 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Generic Semi-Supervised Medical Image Segmentation via Diverse Teaching and Label Propagation
Aug 12, 2025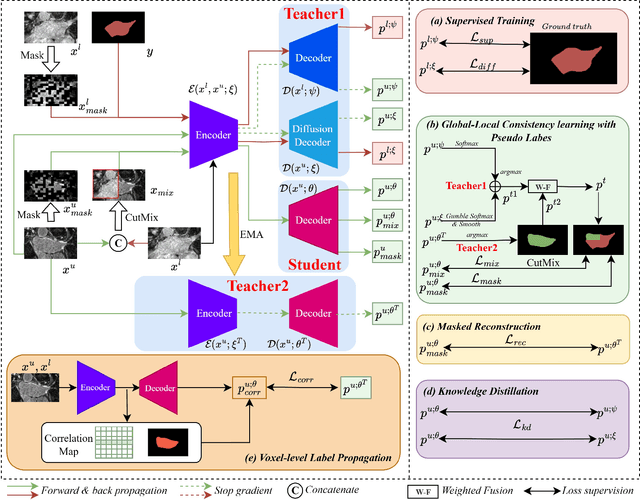
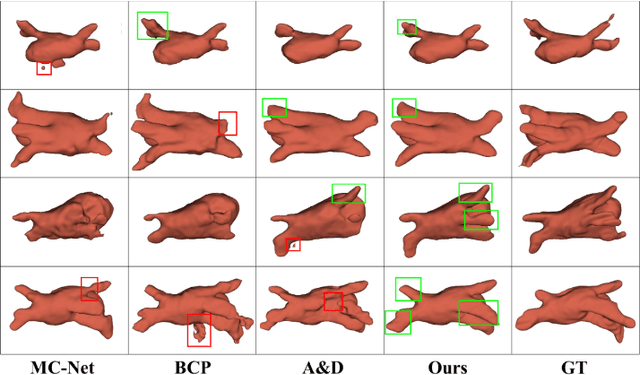
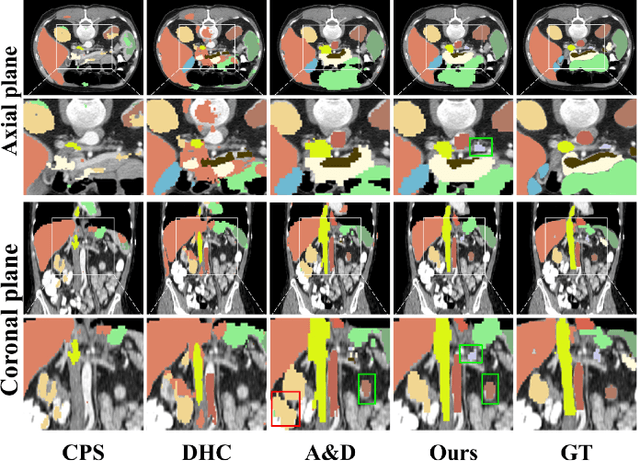
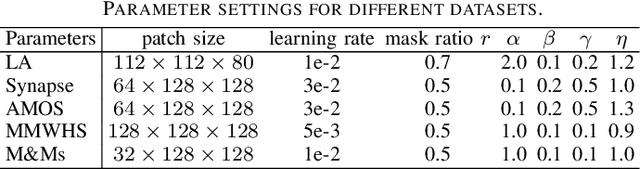
Both limited annotation and domain shift are significant challenges frequently encountered in medical image segmentation, leading to derivative scenarios like semi-supervised medical (SSMIS), semi-supervised medical domain generalization (Semi-MDG) and unsupervised medical domain adaptation (UMDA). Conventional methods are generally tailored to specific tasks in isolation, the error accumulation hinders the effective utilization of unlabeled data and limits further improvements, resulting in suboptimal performance when these issues occur. In this paper, we aim to develop a generic framework that masters all three tasks. We found that the key to solving the problem lies in how to generate reliable pseudo labels for the unlabeled data in the presence of domain shift with labeled data and increasing the diversity of the model. To tackle this issue, we employ a Diverse Teaching and Label Propagation Network (DTLP-Net) to boosting the Generic Semi-Supervised Medical Image Segmentation. Our DTLP-Net involves a single student model and two diverse teacher models, which can generate reliable pseudo-labels for the student model. The first teacher model decouple the training process with labeled and unlabeled data, The second teacher is momentum-updated periodically, thus generating reliable yet divers pseudo-labels. To fully utilize the information within the data, we adopt inter-sample and intra-sample data augmentation to learn the global and local knowledge. In addition, to further capture the voxel-level correlations, we propose label propagation to enhance the model robust. We evaluate our proposed framework on five benchmark datasets for SSMIS, UMDA, and Semi-MDG tasks. The results showcase notable improvements compared to state-of-the-art methods across all five settings, indicating the potential of our framework to tackle more challenging SSL scenarios.
AutoGLM: Autonomous Foundation Agents for GUIs
Oct 28, 2024



We present AutoGLM, a new series in the ChatGLM family, designed to serve as foundation agents for autonomous control of digital devices through Graphical User Interfaces (GUIs). While foundation models excel at acquiring human knowledge, they often struggle with decision-making in dynamic real-world environments, limiting their progress toward artificial general intelligence. This limitation underscores the importance of developing foundation agents capable of learning through autonomous environmental interactions by reinforcing existing models. Focusing on Web Browser and Phone as representative GUI scenarios, we have developed AutoGLM as a practical foundation agent system for real-world GUI interactions. Our approach integrates a comprehensive suite of techniques and infrastructures to create deployable agent systems suitable for user delivery. Through this development, we have derived two key insights: First, the design of an appropriate "intermediate interface" for GUI control is crucial, enabling the separation of planning and grounding behaviors, which require distinct optimization for flexibility and accuracy respectively. Second, we have developed a novel progressive training framework that enables self-evolving online curriculum reinforcement learning for AutoGLM. Our evaluations demonstrate AutoGLM's effectiveness across multiple domains. For web browsing, AutoGLM achieves a 55.2% success rate on VAB-WebArena-Lite (improving to 59.1% with a second attempt) and 96.2% on OpenTable evaluation tasks. In Android device control, AutoGLM attains a 36.2% success rate on AndroidLab (VAB-Mobile) and 89.7% on common tasks in popular Chinese APPs.
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
Jun 18, 2024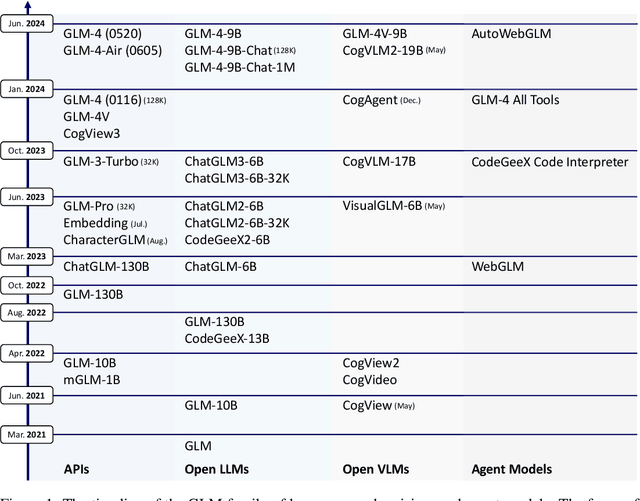
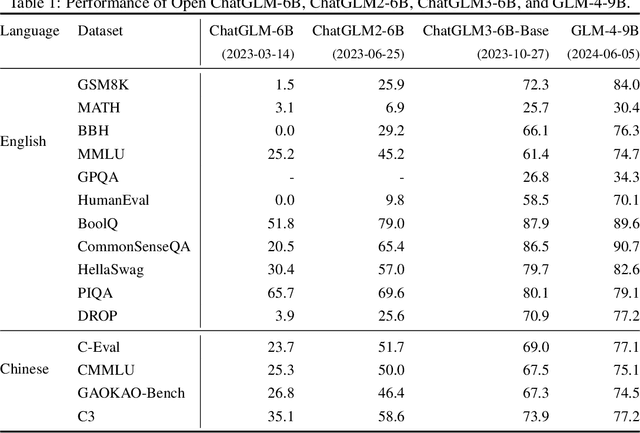
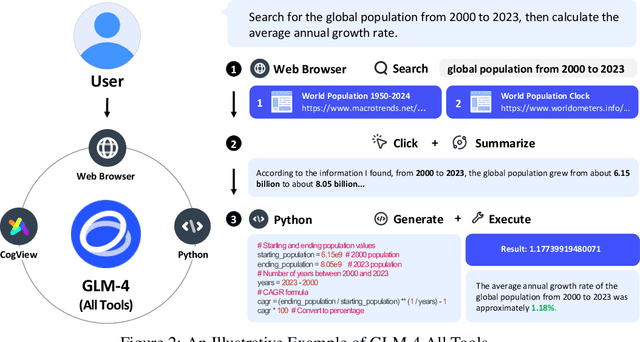
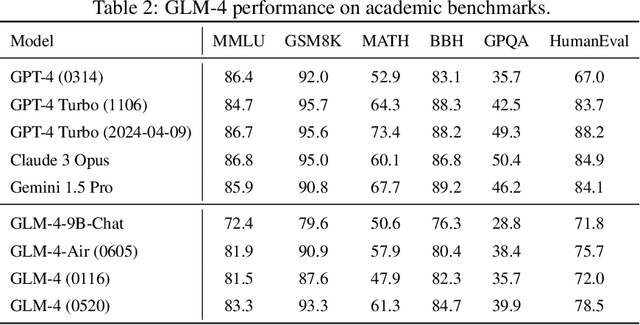
We introduce ChatGLM, an evolving family of large language models that we have been developing over time. This report primarily focuses on the GLM-4 language series, which includes GLM-4, GLM-4-Air, and GLM-4-9B. They represent our most capable models that are trained with all the insights and lessons gained from the preceding three generations of ChatGLM. To date, the GLM-4 models are pre-trained on ten trillions of tokens mostly in Chinese and English, along with a small set of corpus from 24 languages, and aligned primarily for Chinese and English usage. The high-quality alignment is achieved via a multi-stage post-training process, which involves supervised fine-tuning and learning from human feedback. Evaluations show that GLM-4 1) closely rivals or outperforms GPT-4 in terms of general metrics such as MMLU, GSM8K, MATH, BBH, GPQA, and HumanEval, 2) gets close to GPT-4-Turbo in instruction following as measured by IFEval, 3) matches GPT-4 Turbo (128K) and Claude 3 for long context tasks, and 4) outperforms GPT-4 in Chinese alignments as measured by AlignBench. The GLM-4 All Tools model is further aligned to understand user intent and autonomously decide when and which tool(s) touse -- including web browser, Python interpreter, text-to-image model, and user-defined functions -- to effectively complete complex tasks. In practical applications, it matches and even surpasses GPT-4 All Tools in tasks like accessing online information via web browsing and solving math problems using Python interpreter. Over the course, we have open-sourced a series of models, including ChatGLM-6B (three generations), GLM-4-9B (128K, 1M), GLM-4V-9B, WebGLM, and CodeGeeX, attracting over 10 million downloads on Hugging face in the year 2023 alone. The open models can be accessed through https://github.com/THUDM and https://huggingface.co/THUDM.
ChatGLM-Math: Improving Math Problem-Solving in Large Language Models with a Self-Critique Pipeline
Apr 03, 2024
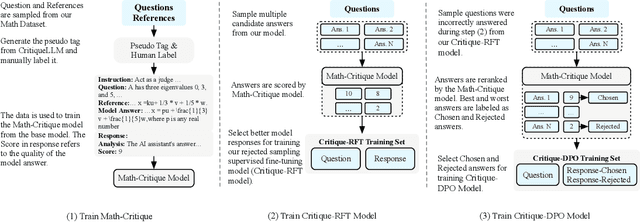


Large language models (LLMs) have shown excellent mastering of human language, but still struggle in real-world applications that require mathematical problem-solving. While many strategies and datasets to enhance LLMs' mathematics are developed, it remains a challenge to simultaneously maintain and improve both language and mathematical capabilities in deployed LLM systems.In this work, we tailor the Self-Critique pipeline, which addresses the challenge in the feedback learning stage of LLM alignment. We first train a general Math-Critique model from the LLM itself to provide feedback signals. Then, we sequentially employ rejective fine-tuning and direct preference optimization over the LLM's own generations for data collection. Based on ChatGLM3-32B, we conduct a series of experiments on both academic and our newly created challenging dataset, MathUserEval. Results show that our pipeline significantly enhances the LLM's mathematical problem-solving while still improving its language ability, outperforming LLMs that could be two times larger. Related techniques have been deployed to ChatGLM\footnote{\url{https://chatglm.cn}}, an online serving LLM. Related evaluation dataset and scripts are released at \url{https://github.com/THUDM/ChatGLM-Math}.
Image-Guided Autonomous Guidewire Navigation in Robot-Assisted Endovascular Interventions using Reinforcement Learning
Mar 09, 2024



Autonomous robots in endovascular interventions possess the potential to navigate guidewires with safety and reliability, while reducing human error and shortening surgical time. However, current methods of guidewire navigation based on Reinforcement Learning (RL) depend on manual demonstration data or magnetic guidance. In this work, we propose an Image-guided Autonomous Guidewire Navigation (IAGN) method. Specifically, we introduce BDA-star, a path planning algorithm with boundary distance constraints, for the trajectory planning of guidewire navigation. We established an IAGN-RL environment where the observations are real-time guidewire feeding images highlighting the position of the guidewire tip and the planned path. We proposed a reward function based on the distances from both the guidewire tip to the planned path and the target to evaluate the agent's actions. Furthermore, in policy network, we employ a pre-trained convolutional neural network to extract features, mitigating stability issues and slow convergence rates associated with direct learning from raw pixels. Experiments conducted on the aortic simulation IAGN platform demonstrated that the proposed method, targeting the left subclavian artery and the brachiocephalic artery, achieved a 100% guidewire navigation success rate, along with reduced movement and retraction distances and trajectories tend to the center of the vessels.
Cross-head mutual Mean-Teaching for semi-supervised medical image segmentation
Oct 16, 2023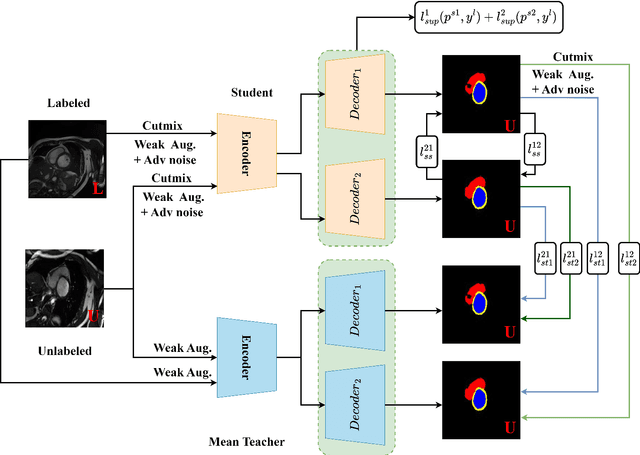
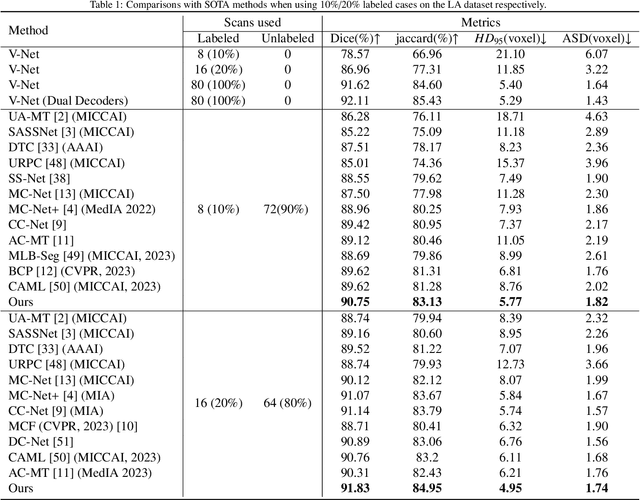
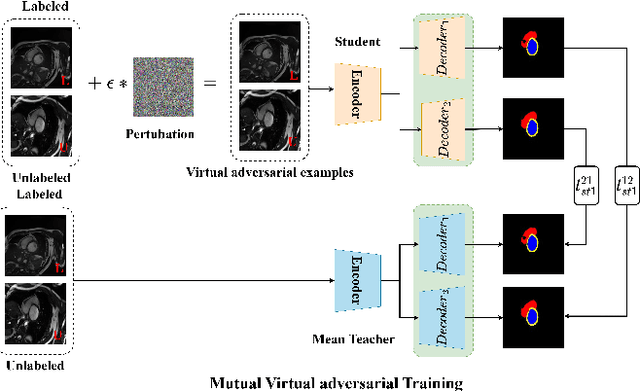
Semi-supervised medical image segmentation (SSMIS) has witnessed substantial advancements by leveraging limited labeled data and abundant unlabeled data. Nevertheless, existing state-of-the-art (SOTA) methods encounter challenges in accurately predicting labels for the unlabeled data, giving rise to disruptive noise during training and susceptibility to erroneous information overfitting. Moreover, applying perturbations to inaccurate predictions further reduces consistent learning. To address these concerns, we propose a novel Cross-head mutual mean-teaching Network (CMMT-Net) incorporated strong-weak data augmentation, thereby benefitting both self-training and consistency learning. Specifically, our CMMT-Net consists of both teacher-student peer networks with a share encoder and dual slightly different decoders, and the pseudo labels generated by one mean teacher head are adopted to supervise the other student branch to achieve a mutual consistency. Furthermore, we propose mutual virtual adversarial training (MVAT) to smooth the decision boundary and enhance feature representations. To diversify the consistency training samples, we employ Cross-Set CutMix strategy, which also helps address distribution mismatch issues. Notably, CMMT-Net simultaneously implements data, feature, and network perturbations, amplifying model diversity and generalization performance. Experimental results on three publicly available datasets indicate that our approach yields remarkable improvements over previous SOTA methods across various semi-supervised scenarios. Code and logs will be available at https://github.com/Leesoon1984/CMMT-Net.
DIAS: A Comprehensive Benchmark for DSA-sequence Intracranial Artery Segmentation
Jun 21, 2023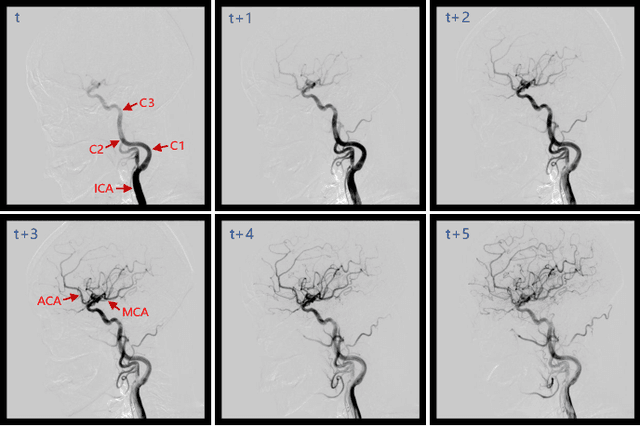
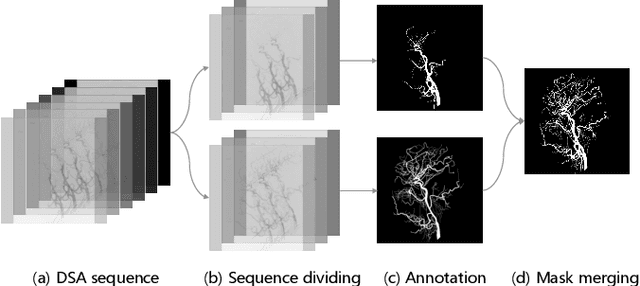
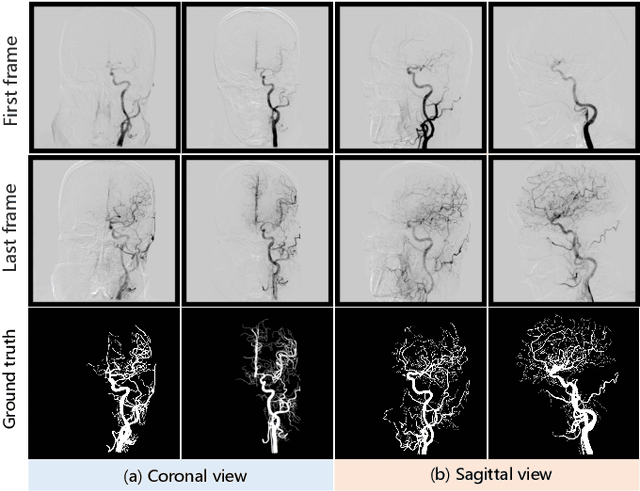
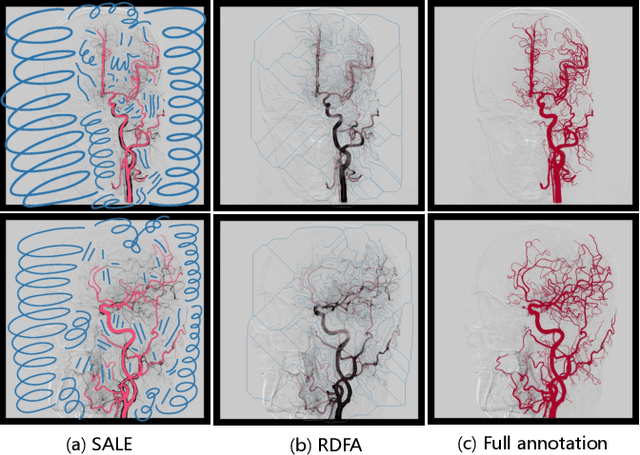
Automatic segmentation of the intracranial artery (IA) in digital subtraction angiography (DSA) sequence is an essential step in diagnosing IA-related diseases and guiding neuro-interventional surgery. However, the lack of publicly available datasets has impeded research in this area. In this paper, we release DIAS, an IA segmentation dataset, consisting of 120 DSA sequences from intracranial interventional therapy. In addition to pixel-wise annotations, this dataset provides two types of scribble annotations for weakly supervised IA segmentation research. We present a comprehensive benchmark for evaluating the performance of this challenging dataset by utilizing fully-, weakly-, and semi-supervised learning approaches. Specifically, we propose a method that incorporates a dimensionality reduction module into a 2D/3D model to achieve vessel segmentation in DSA sequences. For weakly-supervised learning, we propose a scribble learning-based image segmentation framework, SSCR, which comprises scribble supervision and consistency regularization. Furthermore, we introduce a random patch-based self-training framework that utilizes unlabeled DSA sequences to improve segmentation performance. Our extensive experiments on the DIAS dataset demonstrate the effectiveness of these methods as potential baselines for future research and clinical applications.
TIVE: A Toolbox for Identifying Video Instance Segmentation Errors
Oct 17, 2022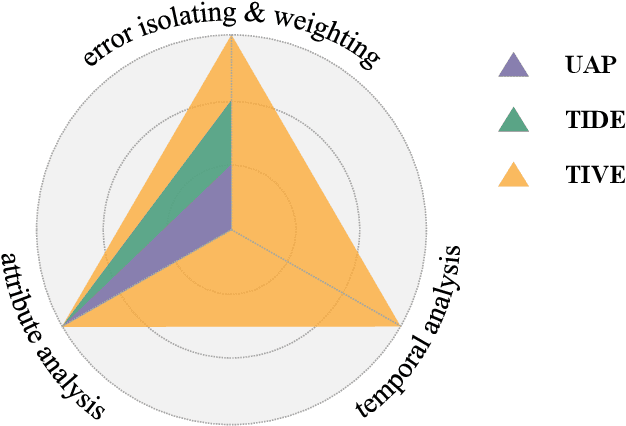
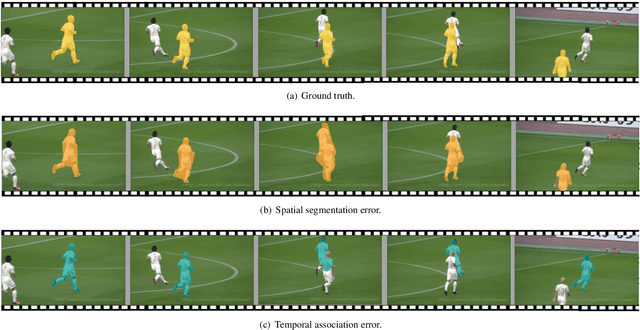
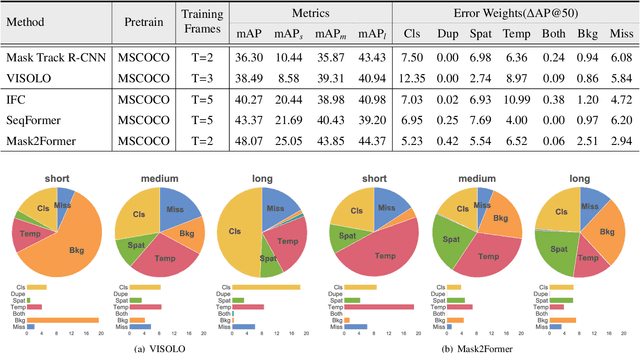
Since first proposed, Video Instance Segmentation(VIS) task has attracted vast researchers' focus on architecture modeling to boost performance. Though great advances achieved in online and offline paradigms, there are still insufficient means to identify model errors and distinguish discrepancies between methods, as well approaches that correctly reflect models' performance in recognizing object instances of various temporal lengths remain barely available. More importantly, as the fundamental model abilities demanded by the task, spatial segmentation and temporal association are still understudied in both evaluation and interaction mechanisms. In this paper, we introduce TIVE, a Toolbox for Identifying Video instance segmentation Errors. By directly operating output prediction files, TIVE defines isolated error types and weights each type's damage to mAP, for the purpose of distinguishing model characters. By decomposing localization quality in spatial-temporal dimensions, model's potential drawbacks on spatial segmentation and temporal association can be revealed. TIVE can also report mAP over instance temporal length for real applications. We conduct extensive experiments by the toolbox to further illustrate how spatial segmentation and temporal association affect each other. We expect the analysis of TIVE can give the researchers more insights, guiding the community to promote more meaningful explorations for video instance segmentation. The proposed toolbox is available at https://github.com/wenhe-jia/TIVE.
FusionStitching: Boosting Memory Intensive Computations for Deep Learning Workloads
Sep 23, 2020

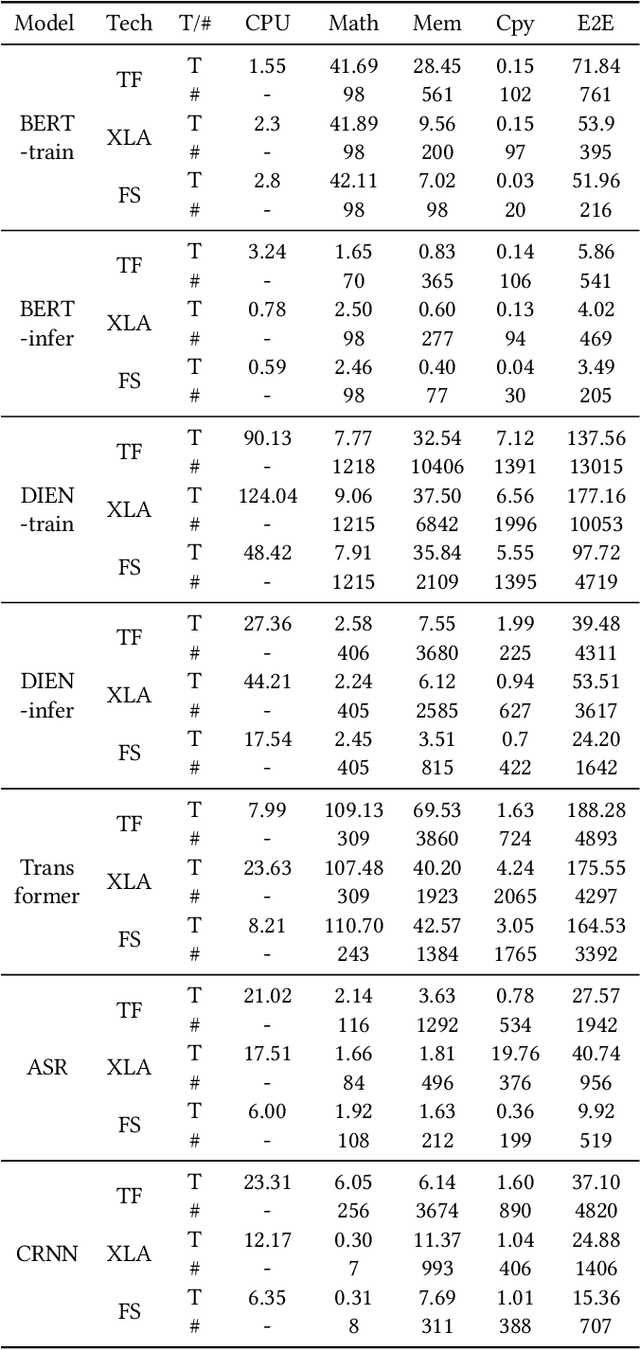

We show in this work that memory intensive computations can result in severe performance problems due to off-chip memory access and CPU-GPU context switch overheads in a wide range of deep learning models. For this problem, current just-in-time kernel fusion and code generation techniques have limitations, such as kernel schedule incompatibilities and rough fusion plan exploration strategies. We propose FusionStitching, a Deep Learning compiler capable of fusing memory intensive operators, with varied data dependencies and non-homogeneous parallelism, into large GPU kernels to reduce global memory access and operation scheduling overhead automatically. FusionStitching explores large fusion spaces to decide optimal fusion plans with considerations of memory access costs, kernel calls and resource usage constraints. We thoroughly study the schemes to stitch operators together for complex scenarios. FusionStitching tunes the optimal stitching scheme just-in-time with a domain-specific cost model efficiently. Experimental results show that FusionStitching can reach up to 2.78x speedup compared to TensorFlow and current state-of-the-art. Besides these experimental results, we integrated our approach into a compiler product and deployed it onto a production cluster for AI workloads with thousands of GPUs. The system has been in operation for more than 4 months and saves 7,000 GPU hours on average for approximately 30,000 tasks per month.