 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDL2: A Deep Learning-driven Scheduler for Deep Learning Clusters
Paper and Code
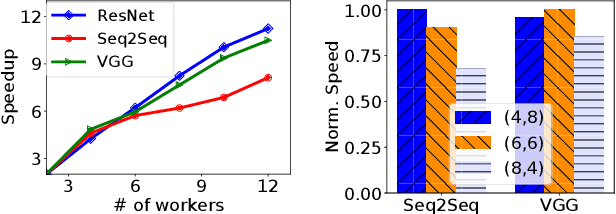
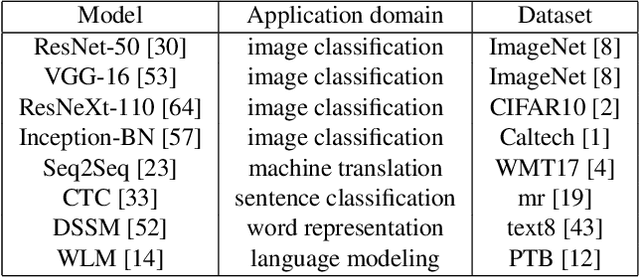
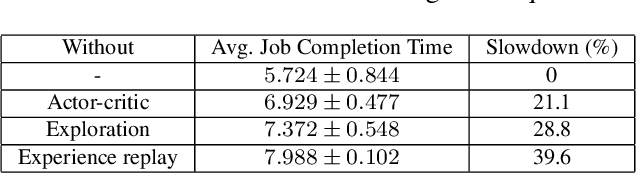
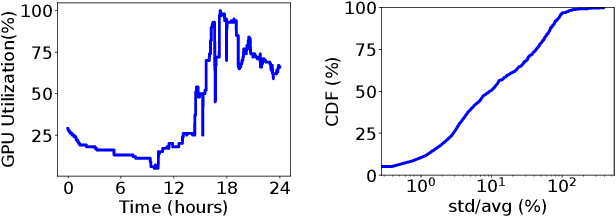
More and more companies have deployed machine learning (ML) clusters, where deep learning (DL) models are trained for providing various AI-driven services. Efficient resource scheduling is essential for maximal utilization of expensive DL clusters. Existing cluster schedulers either are agnostic to ML workload characteristics, or use scheduling heuristics based on operators' understanding of particular ML framework and workload, which are less efficient or not general enough. In this paper, we show that DL techniques can be adopted to design a generic and efficient scheduler. DL2 is a DL-driven scheduler for DL clusters, targeting global training job expedition by dynamically resizing resources allocated to jobs. DL2 advocates a joint supervised learning and reinforcement learning approach: a neural network is warmed up via offline supervised learning based on job traces produced by the existing cluster scheduler; then the neural network is plugged into the live DL cluster, fine-tuned by reinforcement learning carried out throughout the training progress of the DL jobs, and used for deciding job resource allocation in an online fashion. By applying past decisions made by the existing cluster scheduler in the preparatory supervised learning phase, our approach enables a smooth transition from existing scheduler, and renders a high-quality scheduler in minimizing average training completion time. We implement DL2 on Kubernetes and enable dynamic resource scaling in DL jobs on MXNet. Extensive evaluation shows that DL2 outperforms fairness scheduler (i.e., DRF) by 44.1% and expert heuristic scheduler (i.e., Optimus) by 17.5% in terms of average job completion time.