 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntrospective Diffusion Language Models
Apr 13, 2026Diffusion language models promise parallel generation, yet still lag behind autoregressive (AR) models in quality. We stem this gap to a failure of introspective consistency: AR models agree with their own generations, while DLMs often do not. We define the introspective acceptance rate, which measures whether a model accepts its previously generated tokens. This reveals why AR training has a structural advantage: causal masking and logit shifting implicitly enforce introspective consistency. Motivated by this observation, we introduce Introspective Diffusion Language Model (I-DLM), a paradigm that retains diffusion-style parallel decoding while inheriting the introspective consistency of AR training. I-DLM uses a novel introspective strided decoding (ISD) algorithm, which enables the model to verify previously generated tokens while advancing new ones in the same forward pass. From a systems standpoint, we build I-DLM inference engine on AR-inherited optimizations and further customize it with a stationary-batch scheduler. To the best of our knowledge, I-DLM is the first DLM to match the quality of its same-scale AR counterpart while outperforming prior DLMs in both model quality and practical serving efficiency across 15 benchmarks. It reaches 69.6 on AIME-24 and 45.7 on LiveCodeBench-v6, exceeding LLaDA-2.1-mini (16B) by more than 26 and 15 points, respectively. Beyond quality, I-DLM is designed for the growing demand of large-concurrency serving, delivering about 3x higher throughput than prior state-of-the-art DLMs.
FP6-LLM: Efficiently Serving Large Language Models Through FP6-Centric Algorithm-System Co-Design
Jan 25, 2024



Six-bit quantization (FP6) can effectively reduce the size of large language models (LLMs) and preserve the model quality consistently across varied applications. However, existing systems do not provide Tensor Core support for FP6 quantization and struggle to achieve practical performance improvements during LLM inference. It is challenging to support FP6 quantization on GPUs due to (1) unfriendly memory access of model weights with irregular bit-width and (2) high runtime overhead of weight de-quantization. To address these problems, we propose TC-FPx, the first full-stack GPU kernel design scheme with unified Tensor Core support of float-point weights for various quantization bit-width. We integrate TC-FPx kernel into an existing inference system, providing new end-to-end support (called FP6-LLM) for quantized LLM inference, where better trade-offs between inference cost and model quality are achieved. Experiments show that FP6-LLM enables the inference of LLaMA-70b using only a single GPU, achieving 1.69x-2.65x higher normalized inference throughput than the FP16 baseline. The source code will be publicly available soon.
Flash-LLM: Enabling Cost-Effective and Highly-Efficient Large Generative Model Inference with Unstructured Sparsity
Sep 19, 2023



With the fast growth of parameter size, it becomes increasingly challenging to deploy large generative models as they typically require large GPU memory consumption and massive computation. Unstructured model pruning has been a common approach to reduce both GPU memory footprint and the overall computation while retaining good model accuracy. However, the existing solutions do not provide a highly-efficient support for handling unstructured sparsity on modern GPUs, especially on the highly-structured Tensor Core hardware. Therefore, we propose Flash-LLM for enabling low-cost and highly-efficient large generative model inference with the sophisticated support of unstructured sparsity on high-performance but highly restrictive Tensor Cores. Based on our key observation that the main bottleneck of generative model inference is the several skinny matrix multiplications for which Tensor Cores would be significantly under-utilized due to low computational intensity, we propose a general Load-as-Sparse and Compute-as-Dense methodology for unstructured sparse matrix multiplication. The basic insight is to address the significant memory bandwidth bottleneck while tolerating redundant computations that are not critical for end-to-end performance on Tensor Cores. Based on this, we design an effective software framework for Tensor Core based unstructured SpMM, leveraging on-chip resources for efficient sparse data extraction and computation/memory-access overlapping. At SpMM kernel level, Flash-LLM significantly outperforms the state-of-the-art library, i.e., Sputnik and SparTA by an average of 2.9x and 1.5x, respectively. At end-to-end framework level on OPT-30B/66B/175B models, for tokens per GPU-second, Flash-LLM achieves up to 3.8x and 3.6x improvement over DeepSpeed and FasterTransformer, respectively, with significantly lower inference cost.
Randomness In Neural Network Training: Characterizing The Impact of Tooling
Jun 22, 2021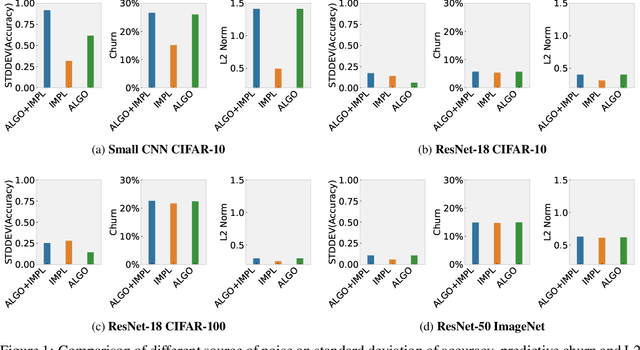

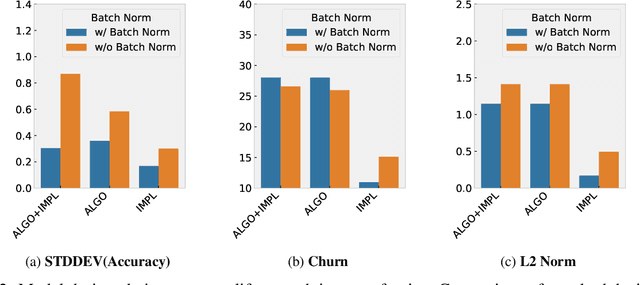
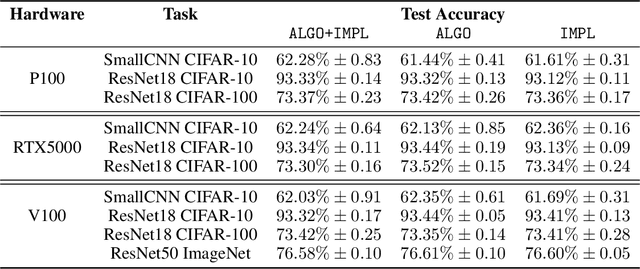
The quest for determinism in machine learning has disproportionately focused on characterizing the impact of noise introduced by algorithmic design choices. In this work, we address a less well understood and studied question: how does our choice of tooling introduce randomness to deep neural network training. We conduct large scale experiments across different types of hardware, accelerators, state of art networks, and open-source datasets, to characterize how tooling choices contribute to the level of non-determinism in a system, the impact of said non-determinism, and the cost of eliminating different sources of noise. Our findings are surprising, and suggest that the impact of non-determinism in nuanced. While top-line metrics such as top-1 accuracy are not noticeably impacted, model performance on certain parts of the data distribution is far more sensitive to the introduction of randomness. Our results suggest that deterministic tooling is critical for AI safety. However, we also find that the cost of ensuring determinism varies dramatically between neural network architectures and hardware types, e.g., with overhead up to $746\%$, $241\%$, and $196\%$ on a spectrum of widely used GPU accelerator architectures, relative to non-deterministic training. The source code used in this paper is available at https://github.com/usyd-fsalab/NeuralNetworkRandomness.
An Efficient End-to-End Deep Learning Training Framework via Fine-Grained Pattern-Based Pruning
Nov 20, 2020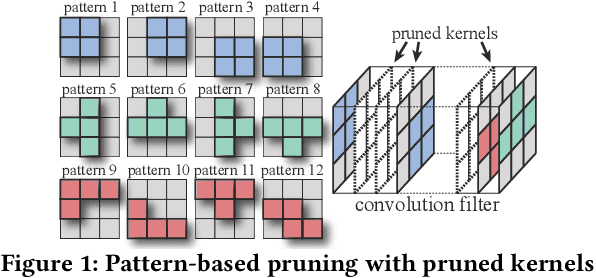
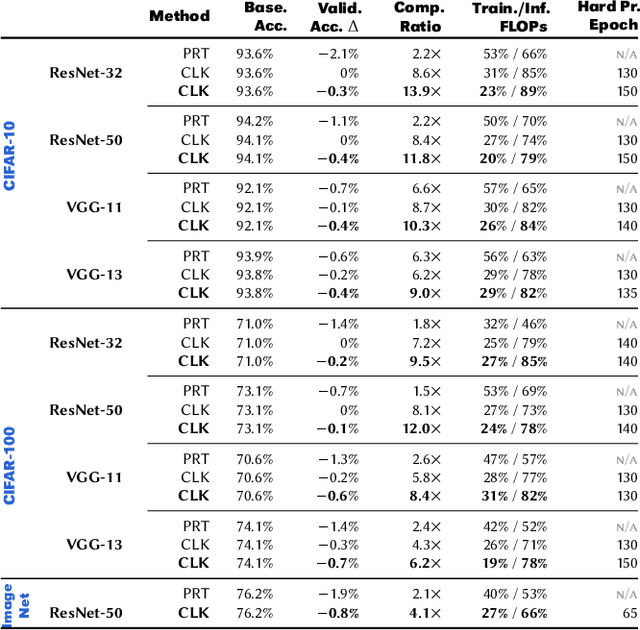
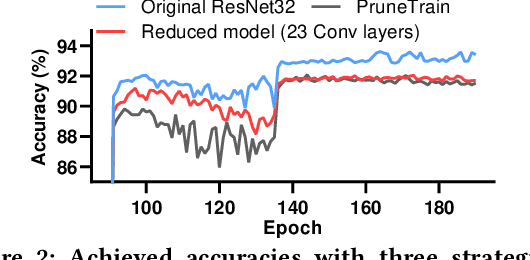
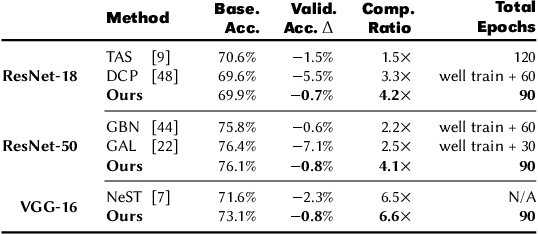
Convolutional neural networks (CNNs) are becoming increasingly deeper, wider, and non-linear because of the growing demand on prediction accuracy and analysis quality. The wide and deep CNNs, however, require a large amount of computing resources and processing time. Many previous works have studied model pruning to improve inference performance, but little work has been done for effectively reducing training cost. In this paper, we propose ClickTrain: an efficient and accurate end-to-end training and pruning framework for CNNs. Different from the existing pruning-during-training work, ClickTrain provides higher model accuracy and compression ratio via fine-grained architecture-preserving pruning. By leveraging pattern-based pruning with our proposed novel accurate weight importance estimation, dynamic pattern generation and selection, and compiler-assisted computation optimizations, ClickTrain generates highly accurate and fast pruned CNN models for direct deployment without any time overhead, compared with the baseline training. ClickTrain also reduces the end-to-end time cost of the state-of-the-art pruning-after-training methods by up to about 67% with comparable accuracy and compression ratio. Moreover, compared with the state-of-the-art pruning-during-training approach, ClickTrain reduces the accuracy drop by up to 2.1% and improves the compression ratio by up to 2.2X on the tested datasets, under similar limited training time.