 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAC-Attention: a Match-Amend-Complete Scheme for Fast and Accurate Attention Computation
Mar 31, 2026Long-context decoding in LLMs is IO-bound: each token re-reads an ever-growing KV cache. Prior accelerations cut bytes via compression, which lowers fidelity, or selection/eviction, which restricts what remains accessible, and both can degrade delayed recall and long-form generation. We introduce MAC-Attention, a fidelity- and access-preserving alternative that accelerates decoding by reusing prior attention computations for semantically similar recent queries. It starts with a match stage that performs pre-RoPE L2 matching over a short local window; an amend stage rectifies the reused attention by recomputing a small band near the match boundary; and a complete stage fuses the rectified results with fresh attention computed on the KV tail through a numerically stable merge. On a match hit, the compute and bandwidth complexity is constant regardless of context length. The method is model-agnostic and composes with IO-aware kernels, paged-KV managers, and MQA/GQA. Across LongBench v2 (120K), RULER (120K), and LongGenBench (16K continuous generation), compared to the latest FlashInfer library, MAC-Attention reduces KV accesses by up to 99%, cuts token generation latency by over 60% at 128K, and achieves over 14.3x attention-phase speedups, up to 2.6x end-to-end, while maintaining full-attention quality. By reusing computation, MAC-Attention delivers long-context inference that is both fast and faithful. Code is available here: https://github.com/YJHMITWEB/MAC-Attention.git
Training Ultra Long Context Language Model with Fully Pipelined Distributed Transformer
Aug 30, 2024
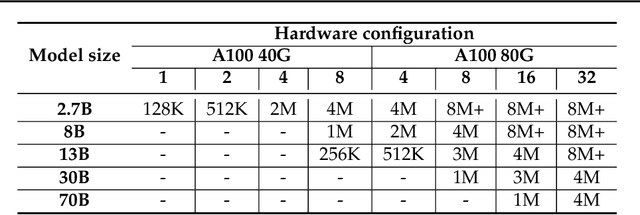
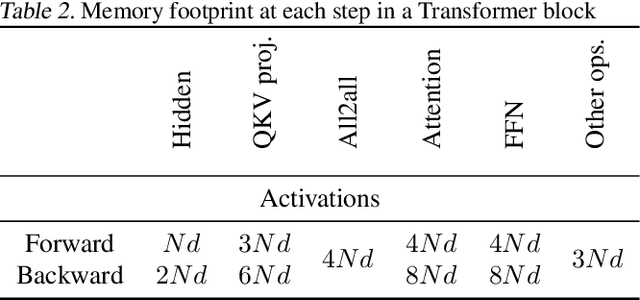

Large Language Models (LLMs) with long context capabilities are integral to complex tasks in natural language processing and computational biology, such as text generation and protein sequence analysis. However, training LLMs directly on extremely long contexts demands considerable GPU resources and increased memory, leading to higher costs and greater complexity. Alternative approaches that introduce long context capabilities via downstream finetuning or adaptations impose significant design limitations. In this paper, we propose Fully Pipelined Distributed Transformer (FPDT) for efficiently training long-context LLMs with extreme hardware efficiency. For GPT and Llama models, we achieve a 16x increase in sequence length that can be trained on the same hardware compared to current state-of-the-art solutions. With our dedicated sequence chunk pipeline design, we can now train 8B LLM with 2 million sequence length on only 4 GPUs, while also maintaining over 55% of MFU. Our proposed FPDT is agnostic to existing training techniques and is proven to work efficiently across different LLM models.
Exploiting Inter-Layer Expert Affinity for Accelerating Mixture-of-Experts Model Inference
Jan 17, 2024



In large language models like the Generative Pre-trained Transformer, the Mixture of Experts paradigm has emerged as a powerful technique for enhancing model expressiveness and accuracy. However, deploying GPT MoE models for parallel inference on distributed systems presents significant challenges, primarily due to the extensive Alltoall communication required for expert routing and aggregation. This communication bottleneck exacerbates the already complex computational landscape, hindering the efficient utilization of high-performance computing resources. In this paper, we propose a lightweight optimization technique called ExFlow, to largely accelerate the inference of these MoE models. We take a new perspective on alleviating the communication overhead by exploiting the inter-layer expert affinity. Unlike previous methods, our solution can be directly applied to pre-trained MoE models without any fine-tuning or accuracy degradation. By proposing a context-coherent expert parallelism on distributed systems, our design only uses one Alltoall communication to deliver the same functionality while previous methods all require two Alltoalls. By carefully examining the conditional probability in tokens' routing across multiple layers, we proved that pre-trained GPT MoE models implicitly exhibit a strong inter-layer expert affinity. We then design an efficient integer programming model to capture such features and show that by properly placing the experts on corresponding GPUs, we can reduce up to 67% cross-GPU routing latency. Our solution beats the cutting-edge MoE implementations with experts from 8 to 64, with up to 2.2x improvement in inference throughput. We further provide a detailed study of how the model implicitly acquires this expert affinity at the very early training stage and how this affinity evolves and stabilizes during training.
Flover: A Temporal Fusion Framework for Efficient Autoregressive Model Parallel Inference
May 24, 2023



In the rapidly evolving field of deep learning, the performance of model inference has become a pivotal aspect as models become more complex and are deployed in diverse applications. Among these, autoregressive models stand out due to their state-of-the-art performance in numerous generative tasks. These models, by design, harness a temporal dependency structure, where the current token's probability distribution is conditioned on preceding tokens. This inherently sequential characteristic, however, adheres to the Markov Chain assumption and lacks temporal parallelism, which poses unique challenges. Particularly in industrial contexts where inference requests, following a Poisson time distribution, necessitate diverse response lengths, this absence of parallelism is more profound. Existing solutions, such as dynamic batching and concurrent model instances, nevertheless, come with severe overheads and a lack of flexibility, these coarse-grained methods fall short of achieving optimal latency and throughput. To address these shortcomings, we propose Flavor -- a temporal fusion framework for efficient inference in autoregressive models, eliminating the need for heuristic settings and applies to a wide range of inference scenarios. By providing more fine-grained parallelism on the temporality of requests and employing an efficient memory shuffle algorithm, Flover achieves up to 11x faster inference on GPT models compared to the cutting-edge solutions provided by NVIDIA Triton FasterTransformer. Crucially, by leveraging the advanced tensor parallel technique, Flover proves efficacious across diverse computational landscapes, from single-GPU setups to multi-node scenarios, thereby offering robust performance optimization that transcends hardware boundaries.
SOFT: Softmax-free Transformer with Linear Complexity
Oct 29, 2021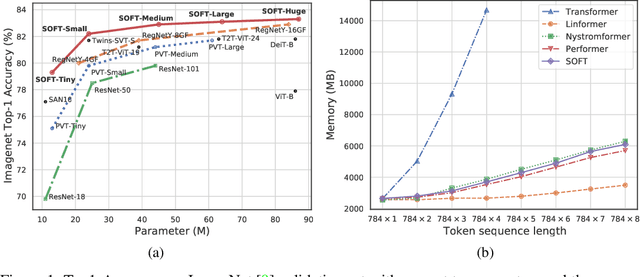
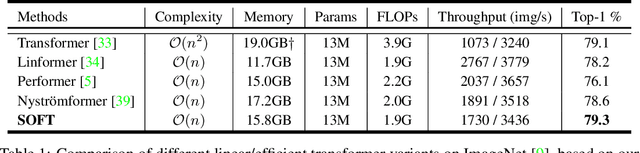
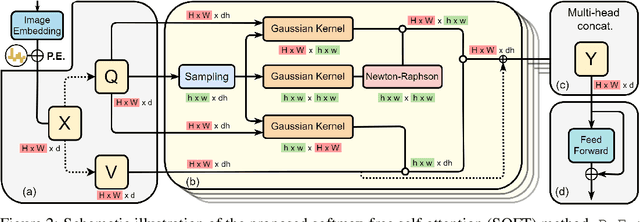
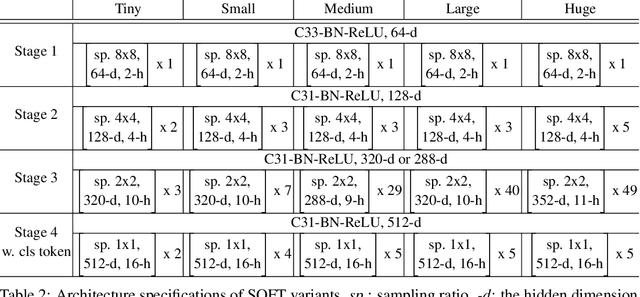
Vision transformers (ViTs) have pushed the state-of-the-art for various visual recognition tasks by patch-wise image tokenization followed by self-attention. However, the employment of self-attention modules results in a quadratic complexity in both computation and memory usage. Various attempts on approximating the self-attention computation with linear complexity have been made in Natural Language Processing. However, an in-depth analysis in this work shows that they are either theoretically flawed or empirically ineffective for visual recognition. We further identify that their limitations are rooted in keeping the softmax self-attention during approximations. Specifically, conventional self-attention is computed by normalizing the scaled dot-product between token feature vectors. Keeping this softmax operation challenges any subsequent linearization efforts. Based on this insight, for the first time, a softmax-free transformer or SOFT is proposed. To remove softmax in self-attention, Gaussian kernel function is used to replace the dot-product similarity without further normalization. This enables a full self-attention matrix to be approximated via a low-rank matrix decomposition. The robustness of the approximation is achieved by calculating its Moore-Penrose inverse using a Newton-Raphson method. Extensive experiments on ImageNet show that our SOFT significantly improves the computational efficiency of existing ViT variants. Crucially, with a linear complexity, much longer token sequences are permitted in SOFT, resulting in superior trade-off between accuracy and complexity.
Single Pixel Reconstruction for One-stage Instance Segmentation
May 17, 2019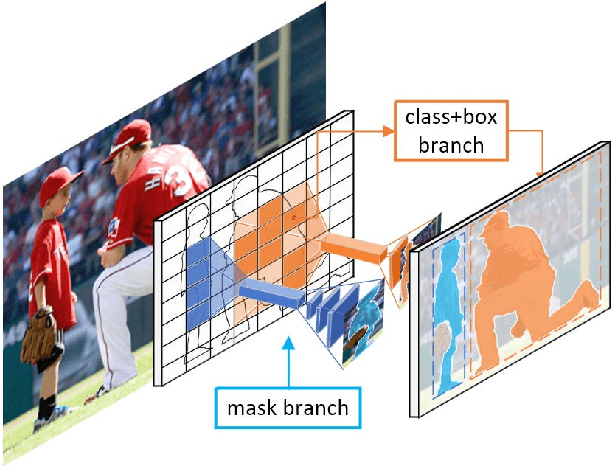
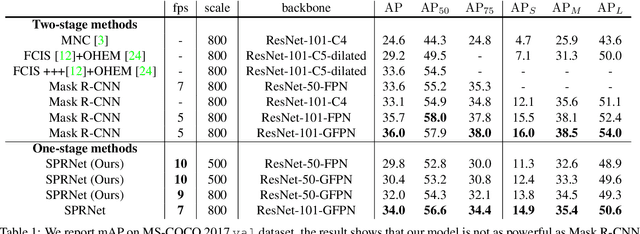
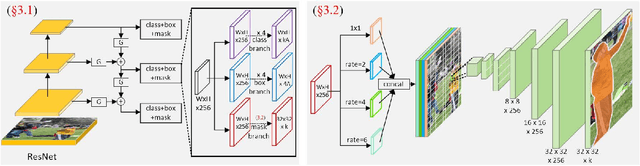

Object instance segmentation is one of the most fundamental but challenging tasks in computer vision, and it requires the pixel-level image understanding. Most existing approaches address this problem by adding a mask prediction branch to a two-stage object detector with the Region Proposal Network (RPN). Although producing good segmentation results, the efficiency of these two-stage approaches is far from satisfactory, restricting their applicability in practice. In this paper, we propose a one-stage framework, SPRNet, which performs efficient instance segmentation by introducing a single pixel reconstruction (SPR) branch to off-the-shelf one-stage detectors. The added SPR branch reconstructs the pixel-level mask from every single pixel in the convolution feature map directly. Using the same ResNet-50 backbone, SPRNet achieves comparable mask AP to Mask R-CNN at a higher inference speed, and gains all-round improvements on box AP at every scale comparing with RetinaNet.