 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Probe Zero Collision Hash (MPZCH): Mitigating Embedding Collisions and Enhancing Model Freshness in Large-Scale Recommenders
Feb 19, 2026Embedding tables are critical components of large-scale recommendation systems, facilitating the efficient mapping of high-cardinality categorical features into dense vector representations. However, as the volume of unique IDs expands, traditional hash-based indexing methods suffer from collisions that degrade model performance and personalization quality. We present Multi-Probe Zero Collision Hash (MPZCH), a novel indexing mechanism based on linear probing that effectively mitigates embedding collisions. With reasonable table sizing, it often eliminates these collisions entirely while maintaining production-scale efficiency. MPZCH utilizes auxiliary tensors and high-performance CUDA kernels to implement configurable probing and active eviction policies. By retiring obsolete IDs and resetting reassigned slots, MPZCH prevents the stale embedding inheritance typical of hash-based methods, ensuring new features learn effectively from scratch. Despite its collision-mitigation overhead, the system maintains training QPS and inference latency comparable to existing methods. Rigorous online experiments demonstrate that MPZCH achieves zero collisions for user embeddings and significantly improves item embedding freshness and quality. The solution has been released within the open-source TorchRec library for the broader community.
DL2: A Deep Learning-driven Scheduler for Deep Learning Clusters
Sep 13, 2019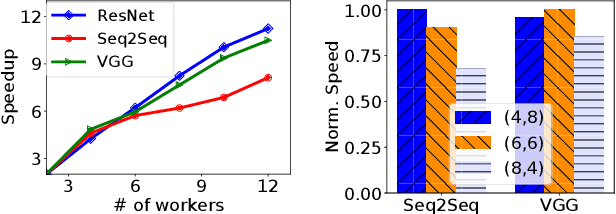
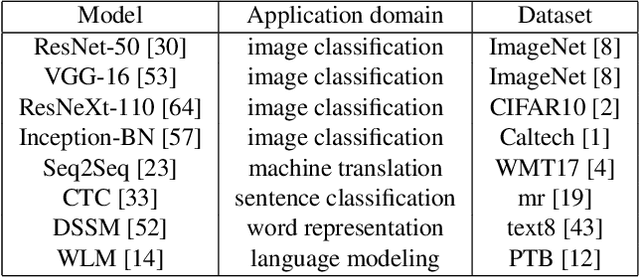
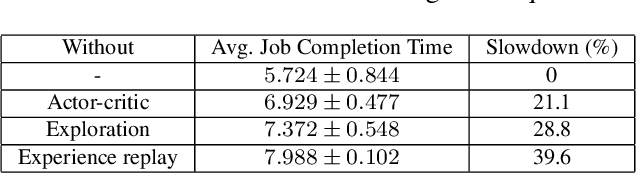
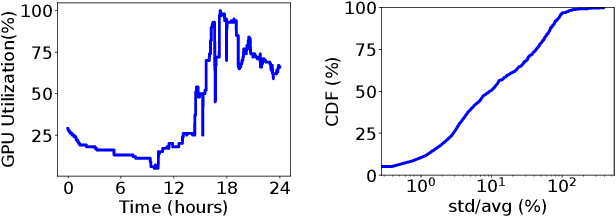
More and more companies have deployed machine learning (ML) clusters, where deep learning (DL) models are trained for providing various AI-driven services. Efficient resource scheduling is essential for maximal utilization of expensive DL clusters. Existing cluster schedulers either are agnostic to ML workload characteristics, or use scheduling heuristics based on operators' understanding of particular ML framework and workload, which are less efficient or not general enough. In this paper, we show that DL techniques can be adopted to design a generic and efficient scheduler. DL2 is a DL-driven scheduler for DL clusters, targeting global training job expedition by dynamically resizing resources allocated to jobs. DL2 advocates a joint supervised learning and reinforcement learning approach: a neural network is warmed up via offline supervised learning based on job traces produced by the existing cluster scheduler; then the neural network is plugged into the live DL cluster, fine-tuned by reinforcement learning carried out throughout the training progress of the DL jobs, and used for deciding job resource allocation in an online fashion. By applying past decisions made by the existing cluster scheduler in the preparatory supervised learning phase, our approach enables a smooth transition from existing scheduler, and renders a high-quality scheduler in minimizing average training completion time. We implement DL2 on Kubernetes and enable dynamic resource scaling in DL jobs on MXNet. Extensive evaluation shows that DL2 outperforms fairness scheduler (i.e., DRF) by 44.1% and expert heuristic scheduler (i.e., Optimus) by 17.5% in terms of average job completion time.
High Order Neural Networks for Video Classification
Nov 19, 2018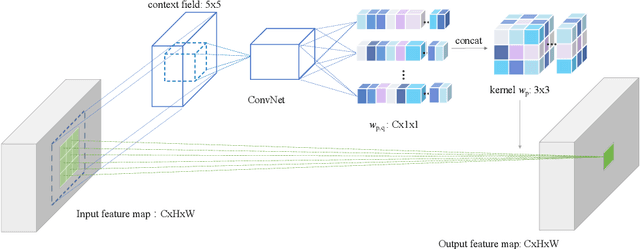
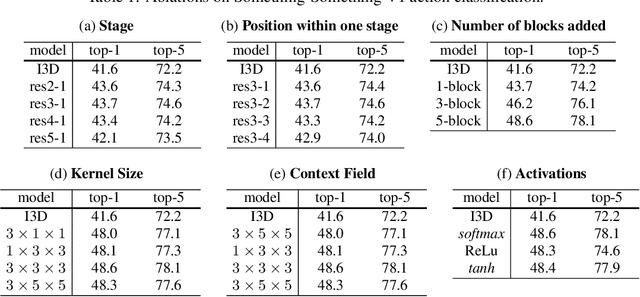
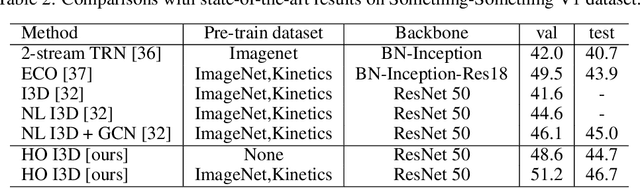

Capturing spatiotemporal correlations is an essential topic in video classification. In this paper, we present high order operations as a generic family of building blocks for capturing high order correlations from high dimensional input video space. We prove that several successful architectures for visual classification tasks are in the family of high order neural networks, theoretical and experimental analysis demonstrates their underlying mechanism is high order. We also proposal a new LEarnable hiGh Order (LEGO) block, whose goal is to capture spatiotemporal correlation in a feedforward manner. Specifically, LEGO blocks implicitly learn the relation expressions for spatiotemporal features and use the learned relations to weight input features. This building block can be plugged into many neural network architectures, achieving evident improvement without introducing much overhead. On the task of video classification, even using RGB only without fine-tuning with other video datasets, our high order models can achieve results on par with or better than the existing state-of-the-art methods on both Something-Something (V1 and V2) and Charades datasets.
Qiniu Submission to ActivityNet Challenge 2018
Jun 12, 2018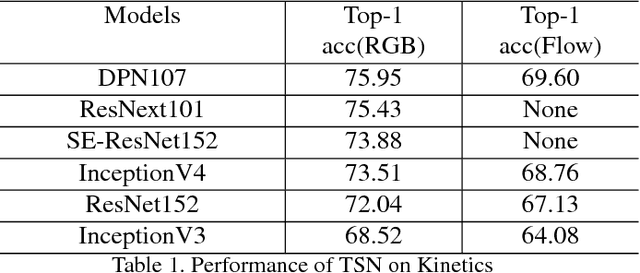
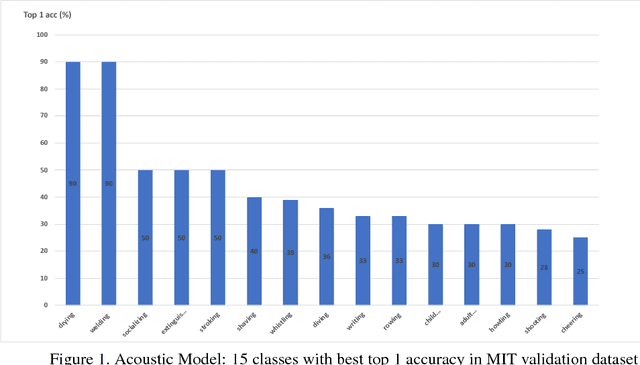
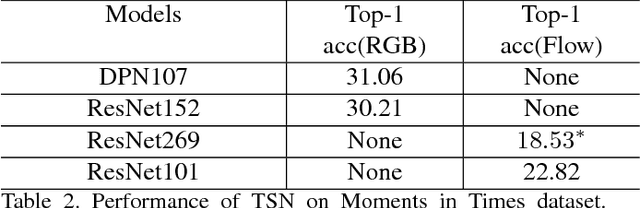
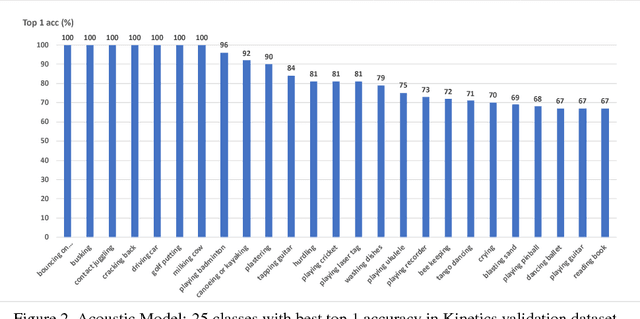
In this paper, we introduce our submissions for the tasks of trimmed activity recognition (Kinetics) and trimmed event recognition (Moments in Time) for Activitynet Challenge 2018. In the two tasks, non-local neural networks and temporal segment networks are implemented as our base models. Multi-modal cues such as RGB image, optical flow and acoustic signal have also been used in our method. We also propose new non-local-based models for further improvement on the recognition accuracy. The final submissions after ensembling the models achieve 83.5% top-1 accuracy and 96.8% top-5 accuracy on the Kinetics validation set, 35.81% top-1 accuracy and 62.59% top-5 accuracy on the MIT validation set.
Online Influence Maximization in Non-Stationary Social Networks
Apr 26, 2016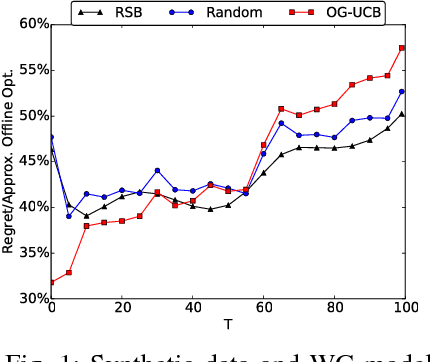
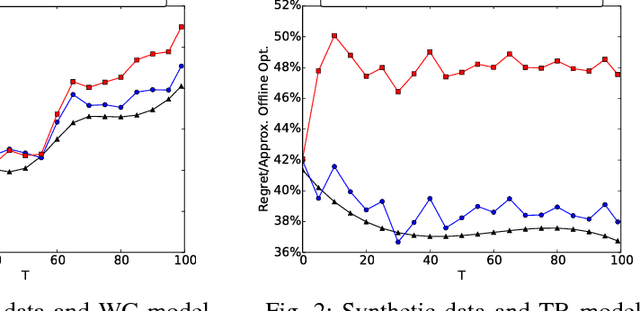
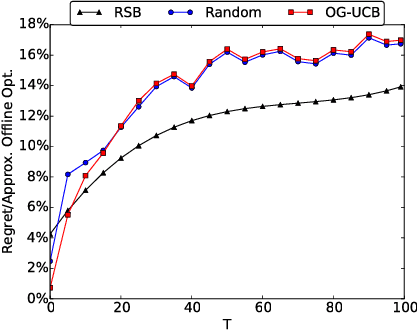
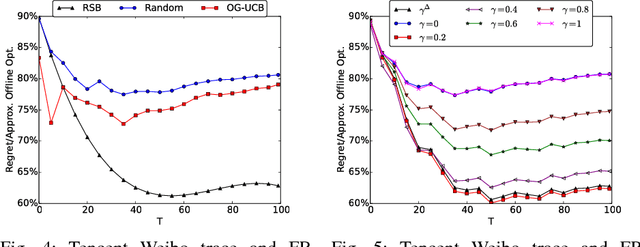
Social networks have been popular platforms for information propagation. An important use case is viral marketing: given a promotion budget, an advertiser can choose some influential users as the seed set and provide them free or discounted sample products; in this way, the advertiser hopes to increase the popularity of the product in the users' friend circles by the world-of-mouth effect, and thus maximizes the number of users that information of the production can reach. There has been a body of literature studying the influence maximization problem. Nevertheless, the existing studies mostly investigate the problem on a one-off basis, assuming fixed known influence probabilities among users, or the knowledge of the exact social network topology. In practice, the social network topology and the influence probabilities are typically unknown to the advertiser, which can be varying over time, i.e., in cases of newly established, strengthened or weakened social ties. In this paper, we focus on a dynamic non-stationary social network and design a randomized algorithm, RSB, based on multi-armed bandit optimization, to maximize influence propagation over time. The algorithm produces a sequence of online decisions and calibrates its explore-exploit strategy utilizing outcomes of previous decisions. It is rigorously proven to achieve an upper-bounded regret in reward and applicable to large-scale social networks. Practical effectiveness of the algorithm is evaluated using both synthetic and real-world datasets, which demonstrates that our algorithm outperforms previous stationary methods under non-stationary conditions.