in CPU memory usage, with further improvements to be added in later experiments.
Optimus: Accelerating Large-Scale Multi-Modal LLM Training by Bubble Exploitation
Aug 07, 2024



Multimodal large language models (MLLMs) have extended the success of large language models (LLMs) to multiple data types, such as image, text and audio, achieving significant performance in various domains, including multimodal translation, visual question answering and content generation. Nonetheless, existing systems are inefficient to train MLLMs due to substantial GPU bubbles caused by the heterogeneous modality models and complex data dependencies in 3D parallelism. This paper proposes Optimus, a distributed MLLM training system that reduces end-to-end MLLM training time. Optimus is based on our principled analysis that scheduling the encoder computation within the LLM bubbles can reduce bubbles in MLLM training. To make scheduling encoder computation possible for all GPUs, Optimus searches the separate parallel plans for encoder and LLM, and adopts a bubble scheduling algorithm to enable exploiting LLM bubbles without breaking the original data dependencies in the MLLM model architecture. We further decompose encoder layer computation into a series of kernels, and analyze the common bubble pattern of 3D parallelism to carefully optimize the sub-millisecond bubble scheduling, minimizing the overall training time. Our experiments in a production cluster show that Optimus accelerates MLLM training by 20.5%-21.3% with ViT-22B and GPT-175B model over 3072 GPUs compared to baselines.
MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs
Feb 23, 2024



We present the design, implementation and engineering experience in building and deploying MegaScale, a production system for training large language models (LLMs) at the scale of more than 10,000 GPUs. Training LLMs at this scale brings unprecedented challenges to training efficiency and stability. We take a full-stack approach that co-designs the algorithmic and system components across model block and optimizer design, computation and communication overlapping, operator optimization, data pipeline, and network performance tuning. Maintaining high efficiency throughout the training process (i.e., stability) is an important consideration in production given the long extent of LLM training jobs. Many hard stability issues only emerge at large scale, and in-depth observability is the key to address them. We develop a set of diagnosis tools to monitor system components and events deep in the stack, identify root causes, and derive effective techniques to achieve fault tolerance and mitigate stragglers. MegaScale achieves 55.2% Model FLOPs Utilization (MFU) when training a 175B LLM model on 12,288 GPUs, improving the MFU by 1.34x compared to Megatron-LM. We share our operational experience in identifying and fixing failures and stragglers. We hope by articulating the problems and sharing our experience from a systems perspective, this work can inspire future LLM systems research.
BGL: GPU-Efficient GNN Training by Optimizing Graph Data I/O and Preprocessing
Dec 16, 2021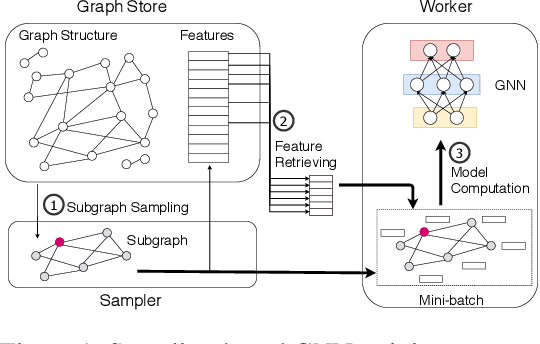
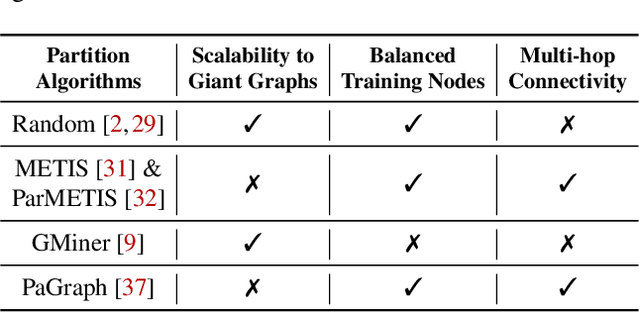
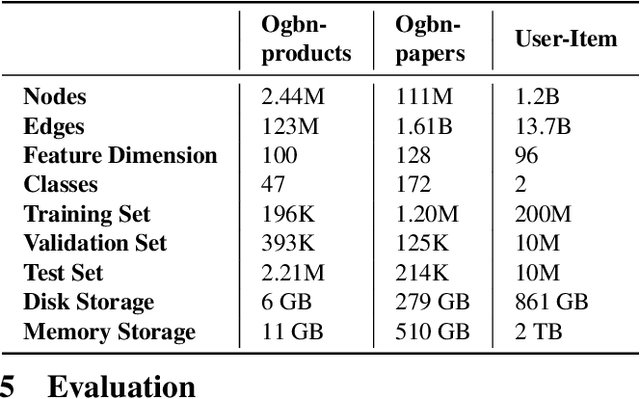
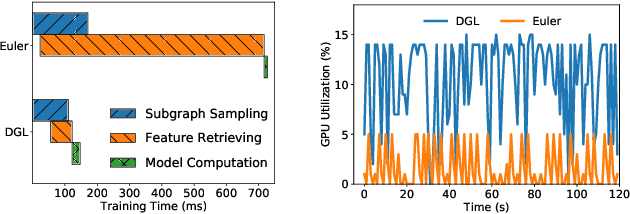
Graph neural networks (GNNs) have extended the success of deep neural networks (DNNs) to non-Euclidean graph data, achieving ground-breaking performance on various tasks such as node classification and graph property prediction. Nonetheless, existing systems are inefficient to train large graphs with billions of nodes and edges with GPUs. The main bottlenecks are the process of preparing data for GPUs - subgraph sampling and feature retrieving. This paper proposes BGL, a distributed GNN training system designed to address the bottlenecks with a few key ideas. First, we propose a dynamic cache engine to minimize feature retrieving traffic. By a co-design of caching policy and the order of sampling, we find a sweet spot of low overhead and high cache hit ratio. Second, we improve the graph partition algorithm to reduce cross-partition communication during subgraph sampling. Finally, careful resource isolation reduces contention between different data preprocessing stages. Extensive experiments on various GNN models and large graph datasets show that BGL significantly outperforms existing GNN training systems by 20.68x on average.
DL2: A Deep Learning-driven Scheduler for Deep Learning Clusters
Sep 13, 2019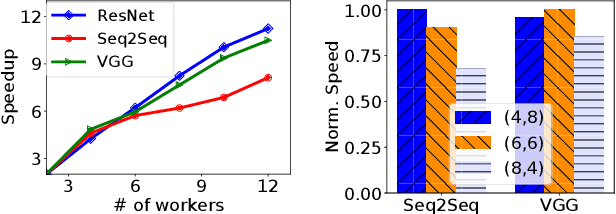
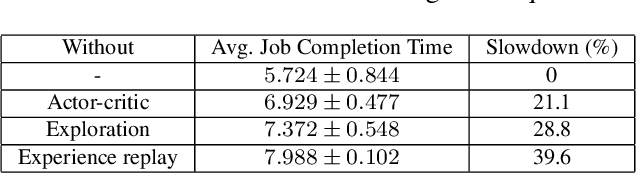
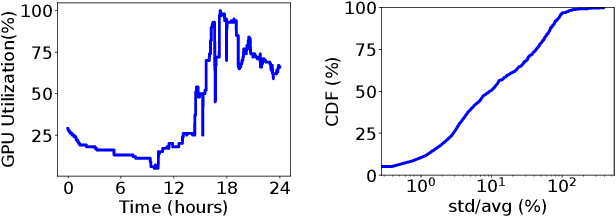
More and more companies have deployed machine learning (ML) clusters, where deep learning (DL) models are trained for providing various AI-driven services. Efficient resource scheduling is essential for maximal utilization of expensive DL clusters. Existing cluster schedulers either are agnostic to ML workload characteristics, or use scheduling heuristics based on operators' understanding of particular ML framework and workload, which are less efficient or not general enough. In this paper, we show that DL techniques can be adopted to design a generic and efficient scheduler. DL2 is a DL-driven scheduler for DL clusters, targeting global training job expedition by dynamically resizing resources allocated to jobs. DL2 advocates a joint supervised learning and reinforcement learning approach: a neural network is warmed up via offline supervised learning based on job traces produced by the existing cluster scheduler; then the neural network is plugged into the live DL cluster, fine-tuned by reinforcement learning carried out throughout the training progress of the DL jobs, and used for deciding job resource allocation in an online fashion. By applying past decisions made by the existing cluster scheduler in the preparatory supervised learning phase, our approach enables a smooth transition from existing scheduler, and renders a high-quality scheduler in minimizing average training completion time. We implement DL2 on Kubernetes and enable dynamic resource scaling in DL jobs on MXNet. Extensive evaluation shows that DL2 outperforms fairness scheduler (i.e., DRF) by 44.1% and expert heuristic scheduler (i.e., Optimus) by 17.5% in terms of average job completion time.