 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZeRO-Prefill: Zero Redundancy Overheads in MoE Prefill Serving
May 03, 2026Production LLM workloads increasingly serve discriminative tasks, such as classification, recommendation, and verification, whose answers are read from the logits of a single prefill pass with no autoregressive decoding. Serving these prefill-only workloads on mixture-of-experts (MoE) models is bottlenecked not by compute but by the distributed execution required to fit the model: existing parallel strategies (tensor, expert, and pipeline parallelism) trade memory pressure for redundant computation, communication, and synchronization, severely degrading MoE prefill serving efficiency. We observe that these overheads stem from coupling expert placement with synchronous activation routing -- a design inherited from the decoding era. The long, compute-bound forward passes of large-batch prefill open a per-layer window wide enough to stream expert weights in the background, replacing per-layer activation AllToAll with asynchronous weight AllGather fully overlapped with computation. We propose ZeRO-Prefill, a prefill-only serving system whose backend, AsyncEP (Asynchronous Expert Parallelism), gathers experts by weight rather than routing them by activation, and whose frontend co-enforces a physically-derived saturation threshold through prefix-aware routing and true-FLOPs load tracking. On Qwen3-235B-A22B across four hardware/precision configurations, ZeRO-Prefill delivers 1.35-1.37x throughput over the strongest distributed baseline on real-world workloads and up to 1.59x on long-context synthetic workloads, sustaining 29.8-36.2% per-GPU model FLOPs utilization.
Mojito: Motion Trajectory and Intensity Control for Video Generation
Dec 12, 2024



Recent advancements in diffusion models have shown great promise in producing high-quality video content. However, efficiently training diffusion models capable of integrating directional guidance and controllable motion intensity remains a challenging and under-explored area. This paper introduces Mojito, a diffusion model that incorporates both \textbf{Mo}tion tra\textbf{j}ectory and \textbf{i}ntensi\textbf{t}y contr\textbf{o}l for text to video generation. Specifically, Mojito features a Directional Motion Control module that leverages cross-attention to efficiently direct the generated object's motion without additional training, alongside a Motion Intensity Modulator that uses optical flow maps generated from videos to guide varying levels of motion intensity. Extensive experiments demonstrate Mojito's effectiveness in achieving precise trajectory and intensity control with high computational efficiency, generating motion patterns that closely match specified directions and intensities, providing realistic dynamics that align well with natural motion in real-world scenarios.
Training Ultra Long Context Language Model with Fully Pipelined Distributed Transformer
Aug 30, 2024
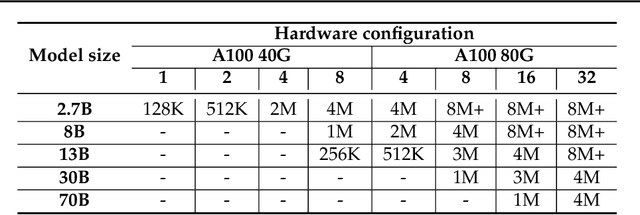
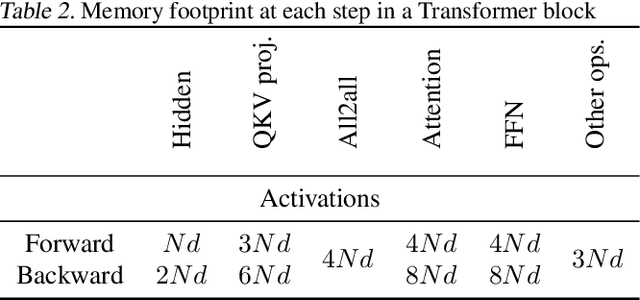

Large Language Models (LLMs) with long context capabilities are integral to complex tasks in natural language processing and computational biology, such as text generation and protein sequence analysis. However, training LLMs directly on extremely long contexts demands considerable GPU resources and increased memory, leading to higher costs and greater complexity. Alternative approaches that introduce long context capabilities via downstream finetuning or adaptations impose significant design limitations. In this paper, we propose Fully Pipelined Distributed Transformer (FPDT) for efficiently training long-context LLMs with extreme hardware efficiency. For GPT and Llama models, we achieve a 16x increase in sequence length that can be trained on the same hardware compared to current state-of-the-art solutions. With our dedicated sequence chunk pipeline design, we can now train 8B LLM with 2 million sequence length on only 4 GPUs, while also maintaining over 55% of MFU. Our proposed FPDT is agnostic to existing training techniques and is proven to work efficiently across different LLM models.
Universal Checkpointing: Efficient and Flexible Checkpointing for Large Scale Distributed Training
Jun 27, 2024



Existing checkpointing approaches seem ill-suited for distributed training even though hardware limitations make model parallelism, i.e., sharding model state across multiple accelerators, a requirement for model scaling. Consolidating distributed model state into a single checkpoint unacceptably slows down training, and is impractical at extreme scales. Distributed checkpoints, in contrast, are tightly coupled to the model parallelism and hardware configurations of the training run, and thus unusable on different configurations. To address this problem, we propose Universal Checkpointing, a technique that enables efficient checkpoint creation while providing the flexibility of resuming on arbitrary parallelism strategy and hardware configurations. Universal Checkpointing unlocks unprecedented capabilities for large-scale training such as improved resilience to hardware failures through continued training on remaining healthy hardware, and reduced training time through opportunistic exploitation of elastic capacity. The key insight of Universal Checkpointing is the selection of the optimal representation in each phase of the checkpointing life cycle: distributed representation for saving, and consolidated representation for loading. This is achieved using two key mechanisms. First, the universal checkpoint format, which consists of a consolidated representation of each model parameter and metadata for mapping parameter fragments into training ranks of arbitrary model-parallelism configuration. Second, the universal checkpoint language, a simple but powerful specification language for converting distributed checkpoints into the universal checkpoint format. Our evaluation demonstrates the effectiveness and generality of Universal Checkpointing on state-of-the-art model architectures and a wide range of parallelism techniques.
FastPersist: Accelerating Model Checkpointing in Deep Learning
Jun 19, 2024



Model checkpoints are critical Deep Learning (DL) artifacts that enable fault tolerance for training and downstream applications, such as inference. However, writing checkpoints to persistent storage, and other I/O aspects of DL training, are mostly ignored by compute-focused optimization efforts for faster training of rapidly growing models and datasets. Towards addressing this imbalance, we propose FastPersist to accelerate checkpoint creation in DL training. FastPersist combines three novel techniques: (i) NVMe optimizations for faster checkpoint writes to SSDs, (ii) efficient write parallelism using the available SSDs in training environments, and (iii) overlapping checkpointing with independent training computations. Our evaluation using real world dense and sparse DL models shows that FastPersist creates checkpoints in persistent storage up to 116x faster than baseline, and enables per-iteration checkpointing with negligible overhead.
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Apr 23, 2024



We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone. The innovation lies entirely in our dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data. The model is also further aligned for robustness, safety, and chat format. We also provide some initial parameter-scaling results with a 7B and 14B models trained for 4.8T tokens, called phi-3-small and phi-3-medium, both significantly more capable than phi-3-mini (e.g., respectively 75% and 78% on MMLU, and 8.7 and 8.9 on MT-bench).
Found in the Middle: How Language Models Use Long Contexts Better via Plug-and-Play Positional Encoding
Mar 05, 2024



This paper aims to overcome the "lost-in-the-middle" challenge of large language models (LLMs). While recent advancements have successfully enabled LLMs to perform stable language modeling with up to 4 million tokens, the persistent difficulty faced by most LLMs in identifying relevant information situated in the middle of the context has not been adequately tackled. To address this problem, this paper introduces Multi-scale Positional Encoding (Ms-PoE) which is a simple yet effective plug-and-play approach to enhance the capacity of LLMs to handle the relevant information located in the middle of the context, without fine-tuning or introducing any additional overhead. Ms-PoE leverages the position indice rescaling to relieve the long-term decay effect introduced by RoPE, while meticulously assigning distinct scaling ratios to different attention heads to preserve essential knowledge learned during the pre-training step, forming a multi-scale context fusion from short to long distance. Extensive experiments with a wide range of LLMs demonstrate the efficacy of our approach. Notably, Ms-PoE achieves an average accuracy gain of up to 3.8 on the Zero-SCROLLS benchmark over the original LLMs. Code are available at https://github.com/VITA-Group/Ms-PoE.
FP6-LLM: Efficiently Serving Large Language Models Through FP6-Centric Algorithm-System Co-Design
Jan 25, 2024



Six-bit quantization (FP6) can effectively reduce the size of large language models (LLMs) and preserve the model quality consistently across varied applications. However, existing systems do not provide Tensor Core support for FP6 quantization and struggle to achieve practical performance improvements during LLM inference. It is challenging to support FP6 quantization on GPUs due to (1) unfriendly memory access of model weights with irregular bit-width and (2) high runtime overhead of weight de-quantization. To address these problems, we propose TC-FPx, the first full-stack GPU kernel design scheme with unified Tensor Core support of float-point weights for various quantization bit-width. We integrate TC-FPx kernel into an existing inference system, providing new end-to-end support (called FP6-LLM) for quantized LLM inference, where better trade-offs between inference cost and model quality are achieved. Experiments show that FP6-LLM enables the inference of LLaMA-70b using only a single GPU, achieving 1.69x-2.65x higher normalized inference throughput than the FP16 baseline. The source code will be publicly available soon.
ZeroQuant(4+2): Redefining LLMs Quantization with a New FP6-Centric Strategy for Diverse Generative Tasks
Dec 18, 2023



This study examines 4-bit quantization methods like GPTQ in large language models (LLMs), highlighting GPTQ's overfitting and limited enhancement in Zero-Shot tasks. While prior works merely focusing on zero-shot measurement, we extend task scope to more generative categories such as code generation and abstractive summarization, in which we found that INT4 quantization can significantly underperform. However, simply shifting to higher precision formats like FP6 has been particularly challenging, thus overlooked, due to poor performance caused by the lack of sophisticated integration and system acceleration strategies on current AI hardware. Our results show that FP6, even with a coarse-grain quantization scheme, performs robustly across various algorithms and tasks, demonstrating its superiority in accuracy and versatility. Notably, with the FP6 quantization, \codestar-15B model performs comparably to its FP16 counterpart in code generation, and for smaller models like the 406M it closely matches their baselines in summarization. Neither can be achieved by INT4. To better accommodate various AI hardware and achieve the best system performance, we propose a novel 4+2 design for FP6 to achieve similar latency to the state-of-the-art INT4 fine-grain quantization. With our design, FP6 can become a promising solution to the current 4-bit quantization methods used in LLMs.
DeepSpeed-VisualChat: Multi-Round Multi-Image Interleave Chat via Multi-Modal Causal Attention
Sep 29, 2023



Most of the existing multi-modal models, hindered by their incapacity to adeptly manage interleaved image-and-text inputs in multi-image, multi-round dialogues, face substantial constraints in resource allocation for training and data accessibility, impacting their adaptability and scalability across varied interaction realms. To address this, we present the DeepSpeed-VisualChat framework, designed to optimize Large Language Models (LLMs) by incorporating multi-modal capabilities, with a focus on enhancing the proficiency of Large Vision and Language Models in handling interleaved inputs. Our framework is notable for (1) its open-source support for multi-round and multi-image dialogues, (2) introducing an innovative multi-modal causal attention mechanism, and (3) utilizing data blending techniques on existing datasets to assure seamless interactions in multi-round, multi-image conversations. Compared to existing frameworks, DeepSpeed-VisualChat shows superior scalability up to 70B parameter language model size, representing a significant advancement in multi-modal language models and setting a solid foundation for future explorations.