 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFP6-LLM: Efficiently Serving Large Language Models Through FP6-Centric Algorithm-System Co-Design
Jan 25, 2024



Six-bit quantization (FP6) can effectively reduce the size of large language models (LLMs) and preserve the model quality consistently across varied applications. However, existing systems do not provide Tensor Core support for FP6 quantization and struggle to achieve practical performance improvements during LLM inference. It is challenging to support FP6 quantization on GPUs due to (1) unfriendly memory access of model weights with irregular bit-width and (2) high runtime overhead of weight de-quantization. To address these problems, we propose TC-FPx, the first full-stack GPU kernel design scheme with unified Tensor Core support of float-point weights for various quantization bit-width. We integrate TC-FPx kernel into an existing inference system, providing new end-to-end support (called FP6-LLM) for quantized LLM inference, where better trade-offs between inference cost and model quality are achieved. Experiments show that FP6-LLM enables the inference of LLaMA-70b using only a single GPU, achieving 1.69x-2.65x higher normalized inference throughput than the FP16 baseline. The source code will be publicly available soon.
ZeroQuant(4+2): Redefining LLMs Quantization with a New FP6-Centric Strategy for Diverse Generative Tasks
Dec 18, 2023



This study examines 4-bit quantization methods like GPTQ in large language models (LLMs), highlighting GPTQ's overfitting and limited enhancement in Zero-Shot tasks. While prior works merely focusing on zero-shot measurement, we extend task scope to more generative categories such as code generation and abstractive summarization, in which we found that INT4 quantization can significantly underperform. However, simply shifting to higher precision formats like FP6 has been particularly challenging, thus overlooked, due to poor performance caused by the lack of sophisticated integration and system acceleration strategies on current AI hardware. Our results show that FP6, even with a coarse-grain quantization scheme, performs robustly across various algorithms and tasks, demonstrating its superiority in accuracy and versatility. Notably, with the FP6 quantization, \codestar-15B model performs comparably to its FP16 counterpart in code generation, and for smaller models like the 406M it closely matches their baselines in summarization. Neither can be achieved by INT4. To better accommodate various AI hardware and achieve the best system performance, we propose a novel 4+2 design for FP6 to achieve similar latency to the state-of-the-art INT4 fine-grain quantization. With our design, FP6 can become a promising solution to the current 4-bit quantization methods used in LLMs.
Flash-LLM: Enabling Cost-Effective and Highly-Efficient Large Generative Model Inference with Unstructured Sparsity
Sep 19, 2023



With the fast growth of parameter size, it becomes increasingly challenging to deploy large generative models as they typically require large GPU memory consumption and massive computation. Unstructured model pruning has been a common approach to reduce both GPU memory footprint and the overall computation while retaining good model accuracy. However, the existing solutions do not provide a highly-efficient support for handling unstructured sparsity on modern GPUs, especially on the highly-structured Tensor Core hardware. Therefore, we propose Flash-LLM for enabling low-cost and highly-efficient large generative model inference with the sophisticated support of unstructured sparsity on high-performance but highly restrictive Tensor Cores. Based on our key observation that the main bottleneck of generative model inference is the several skinny matrix multiplications for which Tensor Cores would be significantly under-utilized due to low computational intensity, we propose a general Load-as-Sparse and Compute-as-Dense methodology for unstructured sparse matrix multiplication. The basic insight is to address the significant memory bandwidth bottleneck while tolerating redundant computations that are not critical for end-to-end performance on Tensor Cores. Based on this, we design an effective software framework for Tensor Core based unstructured SpMM, leveraging on-chip resources for efficient sparse data extraction and computation/memory-access overlapping. At SpMM kernel level, Flash-LLM significantly outperforms the state-of-the-art library, i.e., Sputnik and SparTA by an average of 2.9x and 1.5x, respectively. At end-to-end framework level on OPT-30B/66B/175B models, for tokens per GPU-second, Flash-LLM achieves up to 3.8x and 3.6x improvement over DeepSpeed and FasterTransformer, respectively, with significantly lower inference cost.
Shift-BNN: Highly-Efficient Probabilistic Bayesian Neural Network Training via Memory-Friendly Pattern Retrieving
Oct 07, 2021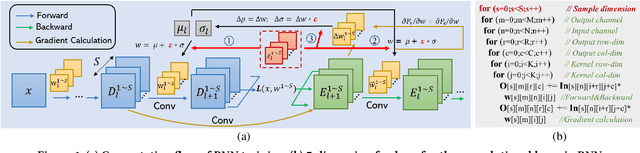
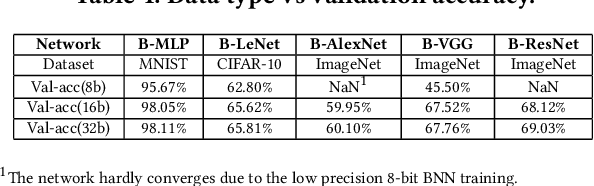
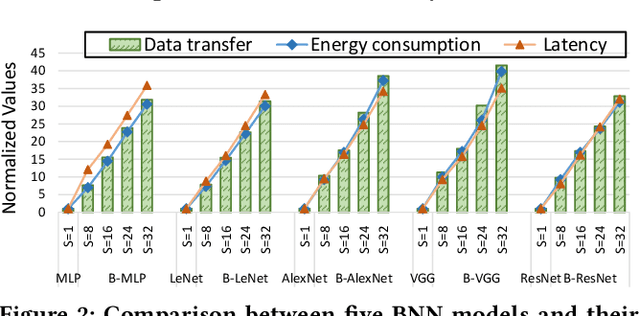
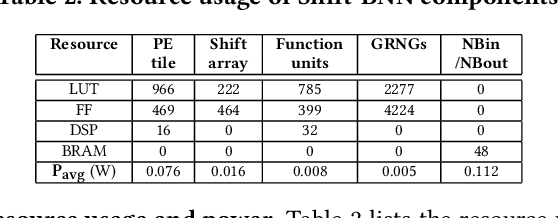
Bayesian Neural Networks (BNNs) that possess a property of uncertainty estimation have been increasingly adopted in a wide range of safety-critical AI applications which demand reliable and robust decision making, e.g., self-driving, rescue robots, medical image diagnosis. The training procedure of a probabilistic BNN model involves training an ensemble of sampled DNN models, which induces orders of magnitude larger volume of data movement than training a single DNN model. In this paper, we reveal that the root cause for BNN training inefficiency originates from the massive off-chip data transfer by Gaussian Random Variables (GRVs). To tackle this challenge, we propose a novel design that eliminates all the off-chip data transfer by GRVs through the reversed shifting of Linear Feedback Shift Registers (LFSRs) without incurring any training accuracy loss. To efficiently support our LFSR reversion strategy at the hardware level, we explore the design space of the current DNN accelerators and identify the optimal computation mapping scheme to best accommodate our strategy. By leveraging this finding, we design and prototype the first highly efficient BNN training accelerator, named Shift-BNN, that is low-cost and scalable. Extensive evaluation on five representative BNN models demonstrates that Shift-BNN achieves an average of 4.9x (up to 10.8x) boost in energy efficiency and 1.6x (up to 2.8x) speedup over the baseline DNN training accelerator.