 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh Order Neural Networks for Video Classification
Paper and Code
Nov 19, 2018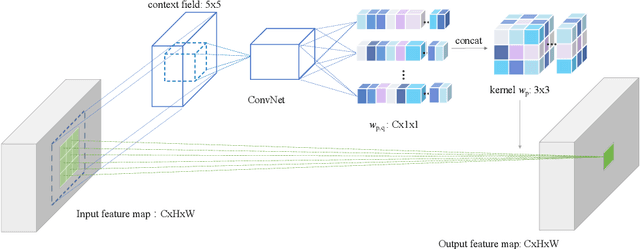
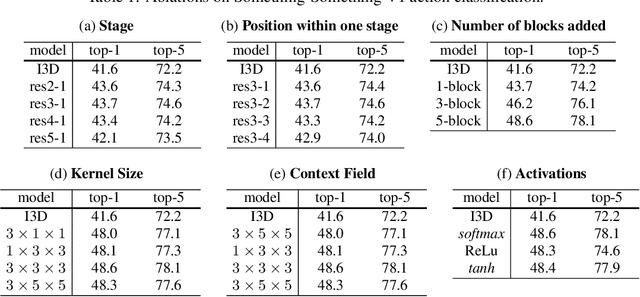
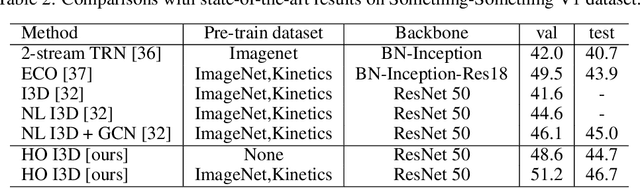

Capturing spatiotemporal correlations is an essential topic in video classification. In this paper, we present high order operations as a generic family of building blocks for capturing high order correlations from high dimensional input video space. We prove that several successful architectures for visual classification tasks are in the family of high order neural networks, theoretical and experimental analysis demonstrates their underlying mechanism is high order. We also proposal a new LEarnable hiGh Order (LEGO) block, whose goal is to capture spatiotemporal correlation in a feedforward manner. Specifically, LEGO blocks implicitly learn the relation expressions for spatiotemporal features and use the learned relations to weight input features. This building block can be plugged into many neural network architectures, achieving evident improvement without introducing much overhead. On the task of video classification, even using RGB only without fine-tuning with other video datasets, our high order models can achieve results on par with or better than the existing state-of-the-art methods on both Something-Something (V1 and V2) and Charades datasets.