 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward a More Complete OMR Solution
Paper and Code
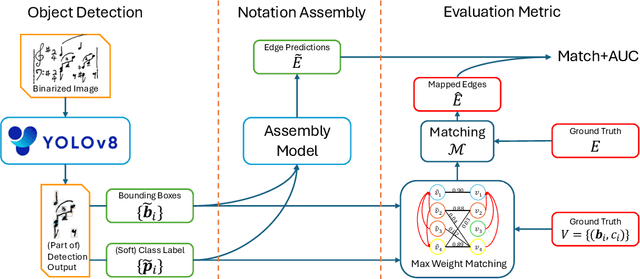
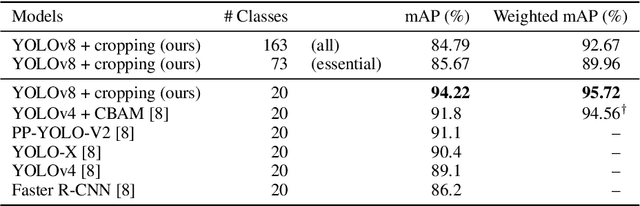


Optical music recognition (OMR) aims to convert music notation into digital formats. One approach to tackle OMR is through a multi-stage pipeline, where the system first detects visual music notation elements in the image (object detection) and then assembles them into a music notation (notation assembly). Most previous work on notation assembly unrealistically assumes perfect object detection. In this study, we focus on the MUSCIMA++ v2.0 dataset, which represents musical notation as a graph with pairwise relationships among detected music objects, and we consider both stages together. First, we introduce a music object detector based on YOLOv8, which improves detection performance. Second, we introduce a supervised training pipeline that completes the notation assembly stage based on detection output. We find that this model is able to outperform existing models trained on perfect detection output, showing the benefit of considering the detection and assembly stages in a more holistic way. These findings, together with our novel evaluation metric, are important steps toward a more complete OMR solution.