 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow LLMs Distort Our Written Language
Mar 18, 2026Large language models (LLMs) are used by over a billion people globally, most often to assist with writing. In this work, we demonstrate that LLMs not only alter the voice and tone of human writing, but also consistently alter the intended meaning. First, we conduct a human user study to understand how people actually interact with LLMs when using them for writing. Our findings reveal that extensive LLM use led to a nearly 70% increase in essays that remained neutral in answering the topic question. Significantly more heavy LLM users reported that the writing was less creative and not in their voice. Next, using a dataset of human-written essays that was collected in 2021 before the widespread release of LLMs, we study how asking an LLM to revise the essay based on the human-written feedback in the dataset induces large changes in the resulting content and meaning. We find that even when LLMs are prompted with expert feedback and asked to only make grammar edits, they still change the text in a way that significantly alters its semantic meaning. We then examine LLM-generated text in the wild, specifically focusing on the 21% of AI-generated scientific peer reviews at a recent top AI conference. We find that LLM-generated reviews place significantly less weight on clarity and significance of the research, and assign scores that, on average, are a full point higher.These findings highlight a misalignment between the perceived benefit of AI use and an implicit, consistent effect on the semantics of human writing, motivating future work on how widespread AI writing will affect our cultural and scientific institutions.
Learning Pluralistic User Preferences through Reinforcement Learning Fine-tuned Summaries
Jul 17, 2025
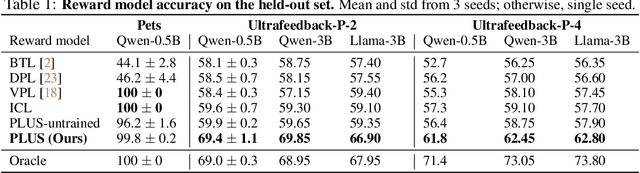
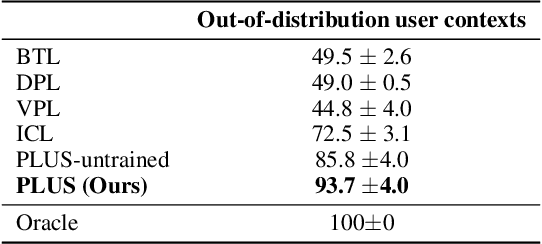
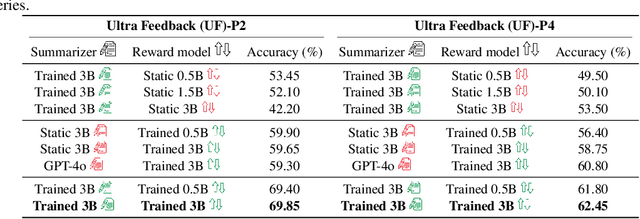
As everyday use cases of large language model (LLM) AI assistants have expanded, it is becoming increasingly important to personalize responses to align to different users' preferences and goals. While reinforcement learning from human feedback (RLHF) is effective at improving LLMs to be generally more helpful and fluent, it does not account for variability across users, as it models the entire user population with a single reward model. We present a novel framework, Preference Learning Using Summarization (PLUS), that learns text-based summaries of each user's preferences, characteristics, and past conversations. These summaries condition the reward model, enabling it to make personalized predictions about the types of responses valued by each user. We train the user-summarization model with reinforcement learning, and update the reward model simultaneously, creating an online co-adaptation loop. We show that in contrast with prior personalized RLHF techniques or with in-context learning of user information, summaries produced by PLUS capture meaningful aspects of a user's preferences. Across different pluralistic user datasets, we show that our method is robust to new users and diverse conversation topics. Additionally, we demonstrate that the textual summaries generated about users can be transferred for zero-shot personalization of stronger, proprietary models like GPT-4. The resulting user summaries are not only concise and portable, they are easy for users to interpret and modify, allowing for more transparency and user control in LLM alignment.
Enhancing Personalized Multi-Turn Dialogue with Curiosity Reward
Apr 04, 2025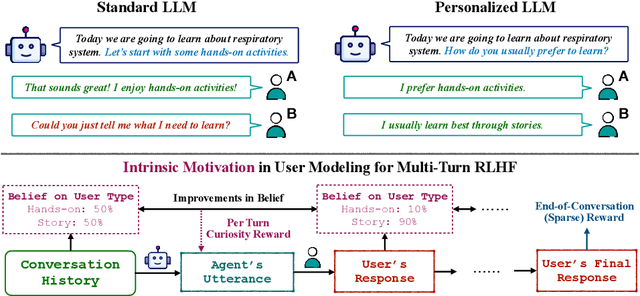
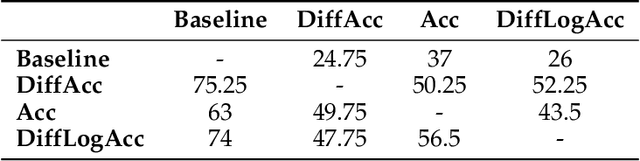
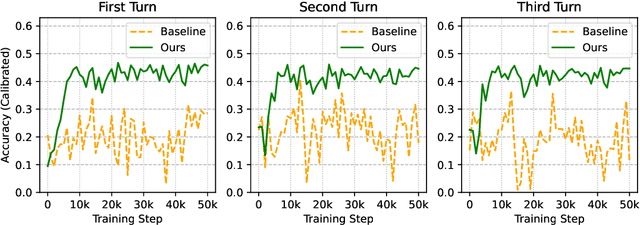
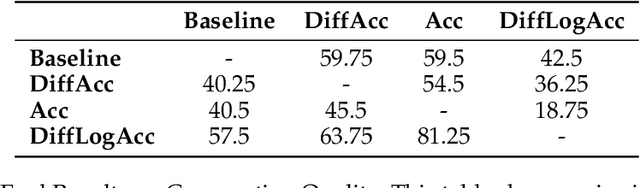
Effective conversational agents must be able to personalize their behavior to suit a user's preferences, personality, and attributes, whether they are assisting with writing tasks or operating in domains like education or healthcare. Current training methods like Reinforcement Learning from Human Feedback (RLHF) prioritize helpfulness and safety but fall short in fostering truly empathetic, adaptive, and personalized interactions. Traditional approaches to personalization often rely on extensive user history, limiting their effectiveness for new or context-limited users. To overcome these limitations, we propose to incorporate an intrinsic motivation to improve the conversational agents's model of the user as an additional reward alongside multi-turn RLHF. This reward mechanism encourages the agent to actively elicit user traits by optimizing conversations to increase the accuracy of its user model. Consequently, the policy agent can deliver more personalized interactions through obtaining more information about the user. We applied our method both education and fitness settings, where LLMs teach concepts or recommend personalized strategies based on users' hidden learning style or lifestyle attributes. Using LLM-simulated users, our approach outperformed a multi-turn RLHF baseline in revealing information about the users' preferences, and adapting to them.
Infer Human's Intentions Before Following Natural Language Instructions
Sep 26, 2024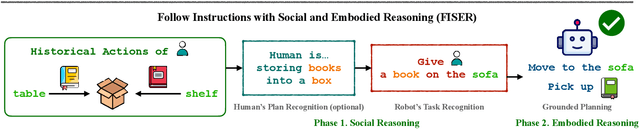

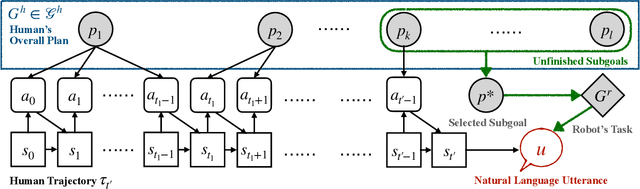

For AI agents to be helpful to humans, they should be able to follow natural language instructions to complete everyday cooperative tasks in human environments. However, real human instructions inherently possess ambiguity, because the human speakers assume sufficient prior knowledge about their hidden goals and intentions. Standard language grounding and planning methods fail to address such ambiguities because they do not model human internal goals as additional partially observable factors in the environment. We propose a new framework, Follow Instructions with Social and Embodied Reasoning (FISER), aiming for better natural language instruction following in collaborative embodied tasks. Our framework makes explicit inferences about human goals and intentions as intermediate reasoning steps. We implement a set of Transformer-based models and evaluate them over a challenging benchmark, HandMeThat. We empirically demonstrate that using social reasoning to explicitly infer human intentions before making action plans surpasses purely end-to-end approaches. We also compare our implementation with strong baselines, including Chain of Thought prompting on the largest available pre-trained language models, and find that FISER provides better performance on the embodied social reasoning tasks under investigation, reaching the state-of-the-art on HandMeThat.
Toward a More Complete OMR Solution
Aug 31, 2024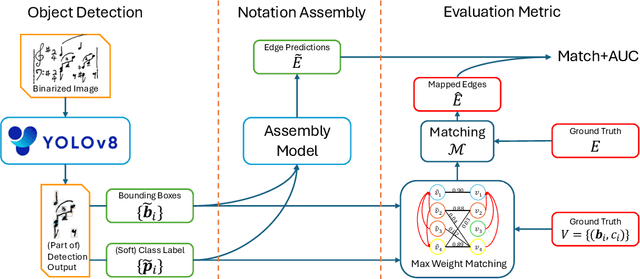
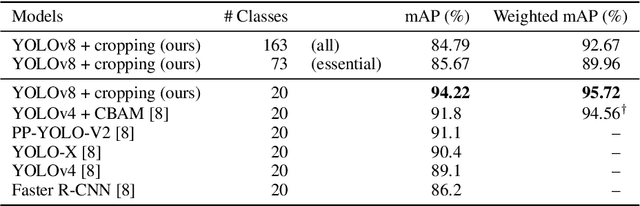


Optical music recognition (OMR) aims to convert music notation into digital formats. One approach to tackle OMR is through a multi-stage pipeline, where the system first detects visual music notation elements in the image (object detection) and then assembles them into a music notation (notation assembly). Most previous work on notation assembly unrealistically assumes perfect object detection. In this study, we focus on the MUSCIMA++ v2.0 dataset, which represents musical notation as a graph with pairwise relationships among detected music objects, and we consider both stages together. First, we introduce a music object detector based on YOLOv8, which improves detection performance. Second, we introduce a supervised training pipeline that completes the notation assembly stage based on detection output. We find that this model is able to outperform existing models trained on perfect detection output, showing the benefit of considering the detection and assembly stages in a more holistic way. These findings, together with our novel evaluation metric, are important steps toward a more complete OMR solution.
Personalizing Reinforcement Learning from Human Feedback with Variational Preference Learning
Aug 19, 2024



Reinforcement Learning from Human Feedback (RLHF) is a powerful paradigm for aligning foundation models to human values and preferences. However, current RLHF techniques cannot account for the naturally occurring differences in individual human preferences across a diverse population. When these differences arise, traditional RLHF frameworks simply average over them, leading to inaccurate rewards and poor performance for individual subgroups. To address the need for pluralistic alignment, we develop a class of multimodal RLHF methods. Our proposed techniques are based on a latent variable formulation - inferring a novel user-specific latent and learning reward models and policies conditioned on this latent without additional user-specific data. While conceptually simple, we show that in practice, this reward modeling requires careful algorithmic considerations around model architecture and reward scaling. To empirically validate our proposed technique, we first show that it can provide a way to combat underspecification in simulated control problems, inferring and optimizing user-specific reward functions. Next, we conduct experiments on pluralistic language datasets representing diverse user preferences and demonstrate improved reward function accuracy. We additionally show the benefits of this probabilistic framework in terms of measuring uncertainty, and actively learning user preferences. This work enables learning from diverse populations of users with divergent preferences, an important challenge that naturally occurs in problems from robot learning to foundation model alignment.
HandMeThat: Human-Robot Communication in Physical and Social Environments
Oct 05, 2023We introduce HandMeThat, a benchmark for a holistic evaluation of instruction understanding and following in physical and social environments. While previous datasets primarily focused on language grounding and planning, HandMeThat considers the resolution of human instructions with ambiguities based on the physical (object states and relations) and social (human actions and goals) information. HandMeThat contains 10,000 episodes of human-robot interactions. In each episode, the robot first observes a trajectory of human actions towards her internal goal. Next, the robot receives a human instruction and should take actions to accomplish the subgoal set through the instruction. In this paper, we present a textual interface for our benchmark, where the robot interacts with a virtual environment through textual commands. We evaluate several baseline models on HandMeThat, and show that both offline and online reinforcement learning algorithms perform poorly on HandMeThat, suggesting significant room for future work on physical and social human-robot communications and interactions.