 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoPA: Scaling dLLM Inference via Lookahead Parallel Decoding
Dec 22, 2025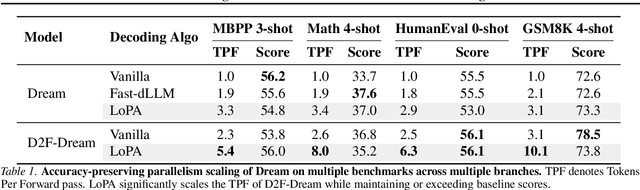
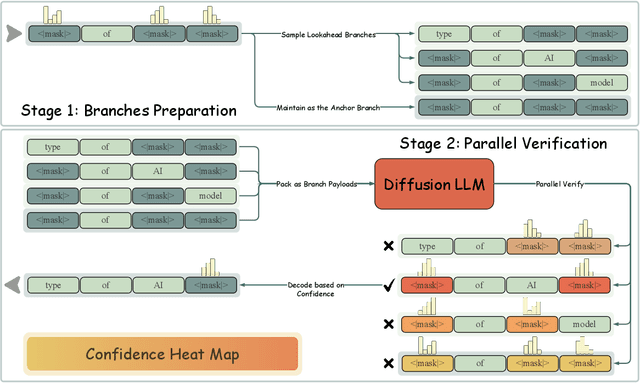
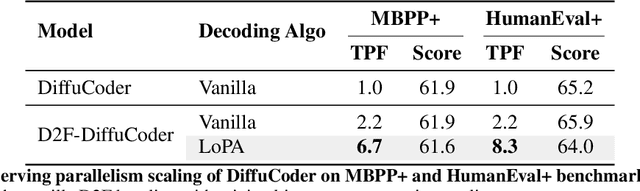
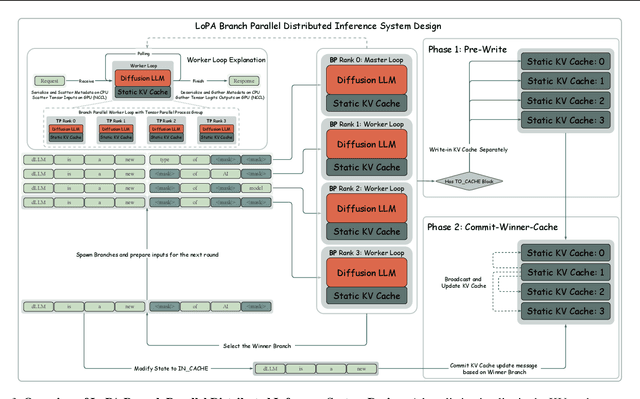
Diffusion Large Language Models (dLLMs) have demonstrated significant potential for high-speed inference. However, current confidence-driven decoding strategies are constrained by limited parallelism, typically achieving only 1--3 tokens per forward pass (TPF). In this work, we identify that the degree of parallelism during dLLM inference is highly sensitive to the Token Filling Order (TFO). Then, we introduce Lookahead PArallel Decoding LoPA, a training-free, plug-and-play algorithm, to identify a superior TFO and hence accelerate inference. LoPA concurrently explores distinct candidate TFOs via parallel branches, and selects the one with the highest potential for future parallelism based on branch confidence. We apply LoPA to the state-of-the-art D2F model and observe a substantial enhancement in decoding efficiency. Notably, LoPA increases the TPF of D2F-Dream to 10.1 on the GSM8K while maintaining performance superior to the Dream baseline. Furthermore, to facilitate this unprecedented degree of parallelism, we develop a specialized multi-device inference system featuring Branch Parallelism (BP), which achieves a single-sample throughput of 1073.9 tokens per second under multi-GPU deployment. The code is available at https://github.com/zhijie-group/LoPA.
Tackling the Dynamicity in a Production LLM Serving System with SOTA Optimizations via Hybrid Prefill/Decode/Verify Scheduling on Efficient Meta-kernels
Dec 24, 2024



Meeting growing demands for low latency and cost efficiency in production-grade large language model (LLM) serving systems requires integrating advanced optimization techniques. However, dynamic and unpredictable input-output lengths of LLM, compounded by these optimizations, exacerbate the issues of workload variability, making it difficult to maintain high efficiency on AI accelerators, especially DSAs with tile-based programming models. To address this challenge, we introduce XY-Serve, a versatile, Ascend native, end-to-end production LLM-serving system. The core idea is an abstraction mechanism that smooths out the workload variability by decomposing computations into unified, hardware-friendly, fine-grained meta primitives. For attention, we propose a meta-kernel that computes the basic pattern of matmul-softmax-matmul with architectural-aware tile sizes. For GEMM, we introduce a virtual padding scheme that adapts to dynamic shape changes while using highly efficient GEMM primitives with assorted fixed tile sizes. XY-Serve sits harmoniously with vLLM. Experimental results show up to 89% end-to-end throughput improvement compared with current publicly available baselines on Ascend NPUs. Additionally, our approach outperforms existing GEMM (average 14.6% faster) and attention (average 21.5% faster) kernels relative to existing libraries. While the work is Ascend native, we believe the approach can be readily applicable to SIMT architectures as well.
FusionStitching: Boosting Memory Intensive Computations for Deep Learning Workloads
Sep 23, 2020


We show in this work that memory intensive computations can result in severe performance problems due to off-chip memory access and CPU-GPU context switch overheads in a wide range of deep learning models. For this problem, current just-in-time kernel fusion and code generation techniques have limitations, such as kernel schedule incompatibilities and rough fusion plan exploration strategies. We propose FusionStitching, a Deep Learning compiler capable of fusing memory intensive operators, with varied data dependencies and non-homogeneous parallelism, into large GPU kernels to reduce global memory access and operation scheduling overhead automatically. FusionStitching explores large fusion spaces to decide optimal fusion plans with considerations of memory access costs, kernel calls and resource usage constraints. We thoroughly study the schemes to stitch operators together for complex scenarios. FusionStitching tunes the optimal stitching scheme just-in-time with a domain-specific cost model efficiently. Experimental results show that FusionStitching can reach up to 2.78x speedup compared to TensorFlow and current state-of-the-art. Besides these experimental results, we integrated our approach into a compiler product and deployed it onto a production cluster for AI workloads with thousands of GPUs. The system has been in operation for more than 4 months and saves 7,000 GPU hours on average for approximately 30,000 tasks per month.
Auto-MAP: A DQN Framework for Exploring Distributed Execution Plans for DNN Workloads
Jul 08, 2020



The last decade has witnessed growth in the computational requirements for training deep neural networks. Current approaches (e.g., data/model parallelism, pipeline parallelism) parallelize training tasks onto multiple devices. However, these approaches always rely on specific deep learning frameworks and requires elaborate manual design, which make it difficult to maintain and share between different type of models. In this paper, we propose Auto-MAP, a framework for exploring distributed execution plans for DNN workloads, which can automatically discovering fast parallelization strategies through reinforcement learning on IR level of deep learning models. Efficient exploration remains a major challenge for reinforcement learning. We leverage DQN with task-specific pruning strategies to help efficiently explore the search space including optimized strategies. Our evaluation shows that Auto-MAP can find the optimal solution in two hours, while achieving better throughput on several NLP and convolution models.
Characterizing Deep Learning Training Workloads on Alibaba-PAI
Oct 14, 2019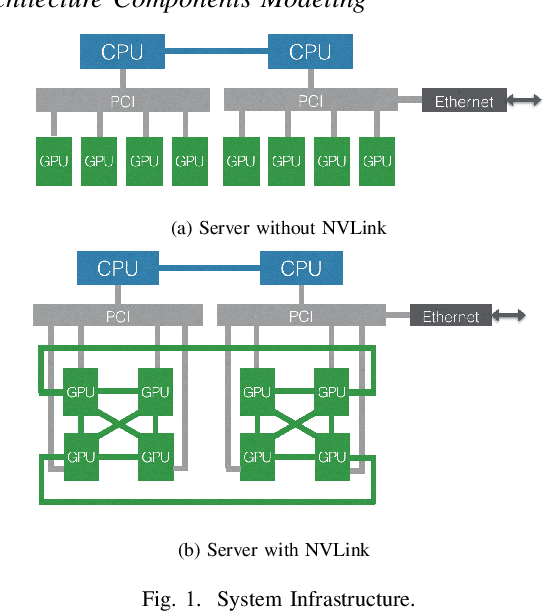
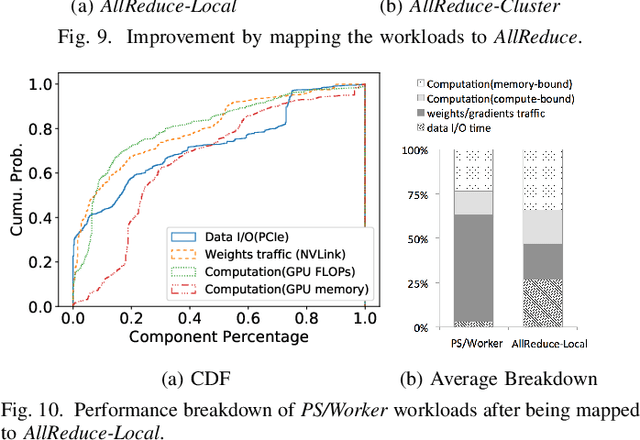
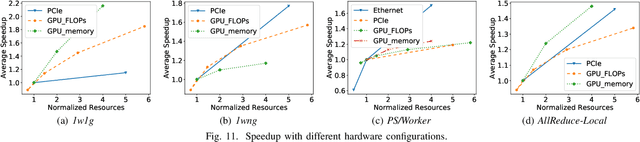
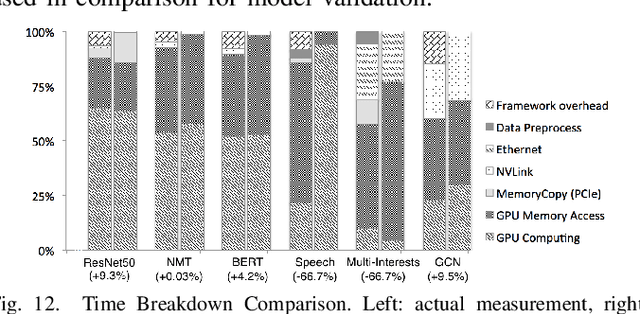
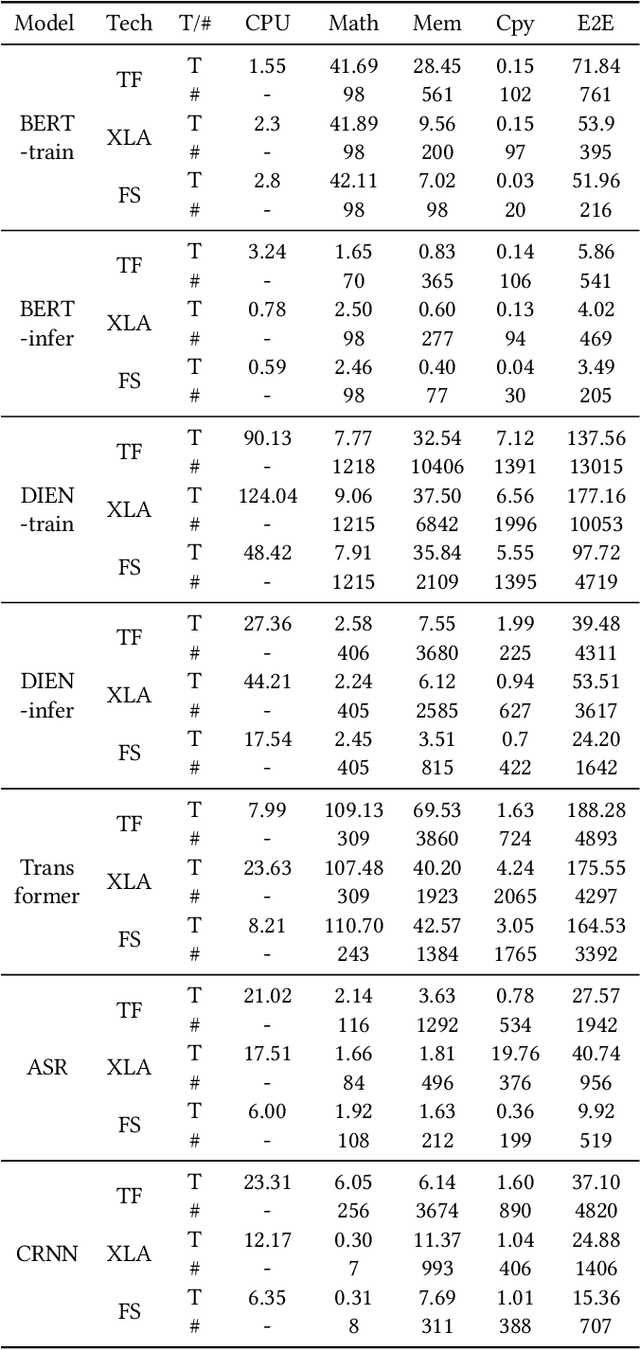
Modern deep learning models have been exploited in various domains, including computer vision (CV), natural language processing (NLP), search and recommendation. In practical AI clusters, workloads training these models are run using software frameworks such as TensorFlow, Caffe, PyTorch and CNTK. One critical issue for efficiently operating practical AI clouds, is to characterize the computing and data transfer demands of these workloads, and more importantly, the training performance given the underlying software framework and hardware configurations. In this paper, we characterize deep learning training workloads from Platform of Artificial Intelligence (PAI) in Alibaba. We establish an analytical framework to investigate detailed execution time breakdown of various workloads using different training architectures, to identify performance bottleneck. Results show that weight/gradient communication during training takes almost 62% of the total execution time among all our workloads on average. The computation part, involving both GPU computing and memory access, are not the biggest bottleneck based on collective behavior of the workloads. We further evaluate attainable performance of the workloads on various potential software/hardware mappings, and explore implications on software architecture selection and hardware configurations. We identify that 60% of PS/Worker workloads can be potentially sped up when ported to the AllReduce architecture exploiting the high-speed NVLink for GPU interconnect, and on average 1.7X speedup can be achieved when Ethernet bandwidth is upgraded from 25 Gbps to 100 Gbps.
Efficient and Adaptive Kernelization for Nonlinear Max-margin Multi-view Learning
Oct 11, 2019



Existing multi-view learning methods based on kernel function either require the user to select and tune a single predefined kernel or have to compute and store many Gram matrices to perform multiple kernel learning. Apart from the huge consumption of manpower, computation and memory resources, most of these models seek point estimation of their parameters, and are prone to overfitting to small training data. This paper presents an adaptive kernel nonlinear max-margin multi-view learning model under the Bayesian framework. Specifically, we regularize the posterior of an efficient multi-view latent variable model by explicitly mapping the latent representations extracted from multiple data views to a random Fourier feature space where max-margin classification constraints are imposed. Assuming these random features are drawn from Dirichlet process Gaussian mixtures, we can adaptively learn shift-invariant kernels from data according to Bochners theorem. For inference, we employ the data augmentation idea for hinge loss, and design an efficient gradient-based MCMC sampler in the augmented space. Having no need to compute the Gram matrix, our algorithm scales linearly with the size of training set. Extensive experiments on real-world datasets demonstrate that our method has superior performance.
Learning beyond Predefined Label Space via Bayesian Nonparametric Topic Modelling
Oct 10, 2019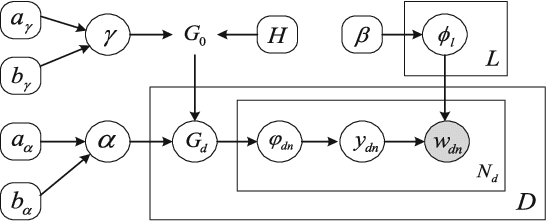

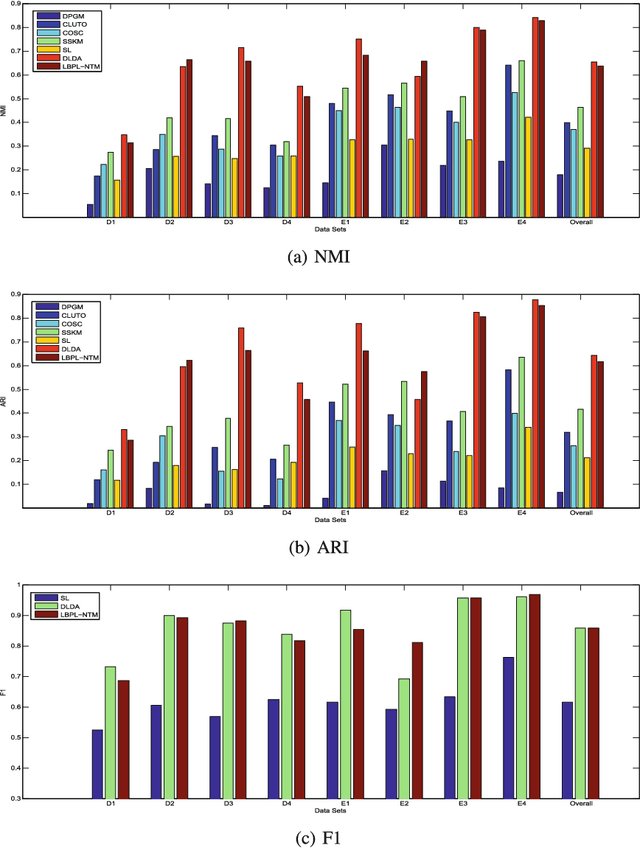
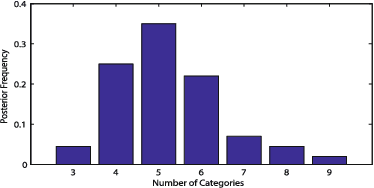
In real world machine learning applications, testing data may contain some meaningful new categories that have not been seen in labeled training data. To simultaneously recognize new data categories and assign most appropriate category labels to the data actually from known categories, existing models assume the number of unknown new categories is pre-specified, though it is difficult to determine in advance. In this paper, we propose a Bayesian nonparametric topic model to automatically infer this number, based on the hierarchical Dirichlet process and the notion of latent Dirichlet allocation. Exact inference in our model is intractable, so we provide an efficient collapsed Gibbs sampling algorithm for approximate posterior inference. Extensive experiments on various text data sets show that: (a) compared with parametric approaches that use pre-specified true number of new categories, the proposed nonparametric approach can yield comparable performance; and (b) when the exact number of new categories is unavailable, i.e. the parametric approaches only have a rough idea about the new categories, our approach has evident performance advantages.
A Conditional Variational Framework for Dialog Generation
Jul 06, 2017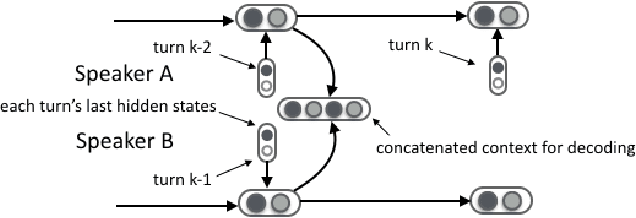
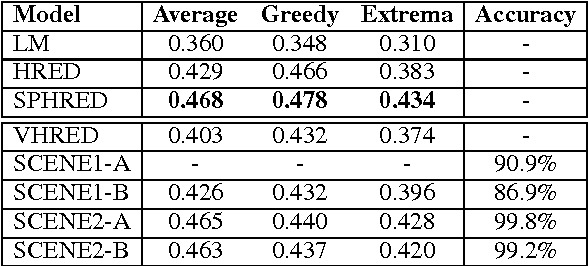
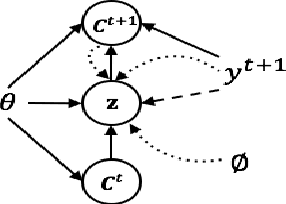

Deep latent variable models have been shown to facilitate the response generation for open-domain dialog systems. However, these latent variables are highly randomized, leading to uncontrollable generated responses. In this paper, we propose a framework allowing conditional response generation based on specific attributes. These attributes can be either manually assigned or automatically detected. Moreover, the dialog states for both speakers are modeled separately in order to reflect personal features. We validate this framework on two different scenarios, where the attribute refers to genericness and sentiment states respectively. The experiment result testified the potential of our model, where meaningful responses can be generated in accordance with the specified attributes.
GPU-FV: Realtime Fisher Vector and Its Applications in Video Monitoring
Apr 12, 2016
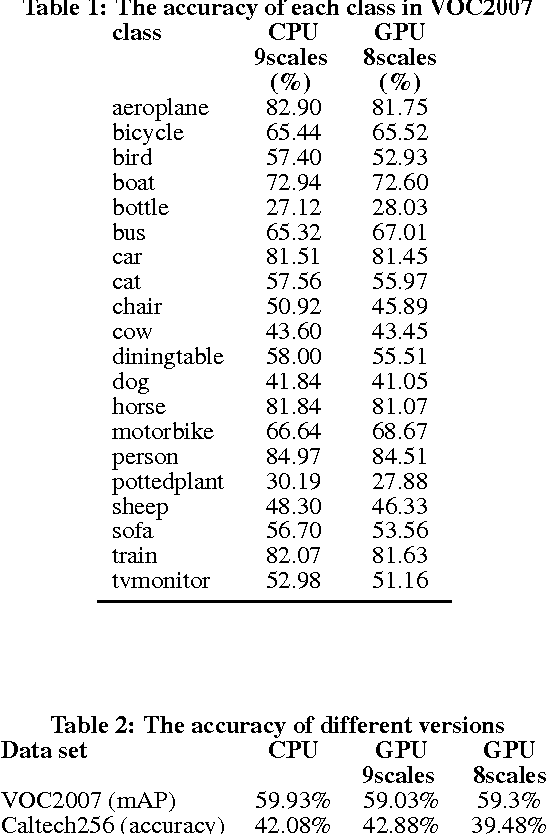
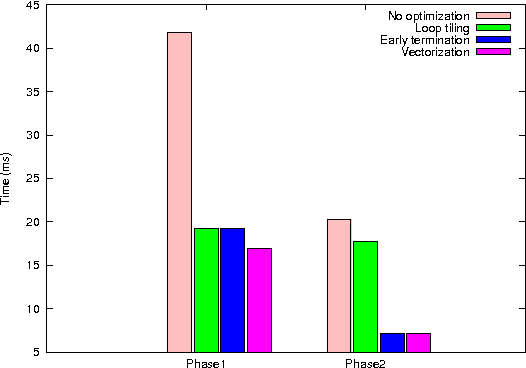
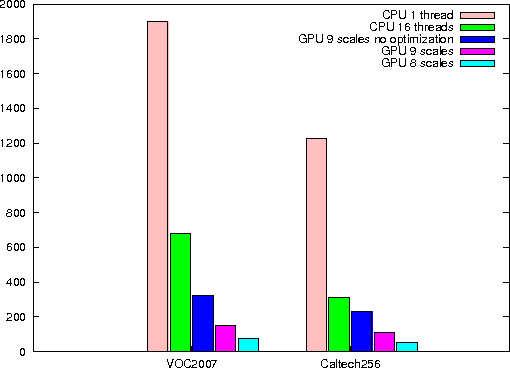
Fisher vector has been widely used in many multimedia retrieval and visual recognition applications with good performance. However, the computation complexity prevents its usage in real-time video monitoring. In this work, we proposed and implemented GPU-FV, a fast Fisher vector extraction method with the help of modern GPUs. The challenge of implementing Fisher vector on GPUs lies in the data dependency in feature extraction and expensive memory access in Fisher vector computing. To handle these challenges, we carefully designed GPU-FV in a way that utilizes the computing power of GPU as much as possible, and applied optimizations such as loop tiling to boost the performance. GPU-FV is about 12 times faster than the CPU version, and 50\% faster than a non-optimized GPU implementation. For standard video input (320*240), GPU-FV can process each frame within 34ms on a model GPU. Our experiments show that GPU-FV obtains a similar recognition accuracy as traditional FV on VOC 2007 and Caltech 256 image sets. We also applied GPU-FV for realtime video monitoring tasks and found that GPU-FV outperforms a number of previous works. Especially, when the number of training examples are small, GPU-FV outperforms the recent popular deep CNN features borrowed from ImageNet. The code can be downloaded from the following link https://bitbucket.org/mawenjing/gpu-fv.