 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen RL Meets Adaptive Speculative Training: A Unified Training-Serving System
Feb 06, 2026Speculative decoding can significantly accelerate LLM serving, yet most deployments today disentangle speculator training from serving, treating speculator training as a standalone offline modeling problem. We show that this decoupled formulation introduces substantial deployment and adaptation lag: (1) high time-to-serve, since a speculator must be trained offline for a considerable period before deployment; (2) delayed utility feedback, since the true end-to-end decoding speedup is only known after training and cannot be inferred reliably from acceptance rate alone due to model-architecture and system-level overheads; and (3) domain-drift degradation, as the target model is repurposed to new domains and the speculator becomes stale and less effective. To address these issues, we present Aurora, a unified training-serving system that closes the loop by continuously learning a speculator directly from live inference traces. Aurora reframes online speculator learning as an asynchronous reinforcement-learning problem: accepted tokens provide positive feedback, while rejected speculator proposals provide implicit negative feedback that we exploit to improve sample efficiency. Our design integrates an SGLang-based inference server with an asynchronous training server, enabling hot-swapped speculator updates without service interruption. Crucially, Aurora supports day-0 deployment: a speculator can be served immediately and rapidly adapted to live traffic, improving system performance while providing immediate utility feedback. Across experiments, Aurora achieves a 1.5x day-0 speedup on recently released frontier models (e.g., MiniMax M2.1 229B and Qwen3-Coder-Next 80B). Aurora also adapts effectively to distribution shifts in user traffic, delivering an additional 1.25x speedup over a well-trained but static speculator on widely used models (e.g., Qwen3 and Llama3).
Understanding and Steering the Cognitive Behaviors of Reasoning Models at Test-Time
Dec 31, 2025Large Language Models (LLMs) often rely on long chain-of-thought (CoT) reasoning to solve complex tasks. While effective, these trajectories are frequently inefficient, leading to high latency from excessive token generation, or unstable reasoning that alternates between underthinking (shallow, inconsistent steps) and overthinking (repetitive, verbose reasoning). In this work, we study the structure of reasoning trajectories and uncover specialized attention heads that correlate with distinct cognitive behaviors such as verification and backtracking. By lightly intervening on these heads at inference time, we can steer the model away from inefficient modes. Building on this insight, we propose CREST, a training-free method for Cognitive REasoning Steering at Test-time. CREST has two components: (1) an offline calibration step that identifies cognitive heads and derives head-specific steering vectors, and (2) an inference-time procedure that rotates hidden representations to suppress components along those vectors. CREST adaptively suppresses unproductive reasoning behaviors, yielding both higher accuracy and lower computational cost. Across diverse reasoning benchmarks and models, CREST improves accuracy by up to 17.5% while reducing token usage by 37.6%, offering a simple and effective pathway to faster, more reliable LLM reasoning.
Ladder-residual: parallelism-aware architecture for accelerating large model inference with communication overlapping
Jan 11, 2025



Large language model inference is both memory-intensive and time-consuming, often requiring distributed algorithms to efficiently scale. Various model parallelism strategies are used in multi-gpu training and inference to partition computation across multiple devices, reducing memory load and computation time. However, using model parallelism necessitates communication of information between GPUs, which has been a major bottleneck and limits the gains obtained by scaling up the number of devices. We introduce Ladder Residual, a simple architectural modification applicable to all residual-based models that enables straightforward overlapping that effectively hides the latency of communication. Our insight is that in addition to systems optimization, one can also redesign the model architecture to decouple communication from computation. While Ladder Residual can allow communication-computation decoupling in conventional parallelism patterns, we focus on Tensor Parallelism in this paper, which is particularly bottlenecked by its heavy communication. For a Transformer model with 70B parameters, applying Ladder Residual to all its layers can achieve 30% end-to-end wall clock speed up at inference time with TP sharding over 8 devices. We refer the resulting Transformer model as the Ladder Transformer. We train a 1B and 3B Ladder Transformer from scratch and observe comparable performance to a standard dense transformer baseline. We also show that it is possible to convert parts of the Llama-3.1 8B model to our Ladder Residual architecture with minimal accuracy degradation by only retraining for 3B tokens.
CorDA: Context-Oriented Decomposition Adaptation of Large Language Models
Jun 07, 2024



Current parameter-efficient fine-tuning (PEFT) methods build adapters without considering the context of downstream task to learn, or the context of important knowledge to maintain. As a result, there is often a performance gap compared to full-parameter finetuning, and meanwhile the finetuned model suffers from catastrophic forgetting of the pre-trained world knowledge. In this paper, we propose CorDA, a Context-oriented Decomposition Adaptation method that builds learnable adapters from weight decomposition oriented by the context of downstream task or world knowledge. Concretely, we collect a few data samples, and perform singular value decomposition for each linear layer of a pre-trained LLM multiplied by the covariance matrix of the input activation using these samples. By doing so, the context of the representative samples is captured through deciding the factorizing orientation. Our method enables two options, the knowledge-preserved adaptation and the instruction-previewed adaptation. For the former, we use question-answering samples to obtain the covariance matrices, and use the decomposed components with the smallest $r$ singular values to initialize a learnable adapter, with the others frozen such that the world knowledge is better preserved. For the latter, we use the instruction data from the finetuning task, such as math or coding, to orientate the decomposition and train the largest $r$ components that capture the main characteristics of the task to learn. We conduct extensive experiments on Math, Code, and Instruction Following tasks. Our knowledge-preserved adaptation not only achieves better performance than LoRA on finetuning tasks, but also mitigates the forgetting of world knowledge. Our instruction-previewed adaptation is able to further enhance the finetuning performance, surpassing full-parameter finetuning and the state-of-the-art PEFT methods.
FP6-LLM: Efficiently Serving Large Language Models Through FP6-Centric Algorithm-System Co-Design
Jan 25, 2024



Six-bit quantization (FP6) can effectively reduce the size of large language models (LLMs) and preserve the model quality consistently across varied applications. However, existing systems do not provide Tensor Core support for FP6 quantization and struggle to achieve practical performance improvements during LLM inference. It is challenging to support FP6 quantization on GPUs due to (1) unfriendly memory access of model weights with irregular bit-width and (2) high runtime overhead of weight de-quantization. To address these problems, we propose TC-FPx, the first full-stack GPU kernel design scheme with unified Tensor Core support of float-point weights for various quantization bit-width. We integrate TC-FPx kernel into an existing inference system, providing new end-to-end support (called FP6-LLM) for quantized LLM inference, where better trade-offs between inference cost and model quality are achieved. Experiments show that FP6-LLM enables the inference of LLaMA-70b using only a single GPU, achieving 1.69x-2.65x higher normalized inference throughput than the FP16 baseline. The source code will be publicly available soon.
DeepSpeed4Science Initiative: Enabling Large-Scale Scientific Discovery through Sophisticated AI System Technologies
Oct 11, 2023



In the upcoming decade, deep learning may revolutionize the natural sciences, enhancing our capacity to model and predict natural occurrences. This could herald a new era of scientific exploration, bringing significant advancements across sectors from drug development to renewable energy. To answer this call, we present DeepSpeed4Science initiative (deepspeed4science.ai) which aims to build unique capabilities through AI system technology innovations to help domain experts to unlock today's biggest science mysteries. By leveraging DeepSpeed's current technology pillars (training, inference and compression) as base technology enablers, DeepSpeed4Science will create a new set of AI system technologies tailored for accelerating scientific discoveries by addressing their unique complexity beyond the common technical approaches used for accelerating generic large language models (LLMs). In this paper, we showcase the early progress we made with DeepSpeed4Science in addressing two of the critical system challenges in structural biology research.
Flash-LLM: Enabling Cost-Effective and Highly-Efficient Large Generative Model Inference with Unstructured Sparsity
Sep 19, 2023



With the fast growth of parameter size, it becomes increasingly challenging to deploy large generative models as they typically require large GPU memory consumption and massive computation. Unstructured model pruning has been a common approach to reduce both GPU memory footprint and the overall computation while retaining good model accuracy. However, the existing solutions do not provide a highly-efficient support for handling unstructured sparsity on modern GPUs, especially on the highly-structured Tensor Core hardware. Therefore, we propose Flash-LLM for enabling low-cost and highly-efficient large generative model inference with the sophisticated support of unstructured sparsity on high-performance but highly restrictive Tensor Cores. Based on our key observation that the main bottleneck of generative model inference is the several skinny matrix multiplications for which Tensor Cores would be significantly under-utilized due to low computational intensity, we propose a general Load-as-Sparse and Compute-as-Dense methodology for unstructured sparse matrix multiplication. The basic insight is to address the significant memory bandwidth bottleneck while tolerating redundant computations that are not critical for end-to-end performance on Tensor Cores. Based on this, we design an effective software framework for Tensor Core based unstructured SpMM, leveraging on-chip resources for efficient sparse data extraction and computation/memory-access overlapping. At SpMM kernel level, Flash-LLM significantly outperforms the state-of-the-art library, i.e., Sputnik and SparTA by an average of 2.9x and 1.5x, respectively. At end-to-end framework level on OPT-30B/66B/175B models, for tokens per GPU-second, Flash-LLM achieves up to 3.8x and 3.6x improvement over DeepSpeed and FasterTransformer, respectively, with significantly lower inference cost.
RenAIssance: A Survey into AI Text-to-Image Generation in the Era of Large Model
Sep 02, 2023



Text-to-image generation (TTI) refers to the usage of models that could process text input and generate high fidelity images based on text descriptions. Text-to-image generation using neural networks could be traced back to the emergence of Generative Adversial Network (GAN), followed by the autoregressive Transformer. Diffusion models are one prominent type of generative model used for the generation of images through the systematic introduction of noises with repeating steps. As an effect of the impressive results of diffusion models on image synthesis, it has been cemented as the major image decoder used by text-to-image models and brought text-to-image generation to the forefront of machine-learning (ML) research. In the era of large models, scaling up model size and the integration with large language models have further improved the performance of TTI models, resulting the generation result nearly indistinguishable from real-world images, revolutionizing the way we retrieval images. Our explorative study has incentivised us to think that there are further ways of scaling text-to-image models with the combination of innovative model architectures and prediction enhancement techniques. We have divided the work of this survey into five main sections wherein we detail the frameworks of major literature in order to delve into the different types of text-to-image generation methods. Following this we provide a detailed comparison and critique of these methods and offer possible pathways of improvement for future work. In the future work, we argue that TTI development could yield impressive productivity improvements for creation, particularly in the context of the AIGC era, and could be extended to more complex tasks such as video generation and 3D generation.
DeepSpeed-Chat: Easy, Fast and Affordable RLHF Training of ChatGPT-like Models at All Scales
Aug 02, 2023
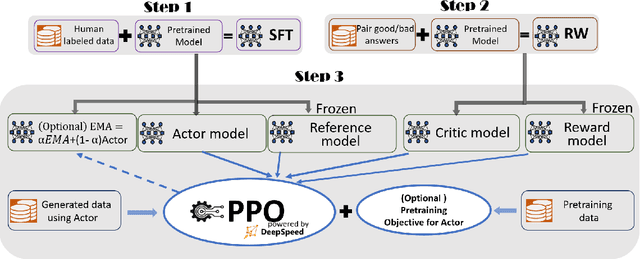

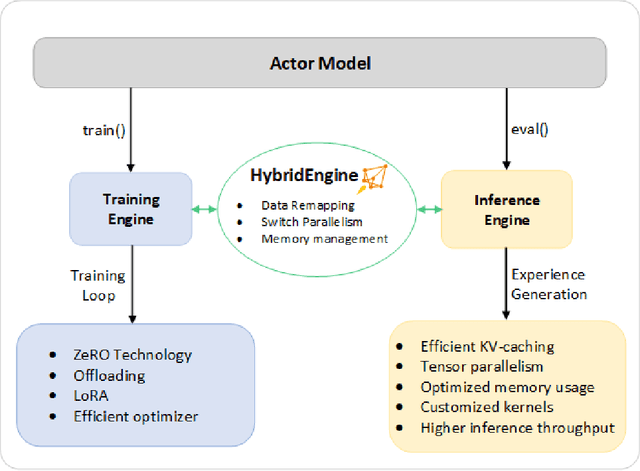
ChatGPT-like models have revolutionized various applications in artificial intelligence, from summarization and coding to translation, matching or even surpassing human performance. However, the current landscape lacks an accessible, efficient, and cost-effective end-to-end RLHF (Reinforcement Learning with Human Feedback) training pipeline for these powerful models, particularly when training at the scale of billions of parameters. This paper introduces DeepSpeed-Chat, a novel system that democratizes RLHF training, making it accessible to the AI community. DeepSpeed-Chat offers three key capabilities: an easy-to-use training and inference experience for ChatGPT-like models, a DeepSpeed-RLHF pipeline that replicates the training pipeline from InstructGPT, and a robust DeepSpeed-RLHF system that combines various optimizations for training and inference in a unified way. The system delivers unparalleled efficiency and scalability, enabling training of models with hundreds of billions of parameters in record time and at a fraction of the cost. With this development, DeepSpeed-Chat paves the way for broader access to advanced RLHF training, even for data scientists with limited resources, thereby fostering innovation and further development in the field of AI.