 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDA-SSL: self-supervised domain adaptor to leverage foundational models in turbt histopathology slides
Dec 15, 2025Recent deep learning frameworks in histopathology, particularly multiple instance learning (MIL) combined with pathology foundational models (PFMs), have shown strong performance. However, PFMs exhibit limitations on certain cancer or specimen types due to domain shifts - these cancer types were rarely used for pretraining or specimens contain tissue-based artifacts rarely seen within the pretraining population. Such is the case for transurethral resection of bladder tumor (TURBT), which are essential for diagnosing muscle-invasive bladder cancer (MIBC), but contain fragmented tissue chips and electrocautery artifacts and were not widely used in publicly available PFMs. To address this, we propose a simple yet effective domain-adaptive self-supervised adaptor (DA-SSL) that realigns pretrained PFM features to the TURBT domain without fine-tuning the foundational model itself. We pilot this framework for predicting treatment response in TURBT, where histomorphological features are currently underutilized and identifying patients who will benefit from neoadjuvant chemotherapy (NAC) is challenging. In our multi-center study, DA-SSL achieved an AUC of 0.77+/-0.04 in five-fold cross-validation and an external test accuracy of 0.84, sensitivity of 0.71, and specificity of 0.91 using majority voting. Our results demonstrate that lightweight domain adaptation with self-supervision can effectively enhance PFM-based MIL pipelines for clinically challenging histopathology tasks. Code is Available at https://github.com/zhanghaoyue/DA_SSL_TURBT.
Reinforcement Learning for Reasoning in Large Language Models with One Training Example
Apr 29, 2025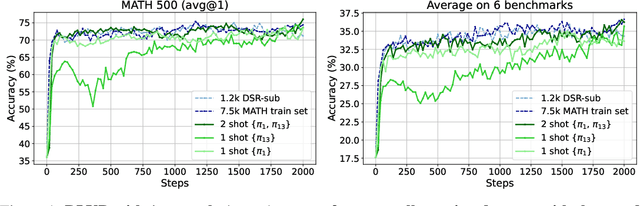
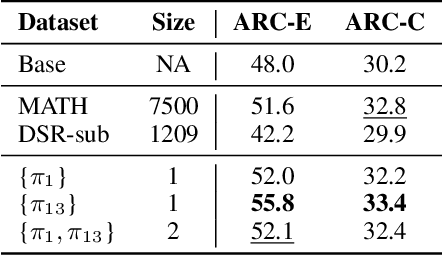
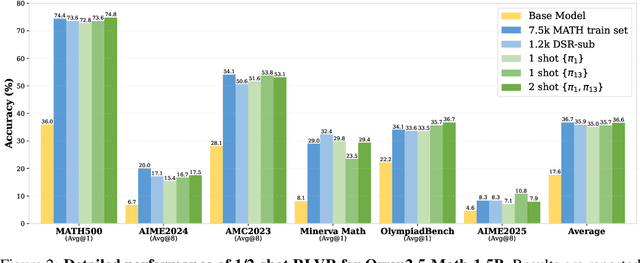

We show that reinforcement learning with verifiable reward using one training example (1-shot RLVR) is effective in incentivizing the math reasoning capabilities of large language models (LLMs). Applying RLVR to the base model Qwen2.5-Math-1.5B, we identify a single example that elevates model performance on MATH500 from 36.0% to 73.6%, and improves the average performance across six common mathematical reasoning benchmarks from 17.6% to 35.7%. This result matches the performance obtained using the 1.2k DeepScaleR subset (MATH500: 73.6%, average: 35.9%), which includes the aforementioned example. Similar substantial improvements are observed across various models (Qwen2.5-Math-7B, Llama3.2-3B-Instruct, DeepSeek-R1-Distill-Qwen-1.5B), RL algorithms (GRPO and PPO), and different math examples (many of which yield approximately 30% or greater improvement on MATH500 when employed as a single training example). In addition, we identify some interesting phenomena during 1-shot RLVR, including cross-domain generalization, increased frequency of self-reflection, and sustained test performance improvement even after the training accuracy has saturated, a phenomenon we term post-saturation generalization. Moreover, we verify that the effectiveness of 1-shot RLVR primarily arises from the policy gradient loss, distinguishing it from the "grokking" phenomenon. We also show the critical role of promoting exploration (e.g., by adding entropy loss with an appropriate coefficient) in 1-shot RLVR training. As a bonus, we observe that applying entropy loss alone, without any outcome reward, significantly enhances Qwen2.5-Math-1.5B's performance on MATH500 by 27.4%. These findings can inspire future work on RLVR data efficiency and encourage a re-examination of both recent progress and the underlying mechanisms in RLVR. Our code, model, and data are open source at https://github.com/ypwang61/One-Shot-RLVR
Multi-Head Adapter Routing for Data-Efficient Fine-Tuning
Nov 07, 2022Parameter-efficient fine-tuning (PEFT) methods can adapt large language models to downstream tasks by training a small amount of newly added parameters. In multi-task settings, PEFT adapters typically train on each task independently, inhibiting transfer across tasks, or on the concatenation of all tasks, which can lead to negative interference. To address this, Polytropon (Ponti et al.) jointly learns an inventory of PEFT adapters and a routing function to share variable-size sets of adapters across tasks. Subsequently, adapters can be re-combined and fine-tuned on novel tasks even with limited data. In this paper, we investigate to what extent the ability to control which adapters are active for each task leads to sample-efficient generalization. Thus, we propose less expressive variants where we perform weighted averaging of the adapters before few-shot adaptation (Poly-mu) instead of learning a routing function. Moreover, we introduce more expressive variants where finer-grained task-adapter allocation is learned through a multi-head routing function (Poly-S). We test these variants on three separate benchmarks for multi-task learning. We find that Poly-S achieves gains on all three (up to 5.3 points on average) over strong baselines, while incurring a negligible additional cost in parameter count. In particular, we find that instruction tuning, where models are fully fine-tuned on natural language instructions for each task, is inferior to modular methods such as Polytropon and our proposed variants.
BERTifying the Hidden Markov Model for Multi-Source Weakly Supervised Named Entity Recognition
May 30, 2021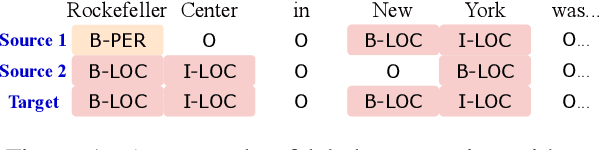
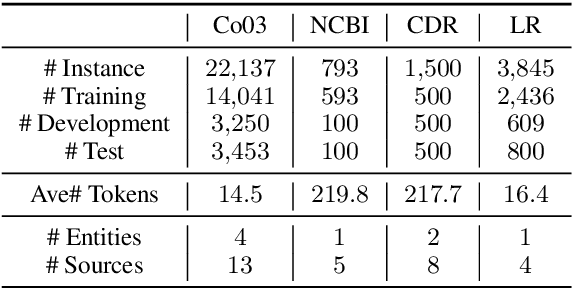
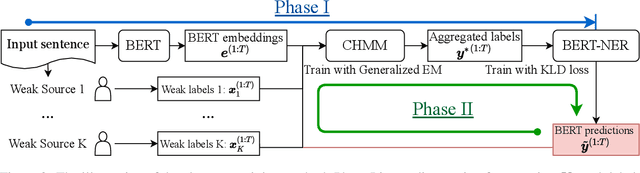
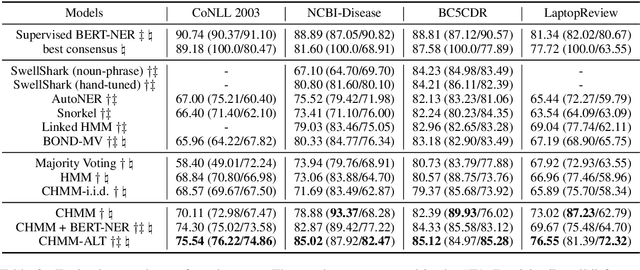
We study the problem of learning a named entity recognition (NER) tagger using noisy labels from multiple weak supervision sources. Though cheap to obtain, the labels from weak supervision sources are often incomplete, inaccurate, and contradictory, making it difficult to learn an accurate NER model. To address this challenge, we propose a conditional hidden Markov model (CHMM), which can effectively infer true labels from multi-source noisy labels in an unsupervised way. CHMM enhances the classic hidden Markov model with the contextual representation power of pre-trained language models. Specifically, CHMM learns token-wise transition and emission probabilities from the BERT embeddings of the input tokens to infer the latent true labels from noisy observations. We further refine CHMM with an alternate-training approach (CHMM-ALT). It fine-tunes a BERT-NER model with the labels inferred by CHMM, and this BERT-NER's output is regarded as an additional weak source to train the CHMM in return. Experiments on four NER benchmarks from various domains show that our method outperforms state-of-the-art weakly supervised NER models by wide margins.