 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixLLM: LLM Quantization with Global Mixed-precision between Output-features and Highly-efficient System Design
Dec 19, 2024



Quantization has become one of the most effective methodologies to compress LLMs into smaller size. However, the existing quantization solutions still show limitations of either non-negligible accuracy drop or system inefficiency. In this paper, we make a comprehensive analysis of the general quantization principles on their effect to the triangle of accuracy, memory consumption and system efficiency. We propose MixLLM that explores the new optimization space of mixed-precision quantization between output features based on the insight that different output features matter differently in the model. MixLLM identifies the output features with high salience in the global view rather than within each single layer, effectively assigning the larger bit-width to output features that need it most to achieve good accuracy with low memory consumption. We present the sweet spot of quantization configuration of algorithm-system co-design that leads to high accuracy and system efficiency. To address the system challenge, we design the two-step dequantization to make use of the int8 Tensor Core easily and fast data type conversion to reduce dequantization overhead significantly, and present the software pipeline to overlap the memory access, dequantization and the MatMul to the best. Extensive experiments show that with only 10% more bits, the PPL increasement can be reduced from about 0.5 in SOTA to within 0.2 for Llama 3.1 70B, while on average MMLU-Pro improves by 0.93 over the SOTA of three popular models. In addition to its superior accuracy, MixLLM also achieves state-of-the-art system efficiency.
BatchLLM: Optimizing Large Batched LLM Inference with Global Prefix Sharing and Throughput-oriented Token Batching
Nov 29, 2024Many LLM tasks are performed in large batches or even offline, and the performance indictor for which is throughput. These tasks usually show the characteristic of prefix sharing, where different prompt input can partially show the common prefix. However, the existing LLM inference engines tend to optimize the streaming requests and show limitations of supporting the large batched tasks with the prefix sharing characteristic. The existing solutions use the LRU-based cache to reuse the KV context of common prefix. The KV context that is about to be reused may prematurely be evicted with the implicit cache management. Even if not evicted, the lifetime of the shared KV context is extended since requests sharing the same context are not scheduled together, resulting in larger memory usage. These streaming oriented systems schedule the requests in the first-come-first-serve or similar order. As a result, the requests with larger ratio of decoding steps may be scheduled too late to be able to mix with the prefill chunks to increase the hardware utilization. Besides, the token and request number based batching can limit the size of token-batch, which keeps the GPU from saturating for the iterations dominated by decoding tokens. We propose BatchLLM to address the above problems. BatchLLM explicitly identifies the common prefixes globally. The requests sharing the same prefix will be scheduled together to reuse the KV context the best, which also shrinks the lifetime of common KV memory. BatchLLM reorders the requests and schedules the requests with larger ratio of decoding first to better mix the decoding tokens with the latter prefill chunks and applies memory-centric token batching to enlarge the token-batch sizes, which helps to increase the GPU utilization. Extensive evaluation shows that BatchLLM outperforms vLLM by 1.1x to 2x on a set of microbenchmarks and two typical industry workloads.
FP6-LLM: Efficiently Serving Large Language Models Through FP6-Centric Algorithm-System Co-Design
Jan 25, 2024



Six-bit quantization (FP6) can effectively reduce the size of large language models (LLMs) and preserve the model quality consistently across varied applications. However, existing systems do not provide Tensor Core support for FP6 quantization and struggle to achieve practical performance improvements during LLM inference. It is challenging to support FP6 quantization on GPUs due to (1) unfriendly memory access of model weights with irregular bit-width and (2) high runtime overhead of weight de-quantization. To address these problems, we propose TC-FPx, the first full-stack GPU kernel design scheme with unified Tensor Core support of float-point weights for various quantization bit-width. We integrate TC-FPx kernel into an existing inference system, providing new end-to-end support (called FP6-LLM) for quantized LLM inference, where better trade-offs between inference cost and model quality are achieved. Experiments show that FP6-LLM enables the inference of LLaMA-70b using only a single GPU, achieving 1.69x-2.65x higher normalized inference throughput than the FP16 baseline. The source code will be publicly available soon.
ZeroQuant(4+2): Redefining LLMs Quantization with a New FP6-Centric Strategy for Diverse Generative Tasks
Dec 18, 2023



This study examines 4-bit quantization methods like GPTQ in large language models (LLMs), highlighting GPTQ's overfitting and limited enhancement in Zero-Shot tasks. While prior works merely focusing on zero-shot measurement, we extend task scope to more generative categories such as code generation and abstractive summarization, in which we found that INT4 quantization can significantly underperform. However, simply shifting to higher precision formats like FP6 has been particularly challenging, thus overlooked, due to poor performance caused by the lack of sophisticated integration and system acceleration strategies on current AI hardware. Our results show that FP6, even with a coarse-grain quantization scheme, performs robustly across various algorithms and tasks, demonstrating its superiority in accuracy and versatility. Notably, with the FP6 quantization, \codestar-15B model performs comparably to its FP16 counterpart in code generation, and for smaller models like the 406M it closely matches their baselines in summarization. Neither can be achieved by INT4. To better accommodate various AI hardware and achieve the best system performance, we propose a novel 4+2 design for FP6 to achieve similar latency to the state-of-the-art INT4 fine-grain quantization. With our design, FP6 can become a promising solution to the current 4-bit quantization methods used in LLMs.
Flash-LLM: Enabling Cost-Effective and Highly-Efficient Large Generative Model Inference with Unstructured Sparsity
Sep 19, 2023



With the fast growth of parameter size, it becomes increasingly challenging to deploy large generative models as they typically require large GPU memory consumption and massive computation. Unstructured model pruning has been a common approach to reduce both GPU memory footprint and the overall computation while retaining good model accuracy. However, the existing solutions do not provide a highly-efficient support for handling unstructured sparsity on modern GPUs, especially on the highly-structured Tensor Core hardware. Therefore, we propose Flash-LLM for enabling low-cost and highly-efficient large generative model inference with the sophisticated support of unstructured sparsity on high-performance but highly restrictive Tensor Cores. Based on our key observation that the main bottleneck of generative model inference is the several skinny matrix multiplications for which Tensor Cores would be significantly under-utilized due to low computational intensity, we propose a general Load-as-Sparse and Compute-as-Dense methodology for unstructured sparse matrix multiplication. The basic insight is to address the significant memory bandwidth bottleneck while tolerating redundant computations that are not critical for end-to-end performance on Tensor Cores. Based on this, we design an effective software framework for Tensor Core based unstructured SpMM, leveraging on-chip resources for efficient sparse data extraction and computation/memory-access overlapping. At SpMM kernel level, Flash-LLM significantly outperforms the state-of-the-art library, i.e., Sputnik and SparTA by an average of 2.9x and 1.5x, respectively. At end-to-end framework level on OPT-30B/66B/175B models, for tokens per GPU-second, Flash-LLM achieves up to 3.8x and 3.6x improvement over DeepSpeed and FasterTransformer, respectively, with significantly lower inference cost.
Auto-Parallelizing Large Models with Rhino: A Systematic Approach on Production AI Platform
Feb 16, 2023



We present Rhino, a system for accelerating tensor programs with automatic parallelization on AI platform for real production environment. It transforms a tensor program written for a single device into an equivalent distributed program that is capable of scaling up to thousands of devices with no user configuration. Rhino firstly works on a semantically independent intermediate representation of tensor programs, which facilitates its generalization to unprecedented applications. Additionally, it implements a task-oriented controller and a distributed runtime for optimal performance. Rhino explores on a complete and systematic parallelization strategy space that comprises all the paradigms commonly employed in deep learning (DL), in addition to strided partitioning and pipeline parallelism on non-linear models. Aiming to efficiently search for a near-optimal parallel execution plan, our analysis of production clusters reveals general heuristics to speed up the strategy search. On top of it, two optimization levels are designed to offer users flexible trade-offs between the search time and strategy quality. Our experiments demonstrate that Rhino can not only re-discover the expert-crafted strategies of classic, research and production DL models, but also identify novel parallelization strategies which surpass existing systems for novel models.
FusionStitching: Boosting Memory Intensive Computations for Deep Learning Workloads
Sep 23, 2020

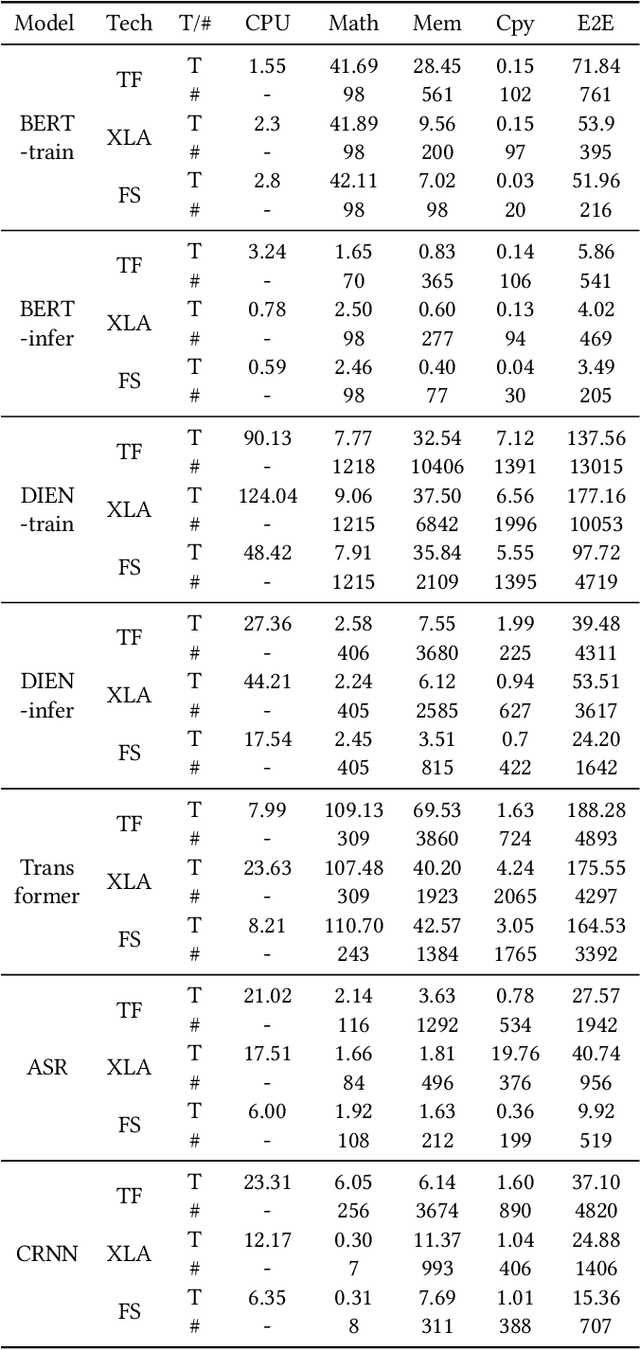

We show in this work that memory intensive computations can result in severe performance problems due to off-chip memory access and CPU-GPU context switch overheads in a wide range of deep learning models. For this problem, current just-in-time kernel fusion and code generation techniques have limitations, such as kernel schedule incompatibilities and rough fusion plan exploration strategies. We propose FusionStitching, a Deep Learning compiler capable of fusing memory intensive operators, with varied data dependencies and non-homogeneous parallelism, into large GPU kernels to reduce global memory access and operation scheduling overhead automatically. FusionStitching explores large fusion spaces to decide optimal fusion plans with considerations of memory access costs, kernel calls and resource usage constraints. We thoroughly study the schemes to stitch operators together for complex scenarios. FusionStitching tunes the optimal stitching scheme just-in-time with a domain-specific cost model efficiently. Experimental results show that FusionStitching can reach up to 2.78x speedup compared to TensorFlow and current state-of-the-art. Besides these experimental results, we integrated our approach into a compiler product and deployed it onto a production cluster for AI workloads with thousands of GPUs. The system has been in operation for more than 4 months and saves 7,000 GPU hours on average for approximately 30,000 tasks per month.
Auto-MAP: A DQN Framework for Exploring Distributed Execution Plans for DNN Workloads
Jul 08, 2020



The last decade has witnessed growth in the computational requirements for training deep neural networks. Current approaches (e.g., data/model parallelism, pipeline parallelism) parallelize training tasks onto multiple devices. However, these approaches always rely on specific deep learning frameworks and requires elaborate manual design, which make it difficult to maintain and share between different type of models. In this paper, we propose Auto-MAP, a framework for exploring distributed execution plans for DNN workloads, which can automatically discovering fast parallelization strategies through reinforcement learning on IR level of deep learning models. Efficient exploration remains a major challenge for reinforcement learning. We leverage DQN with task-specific pruning strategies to help efficiently explore the search space including optimized strategies. Our evaluation shows that Auto-MAP can find the optimal solution in two hours, while achieving better throughput on several NLP and convolution models.