 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePUAL: A Classifier on Trifurcate Positive-Unlabeled Data
May 31, 2024



Positive-unlabeled (PU) learning aims to train a classifier using the data containing only labeled-positive instances and unlabeled instances. However, existing PU learning methods are generally hard to achieve satisfactory performance on trifurcate data, where the positive instances distribute on both sides of the negative instances. To address this issue, firstly we propose a PU classifier with asymmetric loss (PUAL), by introducing a structure of asymmetric loss on positive instances into the objective function of the global and local learning classifier. Then we develop a kernel-based algorithm to enable PUAL to obtain non-linear decision boundary. We show that, through experiments on both simulated and real-world datasets, PUAL can achieve satisfactory classification on trifurcate data.
Towards Topic-Guided Conversational Recommender System
Oct 08, 2020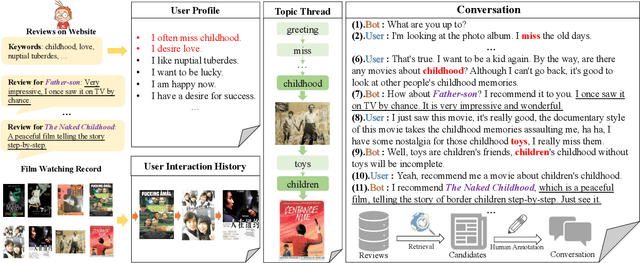
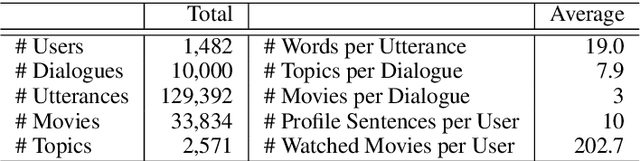
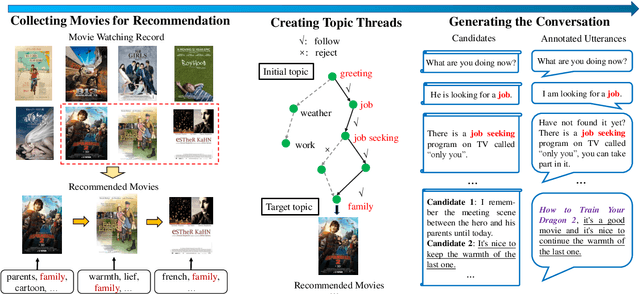
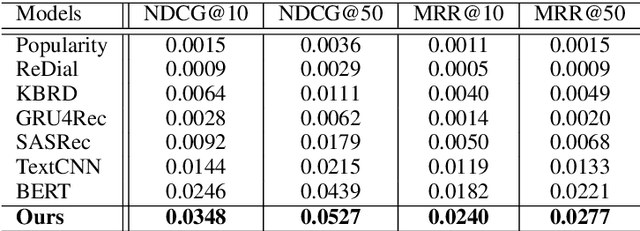
Conversational recommender systems (CRS) aim to recommend high-quality items to users through interactive conversations. To develop an effective CRS, the support of high-quality datasets is essential. Existing CRS datasets mainly focus on immediate requests from users, while lack proactive guidance to the recommendation scenario. In this paper, we contribute a new CRS dataset named \textbf{TG-ReDial} (\textbf{Re}commendation through \textbf{T}opic-\textbf{G}uided \textbf{Dial}og). Our dataset has two major features. First, it incorporates topic threads to enforce natural semantic transitions towards the recommendation scenario. Second, it is created in a semi-automatic way, hence human annotation is more reasonable and controllable. Based on TG-ReDial, we present the task of topic-guided conversational recommendation, and propose an effective approach to this task. Extensive experiments have demonstrated the effectiveness of our approach on three sub-tasks, namely topic prediction, item recommendation and response generation. TG-ReDial is available at https://github.com/RUCAIBox/TG-ReDial.
A Remote Sensing Image Dataset for Cloud Removal
Jan 03, 2019

Cloud-based overlays are often present in optical remote sensing images, thus limiting the application of acquired data. Removing clouds is an indispensable pre-processing step in remote sensing image analysis. Deep learning has achieved great success in the field of remote sensing in recent years, including scene classification and change detection. However, deep learning is rarely applied in remote sensing image removal clouds. The reason is the lack of data sets for training neural networks. In order to solve this problem, this paper first proposed the Remote sensing Image Cloud rEmoving dataset (RICE). The proposed dataset consists of two parts: RICE1 contains 500 pairs of images, each pair has images with cloud and cloudless size of 512*512; RICE2 contains 450 sets of images, each set contains three 512*512 size images. , respectively, the reference picture without clouds, the picture of the cloud and the mask of its cloud. The dataset is freely available at \url{https://github.com/BUPTLdy/RICE_DATASET}.
Online Influence Maximization in Non-Stationary Social Networks
Apr 26, 2016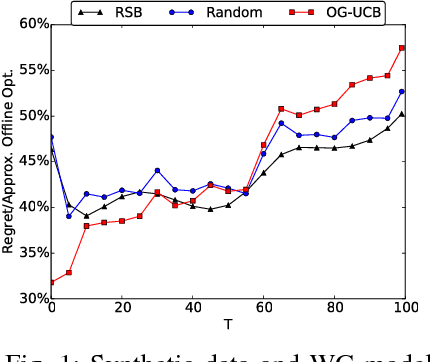
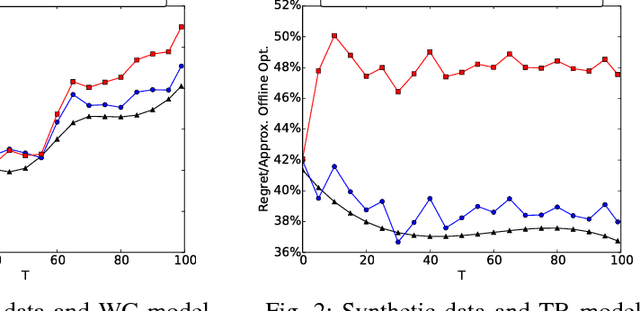
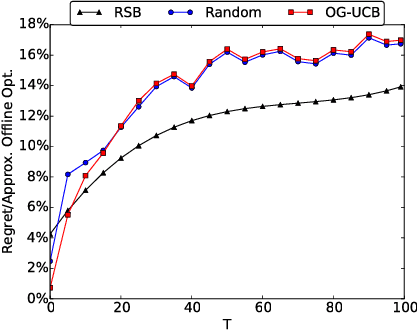
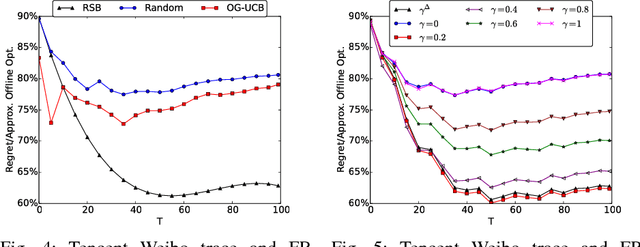
Social networks have been popular platforms for information propagation. An important use case is viral marketing: given a promotion budget, an advertiser can choose some influential users as the seed set and provide them free or discounted sample products; in this way, the advertiser hopes to increase the popularity of the product in the users' friend circles by the world-of-mouth effect, and thus maximizes the number of users that information of the production can reach. There has been a body of literature studying the influence maximization problem. Nevertheless, the existing studies mostly investigate the problem on a one-off basis, assuming fixed known influence probabilities among users, or the knowledge of the exact social network topology. In practice, the social network topology and the influence probabilities are typically unknown to the advertiser, which can be varying over time, i.e., in cases of newly established, strengthened or weakened social ties. In this paper, we focus on a dynamic non-stationary social network and design a randomized algorithm, RSB, based on multi-armed bandit optimization, to maximize influence propagation over time. The algorithm produces a sequence of online decisions and calibrates its explore-exploit strategy utilizing outcomes of previous decisions. It is rigorously proven to achieve an upper-bounded regret in reward and applicable to large-scale social networks. Practical effectiveness of the algorithm is evaluated using both synthetic and real-world datasets, which demonstrates that our algorithm outperforms previous stationary methods under non-stationary conditions.