 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini Embedding 2: A Native Multimodal Embedding Model from Gemini
May 26, 2026We introduce Gemini Embedding 2, a native multimodal embedding model that allows embedding video, audio, image, and text modalities in a unified representation space. We leverage the multimodal capabilities of Gemini to produce embeddings for arbitrary combinations of interleaved inputs across all these modalities that generalize well across a wide variety of tasks. Applying large-scale contrastive learning in a multi-task multi-stage training setup, we achieve state-of-the-art performance on key embedding benchmarks including unimodal, cross-modal, and multimodal retrieval spanning a diverse set of tasks. We show that our embedding model demonstrates strong performance (with a score of 62.9 R@1 on MSCOCO, 68.8 NDCG@10 on Vatex, 69.9 on MTEB multilingual and 84.0 on MTEB Code) across a variety of tasks surpassing the performance of specialized models. These unified capabilities make Gemini Embedding 2 a promising candidate for downstream use cases such as RAG, recommendation and search. Furthermore, its robust zero-shot performance across distinct fields - from astronomy and bioscience to fine arts and the culinary arts - establishes it as a highly reliable, out-of-the-box representation even for specialized domains.
Tracing the Thought of a Grandmaster-level Chess-Playing Transformer
Apr 11, 2026While modern transformer neural networks achieve grandmaster-level performance in chess and other reasoning tasks, their internal computation process remains largely opaque. Focusing on Leela Chess Zero (LC0), we introduce a sparse decomposition framework to interpret its internal computation by decomposing its MLP and attention modules with sparse replacement layers, which capture the primary computation process of LC0. We conduct a detailed case study showing that these pathways expose rich, interpretable tactical considerations that are empirically verifiable. We further introduce three quantitative metrics and show that LC0 exhibits parallel reasoning behavior consistent with the inductive bias of its policy head architecture. To the best of our knowledge, this is the first work to decompose the internal computation of a transformer on both MLP and attention modules for interpretability. Combining sparse replacement layers and causal interventions in LC0 provides a comprehensive understanding of advanced tactical reasoning, offering critical insights into the underlying mechanisms of superhuman systems. Our code is available at https://github.com/JacklE0niden/Leela-SAEs.
Enhancing Personalized Multi-Turn Dialogue with Curiosity Reward
Apr 04, 2025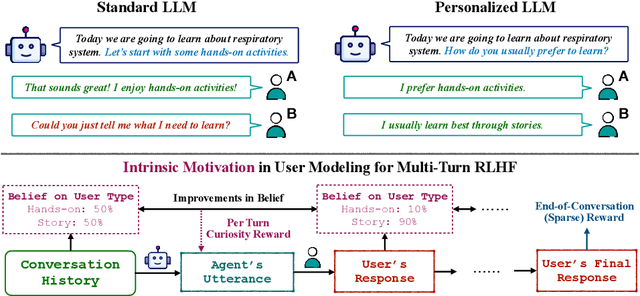
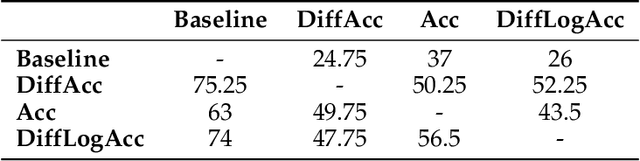
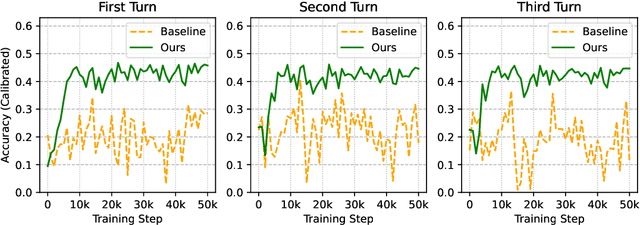
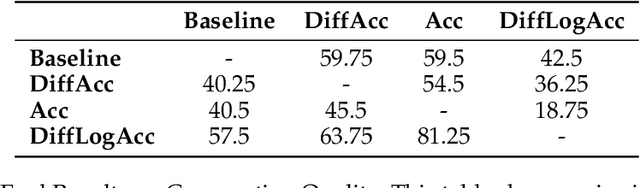
Effective conversational agents must be able to personalize their behavior to suit a user's preferences, personality, and attributes, whether they are assisting with writing tasks or operating in domains like education or healthcare. Current training methods like Reinforcement Learning from Human Feedback (RLHF) prioritize helpfulness and safety but fall short in fostering truly empathetic, adaptive, and personalized interactions. Traditional approaches to personalization often rely on extensive user history, limiting their effectiveness for new or context-limited users. To overcome these limitations, we propose to incorporate an intrinsic motivation to improve the conversational agents's model of the user as an additional reward alongside multi-turn RLHF. This reward mechanism encourages the agent to actively elicit user traits by optimizing conversations to increase the accuracy of its user model. Consequently, the policy agent can deliver more personalized interactions through obtaining more information about the user. We applied our method both education and fitness settings, where LLMs teach concepts or recommend personalized strategies based on users' hidden learning style or lifestyle attributes. Using LLM-simulated users, our approach outperformed a multi-turn RLHF baseline in revealing information about the users' preferences, and adapting to them.
Deliberation in Latent Space via Differentiable Cache Augmentation
Dec 23, 2024



Techniques enabling large language models (LLMs) to "think more" by generating and attending to intermediate reasoning steps have shown promise in solving complex problems. However, the standard approaches generate sequences of discrete tokens immediately before responding, and so they can incur significant latency costs and be challenging to optimize. In this work, we demonstrate that a frozen LLM can be augmented with an offline coprocessor that operates on the model's key-value (kv) cache. This coprocessor augments the cache with a set of latent embeddings designed to improve the fidelity of subsequent decoding. We train this coprocessor using the language modeling loss from the decoder on standard pretraining data, while keeping the decoder itself frozen. This approach enables the model to learn, in an end-to-end differentiable fashion, how to distill additional computation into its kv-cache. Because the decoder remains unchanged, the coprocessor can operate offline and asynchronously, and the language model can function normally if the coprocessor is unavailable or if a given cache is deemed not to require extra computation. We show experimentally that when a cache is augmented, the decoder achieves lower perplexity on numerous subsequent tokens. Furthermore, even without any task-specific training, our experiments demonstrate that cache augmentation consistently reduces perplexity and improves performance across a range of reasoning-intensive tasks.
RLPF: Reinforcement Learning from Prediction Feedback for User Summarization with LLMs
Sep 06, 2024



LLM-powered personalization agent systems employ Large Language Models (LLMs) to predict users' behavior from their past activities. However, their effectiveness often hinges on the ability to effectively leverage extensive, long user historical data due to its inherent noise and length of such data. Existing pretrained LLMs may generate summaries that are concise but lack the necessary context for downstream tasks, hindering their utility in personalization systems. To address these challenges, we introduce Reinforcement Learning from Prediction Feedback (RLPF). RLPF fine-tunes LLMs to generate concise, human-readable user summaries that are optimized for downstream task performance. By maximizing the usefulness of the generated summaries, RLPF effectively distills extensive user history data while preserving essential information for downstream tasks. Our empirical evaluation demonstrates significant improvements in both extrinsic downstream task utility and intrinsic summary quality, surpassing baseline methods by up to 22% on downstream task performance and achieving an up to 84.59% win rate on Factuality, Abstractiveness, and Readability. RLPF also achieves a remarkable 74% reduction in context length while improving performance on 16 out of 19 unseen tasks and/or datasets, showcasing its generalizability. This approach offers a promising solution for enhancing LLM personalization by effectively transforming long, noisy user histories into informative and human-readable representations.
User-LLM: Efficient LLM Contextualization with User Embeddings
Feb 21, 2024Large language models (LLMs) have revolutionized natural language processing. However, effectively incorporating complex and potentially noisy user interaction data remains a challenge. To address this, we propose User-LLM, a novel framework that leverages user embeddings to contextualize LLMs. These embeddings, distilled from diverse user interactions using self-supervised pretraining, capture latent user preferences and their evolution over time. We integrate these user embeddings with LLMs through cross-attention and soft-prompting, enabling LLMs to dynamically adapt to user context. Our comprehensive experiments on MovieLens, Amazon Review, and Google Local Review datasets demonstrate significant performance gains across various tasks. Notably, our approach outperforms text-prompt-based contextualization on long sequence tasks and tasks that require deep user understanding while being computationally efficient. We further incorporate Perceiver layers to streamline the integration between user encoders and LLMs, reducing computational demands.