 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Recurrent Transformer: Architecture Exploration, Training Strategies, and Scaling Behavior
May 26, 2026We study Latent Recurrent Transformer (LRT), a lightweight augmentation of autoregressive transformers that reuses a high-level source-layer hidden state from the previous token as recurrent memory for the next token. Because this source state is already computed during ordinary decoding, LRT adds a cross-layer recurrent latent pathway across positions without inserting pause tokens or extra depth loops, and the standard attention mechanism and KV-cache interface are preserved. To pretrain this recurrence at scale without sequentially unrolling the transformer, we introduce interleaved parallel training: a single full-sequence initialization forward pass builds a shared buffer; then disjoint position subsets are refined in parallel and written back, so that all tokens receive recurrent-memory-aware supervision at roughly 2 times baseline compute. Across nanochat style backbones and a wide range of tokens-per-parameter budgets, LRT improves both language-modeling loss and in-context learning under matched effective compute while adding as little as 0.3% parameters.
RLVE: Scaling Up Reinforcement Learning for Language Models with Adaptive Verifiable Environments
Nov 10, 2025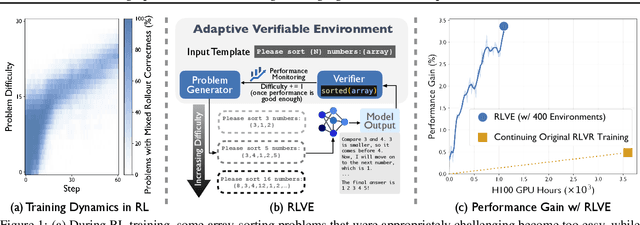

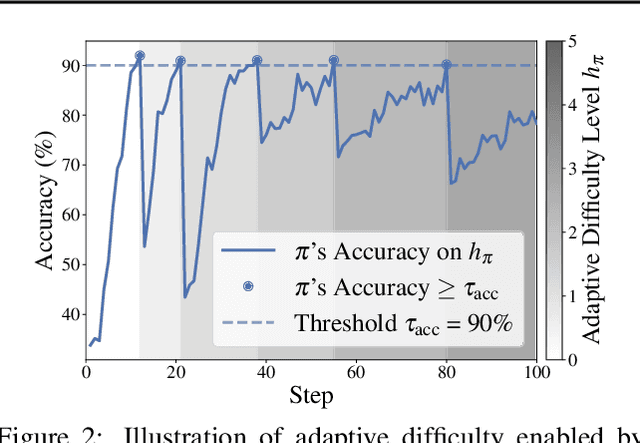
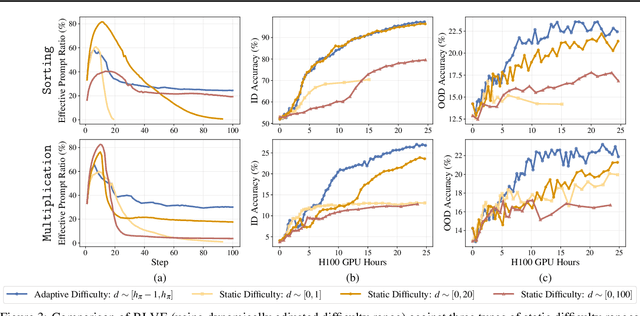
We introduce Reinforcement Learning (RL) with Adaptive Verifiable Environments (RLVE), an approach using verifiable environments that procedurally generate problems and provide algorithmically verifiable rewards, to scale up RL for language models (LMs). RLVE enables each verifiable environment to dynamically adapt its problem difficulty distribution to the policy model's capabilities as training progresses. In contrast, static data distributions often lead to vanishing learning signals when problems are either too easy or too hard for the policy. To implement RLVE, we create RLVE-Gym, a large-scale suite of 400 verifiable environments carefully developed through manual environment engineering. Using RLVE-Gym, we show that environment scaling, i.e., expanding the collection of training environments, consistently improves generalizable reasoning capabilities. RLVE with joint training across all 400 environments in RLVE-Gym yields a 3.37% absolute average improvement across six reasoning benchmarks, starting from one of the strongest 1.5B reasoning LMs. By comparison, continuing this LM's original RL training yields only a 0.49% average absolute gain despite using over 3x more compute. We release our code publicly.
Spurious Rewards: Rethinking Training Signals in RLVR
Jun 12, 2025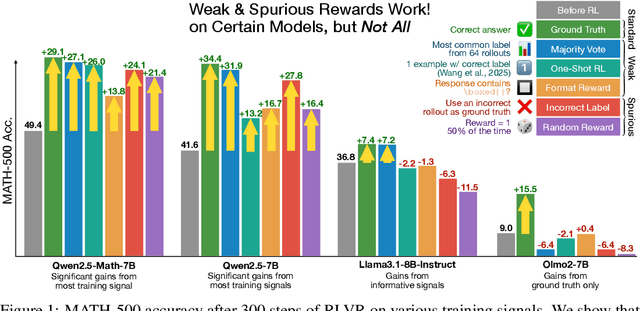
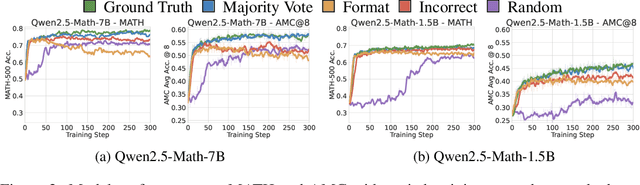
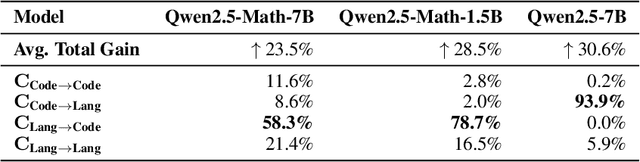
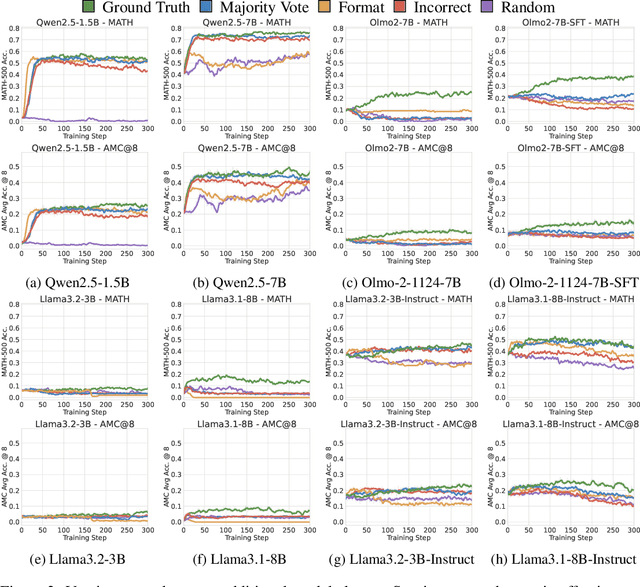
We show that reinforcement learning with verifiable rewards (RLVR) can elicit strong mathematical reasoning in certain models even with spurious rewards that have little, no, or even negative correlation with the correct answer. For example, RLVR improves MATH-500 performance for Qwen2.5-Math-7B in absolute points by 21.4% (random reward), 13.8% (format reward), 24.1% (incorrect label), 26.0% (1-shot RL), and 27.1% (majority voting) -- nearly matching the 29.1% gained with ground truth rewards. However, the spurious rewards that work for Qwen often fail to yield gains with other model families like Llama3 or OLMo2. In particular, we find code reasoning -- thinking in code without actual code execution -- to be a distinctive Qwen2.5-Math behavior that becomes significantly more frequent after RLVR, from 65% to over 90%, even with spurious rewards. Overall, we hypothesize that, given the lack of useful reward signal, RLVR must somehow be surfacing useful reasoning representations learned during pretraining, although the exact mechanism remains a topic for future work. We suggest that future RLVR research should possibly be validated on diverse models rather than a single de facto choice, as we show that it is easy to get significant performance gains on Qwen models even with completely spurious reward signals.
FloE: On-the-Fly MoE Inference on Memory-constrained GPU
May 12, 2025With the widespread adoption of Mixture-of-Experts (MoE) models, there is a growing demand for efficient inference on memory-constrained devices. While offloading expert parameters to CPU memory and loading activated experts on demand has emerged as a potential solution, the large size of activated experts overburdens the limited PCIe bandwidth, hindering the effectiveness in latency-sensitive scenarios. To mitigate this, we propose FloE, an on-the-fly MoE inference system on memory-constrained GPUs. FloE is built on the insight that there exists substantial untapped redundancy within sparsely activated experts. It employs various compression techniques on the expert's internal parameter matrices to reduce the data movement load, combined with low-cost sparse prediction, achieving perceptible inference acceleration in wall-clock time on resource-constrained devices. Empirically, FloE achieves a 9.3x compression of parameters per expert in Mixtral-8x7B; enables deployment on a GPU with only 11GB VRAM, reducing the memory footprint by up to 8.5x; and delivers a 48.7x inference speedup compared to DeepSpeed-MII on a single GeForce RTX 3090 - all with only a 4.4$\%$ - 7.6$\%$ average performance degradation.
FloE: On-the-Fly MoE Inference
May 09, 2025With the widespread adoption of Mixture-of-Experts (MoE) models, there is a growing demand for efficient inference on memory-constrained devices. While offloading expert parameters to CPU memory and loading activated experts on demand has emerged as a potential solution, the large size of activated experts overburdens the limited PCIe bandwidth, hindering the effectiveness in latency-sensitive scenarios. To mitigate this, we propose FloE, an on-the-fly MoE inference system on memory-constrained GPUs. FloE is built on the insight that there exists substantial untapped redundancy within sparsely activated experts. It employs various compression techniques on the expert's internal parameter matrices to reduce the data movement load, combined with low-cost sparse prediction, achieving perceptible inference acceleration in wall-clock time on resource-constrained devices. Empirically, FloE achieves a 9.3x compression of parameters per expert in Mixtral-8x7B; enables deployment on a GPU with only 11GB VRAM, reducing the memory footprint by up to 8.5x; and delivers a 48.7x inference speedup compared to DeepSpeed-MII on a single GeForce RTX 3090.
Reinforcement Learning for Reasoning in Large Language Models with One Training Example
Apr 29, 2025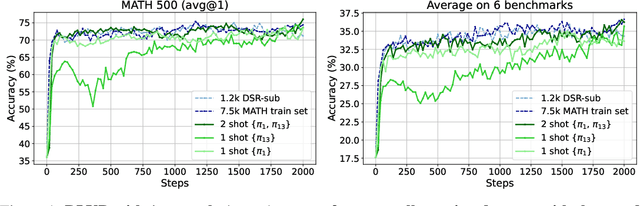
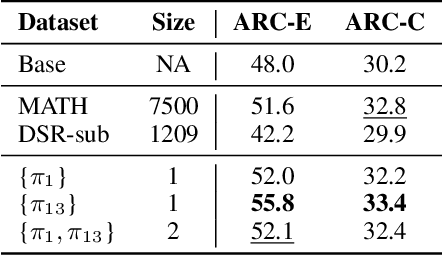
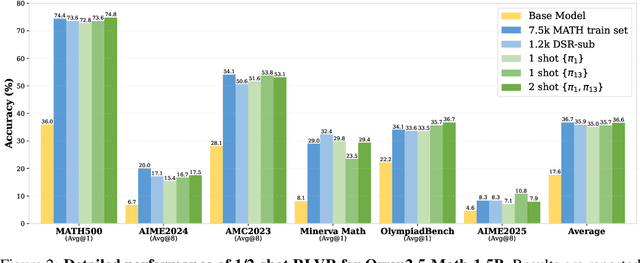

We show that reinforcement learning with verifiable reward using one training example (1-shot RLVR) is effective in incentivizing the math reasoning capabilities of large language models (LLMs). Applying RLVR to the base model Qwen2.5-Math-1.5B, we identify a single example that elevates model performance on MATH500 from 36.0% to 73.6%, and improves the average performance across six common mathematical reasoning benchmarks from 17.6% to 35.7%. This result matches the performance obtained using the 1.2k DeepScaleR subset (MATH500: 73.6%, average: 35.9%), which includes the aforementioned example. Similar substantial improvements are observed across various models (Qwen2.5-Math-7B, Llama3.2-3B-Instruct, DeepSeek-R1-Distill-Qwen-1.5B), RL algorithms (GRPO and PPO), and different math examples (many of which yield approximately 30% or greater improvement on MATH500 when employed as a single training example). In addition, we identify some interesting phenomena during 1-shot RLVR, including cross-domain generalization, increased frequency of self-reflection, and sustained test performance improvement even after the training accuracy has saturated, a phenomenon we term post-saturation generalization. Moreover, we verify that the effectiveness of 1-shot RLVR primarily arises from the policy gradient loss, distinguishing it from the "grokking" phenomenon. We also show the critical role of promoting exploration (e.g., by adding entropy loss with an appropriate coefficient) in 1-shot RLVR training. As a bonus, we observe that applying entropy loss alone, without any outcome reward, significantly enhances Qwen2.5-Math-1.5B's performance on MATH500 by 27.4%. These findings can inspire future work on RLVR data efficiency and encourage a re-examination of both recent progress and the underlying mechanisms in RLVR. Our code, model, and data are open source at https://github.com/ypwang61/One-Shot-RLVR
DrivAer Transformer: A high-precision and fast prediction method for vehicle aerodynamic drag coefficient based on the DrivAerNet++ dataset
Apr 15, 2025At the current stage, deep learning-based methods have demonstrated excellent capabilities in evaluating aerodynamic performance, significantly reducing the time and cost required for traditional computational fluid dynamics (CFD) simulations. However, when faced with the task of processing extremely complex three-dimensional (3D) vehicle models, the lack of large-scale datasets and training resources, coupled with the inherent diversity and complexity of the geometry of different vehicle models, means that the prediction accuracy and versatility of these networks are still not up to the level required for current production. In view of the remarkable success of Transformer models in the field of natural language processing and their strong potential in the field of image processing, this study innovatively proposes a point cloud learning framework called DrivAer Transformer (DAT). The DAT structure uses the DrivAerNet++ dataset, which contains high-fidelity CFD data of industrial-standard 3D vehicle shapes. enabling accurate estimation of air drag directly from 3D meshes, thus avoiding the limitations of traditional methods such as 2D image rendering or signed distance fields (SDF). DAT enables fast and accurate drag prediction, driving the evolution of the aerodynamic evaluation process and laying the critical foundation for introducing a data-driven approach to automotive design. The framework is expected to accelerate the vehicle design process and improve development efficiency.
SHARP: Accelerating Language Model Inference by SHaring Adjacent layers with Recovery Parameters
Feb 11, 2025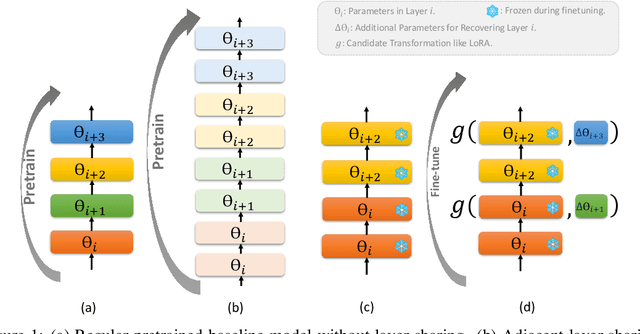

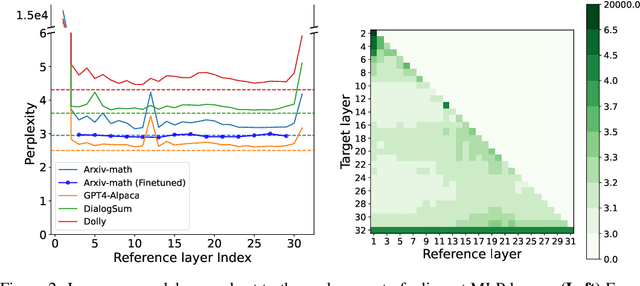
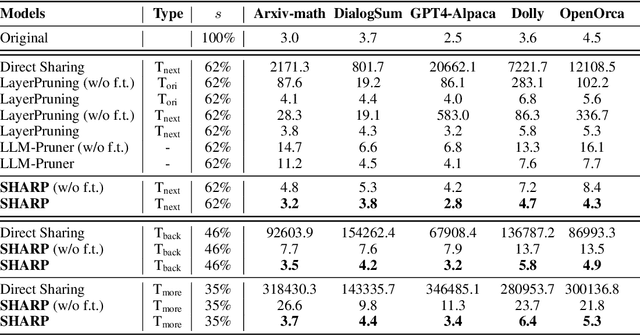
While Large language models (LLMs) have advanced natural language processing tasks, their growing computational and memory demands make deployment on resource-constrained devices like mobile phones increasingly challenging. In this paper, we propose SHARP (SHaring Adjacent Layers with Recovery Parameters), a novel approach to accelerate LLM inference by sharing parameters across adjacent layers, thus reducing memory load overhead, while introducing low-rank recovery parameters to maintain performance. Inspired by observations that consecutive layers have similar outputs, SHARP employs a two-stage recovery process: Single Layer Warmup (SLW), and Supervised Fine-Tuning (SFT). The SLW stage aligns the outputs of the shared layers using L_2 loss, providing a good initialization for the following SFT stage to further restore the model performance. Extensive experiments demonstrate that SHARP can recover the model's perplexity on various in-distribution tasks using no more than 50k fine-tuning data while reducing the number of stored MLP parameters by 38% to 65%. We also conduct several ablation studies of SHARP and show that replacing layers towards the later parts of the model yields better performance retention, and that different recovery parameterizations perform similarly when parameter counts are matched. Furthermore, SHARP saves 42.8% in model storage and reduces the total inference time by 42.2% compared to the original Llama2-7b model on mobile devices. Our results highlight SHARP as an efficient solution for reducing inference costs in deploying LLMs without the need for pretraining-scale resources.
Is Your World Simulator a Good Story Presenter? A Consecutive Events-Based Benchmark for Future Long Video Generation
Dec 17, 2024
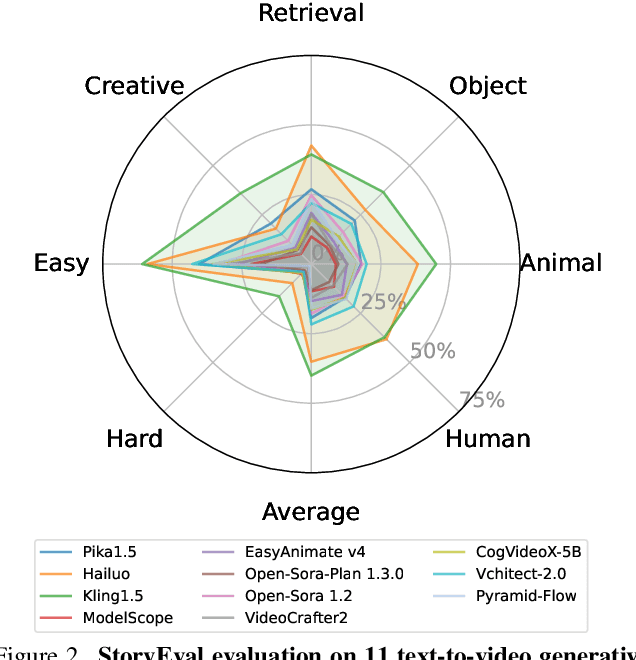


The current state-of-the-art video generative models can produce commercial-grade videos with highly realistic details. However, they still struggle to coherently present multiple sequential events in the stories specified by the prompts, which is foreseeable an essential capability for future long video generation scenarios. For example, top T2V generative models still fail to generate a video of the short simple story 'how to put an elephant into a refrigerator.' While existing detail-oriented benchmarks primarily focus on fine-grained metrics like aesthetic quality and spatial-temporal consistency, they fall short of evaluating models' abilities to handle event-level story presentation. To address this gap, we introduce StoryEval, a story-oriented benchmark specifically designed to assess text-to-video (T2V) models' story-completion capabilities. StoryEval features 423 prompts spanning 7 classes, each representing short stories composed of 2-4 consecutive events. We employ advanced vision-language models, such as GPT-4V and LLaVA-OV-Chat-72B, to verify the completion of each event in the generated videos, applying a unanimous voting method to enhance reliability. Our methods ensure high alignment with human evaluations, and the evaluation of 11 models reveals its challenge, with none exceeding an average story-completion rate of 50%. StoryEval provides a new benchmark for advancing T2V models and highlights the challenges and opportunities in developing next-generation solutions for coherent story-driven video generation.
Mojito: Motion Trajectory and Intensity Control for Video Generation
Dec 12, 2024



Recent advancements in diffusion models have shown great promise in producing high-quality video content. However, efficiently training diffusion models capable of integrating directional guidance and controllable motion intensity remains a challenging and under-explored area. This paper introduces Mojito, a diffusion model that incorporates both \textbf{Mo}tion tra\textbf{j}ectory and \textbf{i}ntensi\textbf{t}y contr\textbf{o}l for text to video generation. Specifically, Mojito features a Directional Motion Control module that leverages cross-attention to efficiently direct the generated object's motion without additional training, alongside a Motion Intensity Modulator that uses optical flow maps generated from videos to guide varying levels of motion intensity. Extensive experiments demonstrate Mojito's effectiveness in achieving precise trajectory and intensity control with high computational efficiency, generating motion patterns that closely match specified directions and intensities, providing realistic dynamics that align well with natural motion in real-world scenarios.