 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIVE: A Toolbox for Identifying Video Instance Segmentation Errors
Oct 17, 2022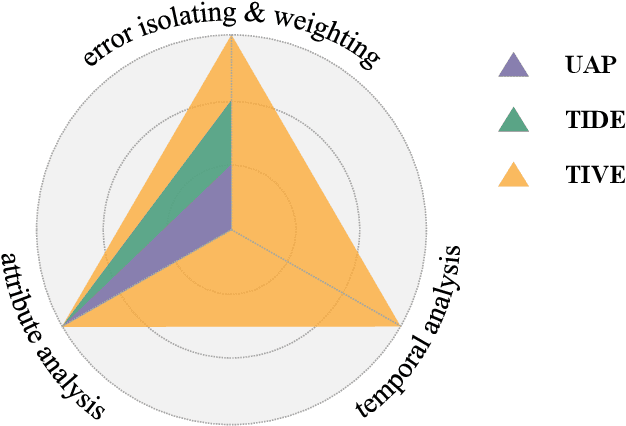
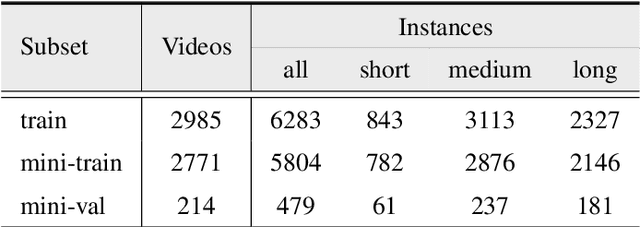
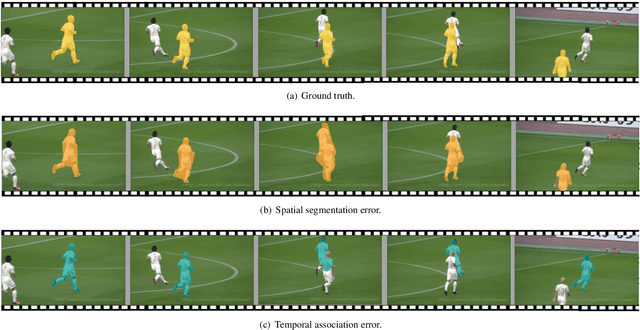
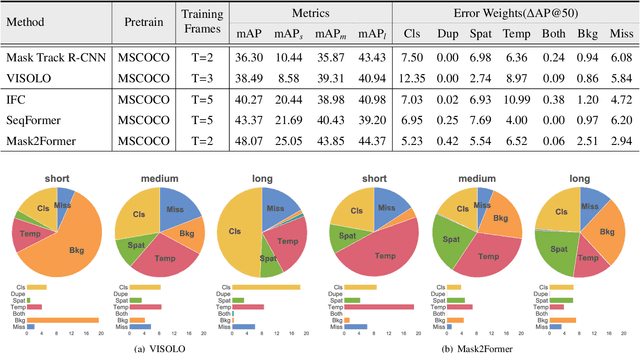
Since first proposed, Video Instance Segmentation(VIS) task has attracted vast researchers' focus on architecture modeling to boost performance. Though great advances achieved in online and offline paradigms, there are still insufficient means to identify model errors and distinguish discrepancies between methods, as well approaches that correctly reflect models' performance in recognizing object instances of various temporal lengths remain barely available. More importantly, as the fundamental model abilities demanded by the task, spatial segmentation and temporal association are still understudied in both evaluation and interaction mechanisms. In this paper, we introduce TIVE, a Toolbox for Identifying Video instance segmentation Errors. By directly operating output prediction files, TIVE defines isolated error types and weights each type's damage to mAP, for the purpose of distinguishing model characters. By decomposing localization quality in spatial-temporal dimensions, model's potential drawbacks on spatial segmentation and temporal association can be revealed. TIVE can also report mAP over instance temporal length for real applications. We conduct extensive experiments by the toolbox to further illustrate how spatial segmentation and temporal association affect each other. We expect the analysis of TIVE can give the researchers more insights, guiding the community to promote more meaningful explorations for video instance segmentation. The proposed toolbox is available at https://github.com/wenhe-jia/TIVE.