 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Preserving Multi-Center Differential Protein Abundance Analysis with FedProt
Jul 21, 2024



Quantitative mass spectrometry has revolutionized proteomics by enabling simultaneous quantification of thousands of proteins. Pooling patient-derived data from multiple institutions enhances statistical power but raises significant privacy concerns. Here we introduce FedProt, the first privacy-preserving tool for collaborative differential protein abundance analysis of distributed data, which utilizes federated learning and additive secret sharing. In the absence of a multicenter patient-derived dataset for evaluation, we created two, one at five centers from LFQ E.coli experiments and one at three centers from TMT human serum. Evaluations using these datasets confirm that FedProt achieves accuracy equivalent to DEqMS applied to pooled data, with completely negligible absolute differences no greater than $\text{$4 \times 10^{-12}$}$. In contrast, -log10(p-values) computed by the most accurate meta-analysis methods diverged from the centralized analysis results by up to 25-27. FedProt is available as a web tool with detailed documentation as a FeatureCloud App.
Inference Performance Optimization for Large Language Models on CPUs
Jul 10, 2024



Large language models (LLMs) have shown exceptional performance and vast potential across diverse tasks. However, the deployment of LLMs with high performance in low-resource environments has garnered significant attention in the industry. When GPU hardware resources are limited, we can explore alternative options on CPUs. To mitigate the financial burden and alleviate constraints imposed by hardware resources, optimizing inference performance is necessary. In this paper, we introduce an easily deployable inference performance optimization solution aimed at accelerating LLMs on CPUs. In this solution, we implement an effective way to reduce the KV cache size while ensuring precision. We propose a distributed inference optimization approach and implement it based on oneAPI Collective Communications Library. Furthermore, we propose optimization approaches for LLMs on CPU, and conduct tailored optimizations for the most commonly used models. The code is open-sourced at https://github.com/intel/xFasterTransformer.
Characterizing Deep Learning Training Workloads on Alibaba-PAI
Oct 14, 2019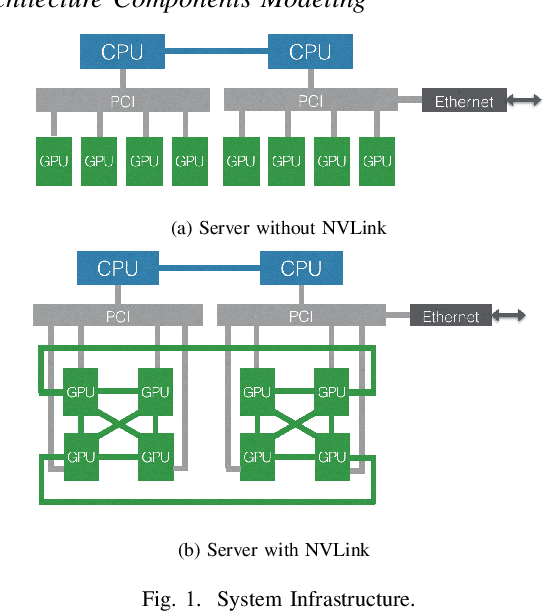
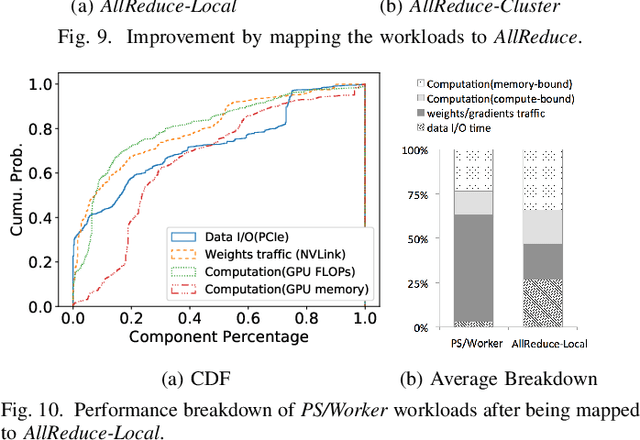
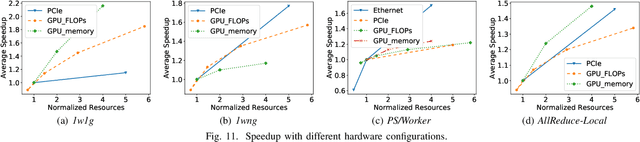
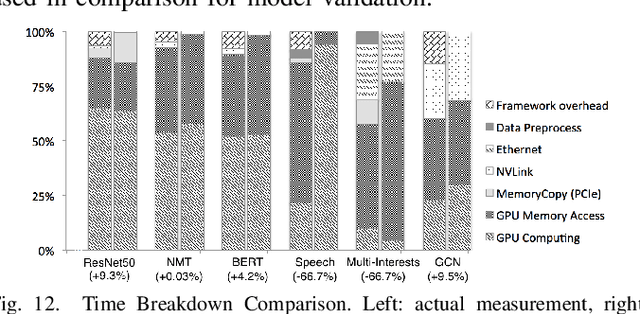
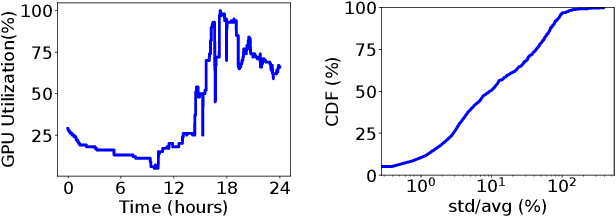
Modern deep learning models have been exploited in various domains, including computer vision (CV), natural language processing (NLP), search and recommendation. In practical AI clusters, workloads training these models are run using software frameworks such as TensorFlow, Caffe, PyTorch and CNTK. One critical issue for efficiently operating practical AI clouds, is to characterize the computing and data transfer demands of these workloads, and more importantly, the training performance given the underlying software framework and hardware configurations. In this paper, we characterize deep learning training workloads from Platform of Artificial Intelligence (PAI) in Alibaba. We establish an analytical framework to investigate detailed execution time breakdown of various workloads using different training architectures, to identify performance bottleneck. Results show that weight/gradient communication during training takes almost 62% of the total execution time among all our workloads on average. The computation part, involving both GPU computing and memory access, are not the biggest bottleneck based on collective behavior of the workloads. We further evaluate attainable performance of the workloads on various potential software/hardware mappings, and explore implications on software architecture selection and hardware configurations. We identify that 60% of PS/Worker workloads can be potentially sped up when ported to the AllReduce architecture exploiting the high-speed NVLink for GPU interconnect, and on average 1.7X speedup can be achieved when Ethernet bandwidth is upgraded from 25 Gbps to 100 Gbps.
DL2: A Deep Learning-driven Scheduler for Deep Learning Clusters
Sep 13, 2019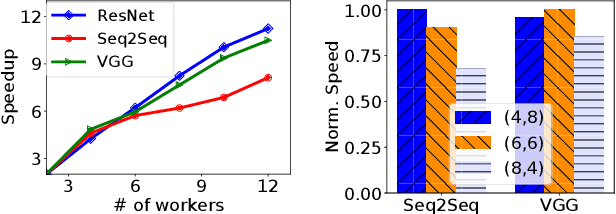
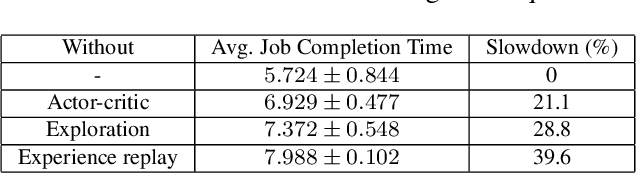
More and more companies have deployed machine learning (ML) clusters, where deep learning (DL) models are trained for providing various AI-driven services. Efficient resource scheduling is essential for maximal utilization of expensive DL clusters. Existing cluster schedulers either are agnostic to ML workload characteristics, or use scheduling heuristics based on operators' understanding of particular ML framework and workload, which are less efficient or not general enough. In this paper, we show that DL techniques can be adopted to design a generic and efficient scheduler. DL2 is a DL-driven scheduler for DL clusters, targeting global training job expedition by dynamically resizing resources allocated to jobs. DL2 advocates a joint supervised learning and reinforcement learning approach: a neural network is warmed up via offline supervised learning based on job traces produced by the existing cluster scheduler; then the neural network is plugged into the live DL cluster, fine-tuned by reinforcement learning carried out throughout the training progress of the DL jobs, and used for deciding job resource allocation in an online fashion. By applying past decisions made by the existing cluster scheduler in the preparatory supervised learning phase, our approach enables a smooth transition from existing scheduler, and renders a high-quality scheduler in minimizing average training completion time. We implement DL2 on Kubernetes and enable dynamic resource scaling in DL jobs on MXNet. Extensive evaluation shows that DL2 outperforms fairness scheduler (i.e., DRF) by 44.1% and expert heuristic scheduler (i.e., Optimus) by 17.5% in terms of average job completion time.