 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing User Sequence Modeling through Barlow Twins-based Self-Supervised Learning
May 02, 2025
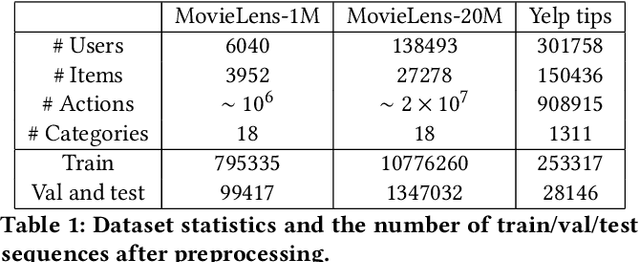


User sequence modeling is crucial for modern large-scale recommendation systems, as it enables the extraction of informative representations of users and items from their historical interactions. These user representations are widely used for a variety of downstream tasks to enhance users' online experience. A key challenge for learning these representations is the lack of labeled training data. While self-supervised learning (SSL) methods have emerged as a promising solution for learning representations from unlabeled data, many existing approaches rely on extensive negative sampling, which can be computationally expensive and may not always be feasible in real-world scenario. In this work, we propose an adaptation of Barlow Twins, a state-of-the-art SSL methods, to user sequence modeling by incorporating suitable augmentation methods. Our approach aims to mitigate the need for large negative sample batches, enabling effective representation learning with smaller batch sizes and limited labeled data. We evaluate our method on the MovieLens-1M, MovieLens-20M, and Yelp datasets, demonstrating that our method consistently outperforms the widely-used dual encoder model across three downstream tasks, achieving an 8%-20% improvement in accuracy. Our findings underscore the effectiveness of our approach in extracting valuable sequence-level information for user modeling, particularly in scenarios where labeled data is scarce and negative examples are limited.
RLPF: Reinforcement Learning from Prediction Feedback for User Summarization with LLMs
Sep 06, 2024



LLM-powered personalization agent systems employ Large Language Models (LLMs) to predict users' behavior from their past activities. However, their effectiveness often hinges on the ability to effectively leverage extensive, long user historical data due to its inherent noise and length of such data. Existing pretrained LLMs may generate summaries that are concise but lack the necessary context for downstream tasks, hindering their utility in personalization systems. To address these challenges, we introduce Reinforcement Learning from Prediction Feedback (RLPF). RLPF fine-tunes LLMs to generate concise, human-readable user summaries that are optimized for downstream task performance. By maximizing the usefulness of the generated summaries, RLPF effectively distills extensive user history data while preserving essential information for downstream tasks. Our empirical evaluation demonstrates significant improvements in both extrinsic downstream task utility and intrinsic summary quality, surpassing baseline methods by up to 22% on downstream task performance and achieving an up to 84.59% win rate on Factuality, Abstractiveness, and Readability. RLPF also achieves a remarkable 74% reduction in context length while improving performance on 16 out of 19 unseen tasks and/or datasets, showcasing its generalizability. This approach offers a promising solution for enhancing LLM personalization by effectively transforming long, noisy user histories into informative and human-readable representations.
UserSumBench: A Benchmark Framework for Evaluating User Summarization Approaches
Aug 30, 2024



Large language models (LLMs) have shown remarkable capabilities in generating user summaries from a long list of raw user activity data. These summaries capture essential user information such as preferences and interests, and therefore are invaluable for LLM-based personalization applications, such as explainable recommender systems. However, the development of new summarization techniques is hindered by the lack of ground-truth labels, the inherent subjectivity of user summaries, and human evaluation which is often costly and time-consuming. To address these challenges, we introduce \UserSumBench, a benchmark framework designed to facilitate iterative development of LLM-based summarization approaches. This framework offers two key components: (1) A reference-free summary quality metric. We show that this metric is effective and aligned with human preferences across three diverse datasets (MovieLens, Yelp and Amazon Review). (2) A novel robust summarization method that leverages time-hierarchical summarizer and self-critique verifier to produce high-quality summaries while eliminating hallucination. This method serves as a strong baseline for further innovation in summarization techniques.
User-LLM: Efficient LLM Contextualization with User Embeddings
Feb 21, 2024Large language models (LLMs) have revolutionized natural language processing. However, effectively incorporating complex and potentially noisy user interaction data remains a challenge. To address this, we propose User-LLM, a novel framework that leverages user embeddings to contextualize LLMs. These embeddings, distilled from diverse user interactions using self-supervised pretraining, capture latent user preferences and their evolution over time. We integrate these user embeddings with LLMs through cross-attention and soft-prompting, enabling LLMs to dynamically adapt to user context. Our comprehensive experiments on MovieLens, Amazon Review, and Google Local Review datasets demonstrate significant performance gains across various tasks. Notably, our approach outperforms text-prompt-based contextualization on long sequence tasks and tasks that require deep user understanding while being computationally efficient. We further incorporate Perceiver layers to streamline the integration between user encoders and LLMs, reducing computational demands.
Deep Transformer Models for Time Series Forecasting: The Influenza Prevalence Case
Jan 23, 2020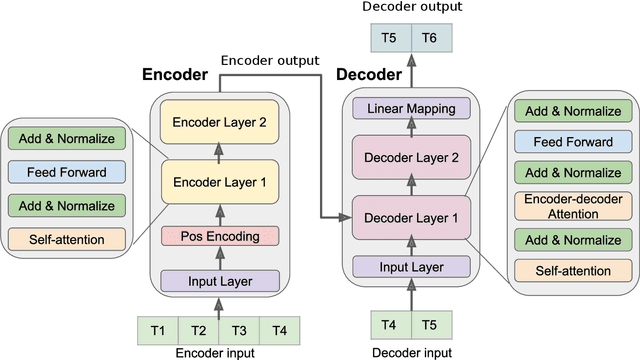


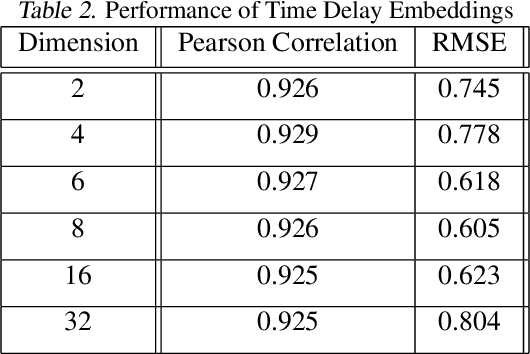
In this paper, we present a new approach to time series forecasting. Time series data are prevalent in many scientific and engineering disciplines. Time series forecasting is a crucial task in modeling time series data, and is an important area of machine learning. In this work we developed a novel method that employs Transformer-based machine learning models to forecast time series data. This approach works by leveraging self-attention mechanisms to learn complex patterns and dynamics from time series data. Moreover, it is a generic framework and can be applied to univariate and multivariate time series data, as well as time series embeddings. Using influenza-like illness (ILI) forecasting as a case study, we show that the forecasting results produced by our approach are favorably comparable to the state-of-the-art.