 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAC: Stabilizing Asynchronous RL Training for LLMs via Gradient Alignment Control
Mar 02, 2026Asynchronous execution is essential for scaling reinforcement learning (RL) to modern large model workloads, including large language models and AI agents, but it can fundamentally alter RL optimization behavior. While prior work on asynchronous RL focuses on training throughput and distributional correction, we show that naively applying asynchrony to policy-gradient updates can induce qualitatively different training dynamics and lead to severe training instability. Through systematic empirical and theoretical analysis, we identify a key signature of this instability: asynchronous training exhibits persistently high cosine similarity between consecutive policy gradients, in contrast to the near-orthogonal updates observed under synchronized training. This stale-aligned gradient effect amplifies correlated updates and increases the risk of overshooting and divergence. Motivated by this observation, we propose GRADIENT ALIGNMENT CONTROL(GAC), a simple dynamics-aware stabilization method that regulates asynchronous RL progress along stale-aligned directions via gradient projection. We establish convergence guarantees under bounded staleness and demonstrate empirically that GAC recovers stable, on-policy training dynamics and matches synchronized baselines even at high staleness.
SRDiffusion: Accelerate Video Diffusion Inference via Sketching-Rendering Cooperation
May 25, 2025Leveraging the diffusion transformer (DiT) architecture, models like Sora, CogVideoX and Wan have achieved remarkable progress in text-to-video, image-to-video, and video editing tasks. Despite these advances, diffusion-based video generation remains computationally intensive, especially for high-resolution, long-duration videos. Prior work accelerates its inference by skipping computation, usually at the cost of severe quality degradation. In this paper, we propose SRDiffusion, a novel framework that leverages collaboration between large and small models to reduce inference cost. The large model handles high-noise steps to ensure semantic and motion fidelity (Sketching), while the smaller model refines visual details in low-noise steps (Rendering). Experimental results demonstrate that our method outperforms existing approaches, over 3$\times$ speedup for Wan with nearly no quality loss for VBench, and 2$\times$ speedup for CogVideoX. Our method is introduced as a new direction orthogonal to existing acceleration strategies, offering a practical solution for scalable video generation.
Auto-Parallelizing Large Models with Rhino: A Systematic Approach on Production AI Platform
Feb 16, 2023



We present Rhino, a system for accelerating tensor programs with automatic parallelization on AI platform for real production environment. It transforms a tensor program written for a single device into an equivalent distributed program that is capable of scaling up to thousands of devices with no user configuration. Rhino firstly works on a semantically independent intermediate representation of tensor programs, which facilitates its generalization to unprecedented applications. Additionally, it implements a task-oriented controller and a distributed runtime for optimal performance. Rhino explores on a complete and systematic parallelization strategy space that comprises all the paradigms commonly employed in deep learning (DL), in addition to strided partitioning and pipeline parallelism on non-linear models. Aiming to efficiently search for a near-optimal parallel execution plan, our analysis of production clusters reveals general heuristics to speed up the strategy search. On top of it, two optimization levels are designed to offer users flexible trade-offs between the search time and strategy quality. Our experiments demonstrate that Rhino can not only re-discover the expert-crafted strategies of classic, research and production DL models, but also identify novel parallelization strategies which surpass existing systems for novel models.
Expediting Distributed DNN Training with Device Topology-Aware Graph Deployment
Feb 13, 2023



This paper presents TAG, an automatic system to derive optimized DNN training graph and its deployment onto any device topology, for expedited training in device- and topology- heterogeneous ML clusters. We novelly combine both the DNN computation graph and the device topology graph as input to a graph neural network (GNN), and join the GNN with a search-based method to quickly identify optimized distributed training strategies. To reduce communication in a heterogeneous cluster, we further explore a lossless gradient compression technique and solve a combinatorial optimization problem to automatically apply the technique for training time minimization. We evaluate TAG with various representative DNN models and device topologies, showing that it can achieve up to 4.56x training speed-up as compared to existing schemes. TAG can produce efficient deployment strategies for both unseen DNN models and unseen device topologies, without heavy fine-tuning.
FusionStitching: Boosting Memory Intensive Computations for Deep Learning Workloads
Sep 23, 2020

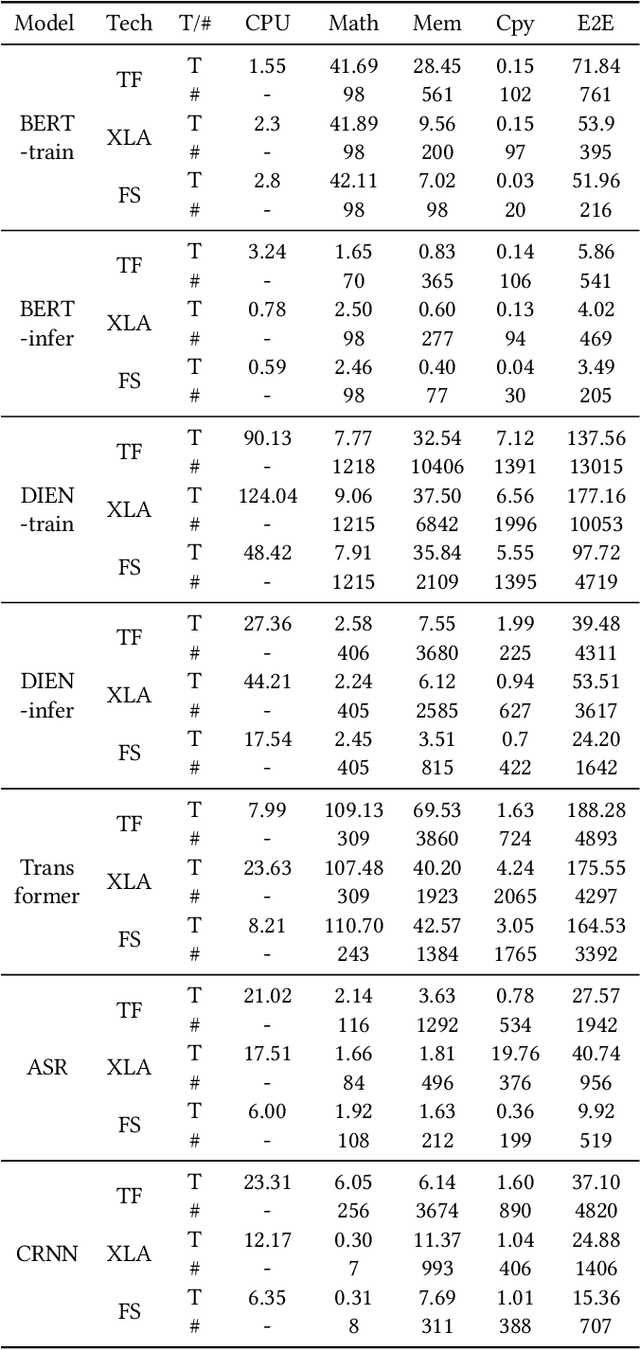

We show in this work that memory intensive computations can result in severe performance problems due to off-chip memory access and CPU-GPU context switch overheads in a wide range of deep learning models. For this problem, current just-in-time kernel fusion and code generation techniques have limitations, such as kernel schedule incompatibilities and rough fusion plan exploration strategies. We propose FusionStitching, a Deep Learning compiler capable of fusing memory intensive operators, with varied data dependencies and non-homogeneous parallelism, into large GPU kernels to reduce global memory access and operation scheduling overhead automatically. FusionStitching explores large fusion spaces to decide optimal fusion plans with considerations of memory access costs, kernel calls and resource usage constraints. We thoroughly study the schemes to stitch operators together for complex scenarios. FusionStitching tunes the optimal stitching scheme just-in-time with a domain-specific cost model efficiently. Experimental results show that FusionStitching can reach up to 2.78x speedup compared to TensorFlow and current state-of-the-art. Besides these experimental results, we integrated our approach into a compiler product and deployed it onto a production cluster for AI workloads with thousands of GPUs. The system has been in operation for more than 4 months and saves 7,000 GPU hours on average for approximately 30,000 tasks per month.