 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLimits of KV Cache Compression for Tensor Attention based Autoregressive Transformers
Mar 14, 2025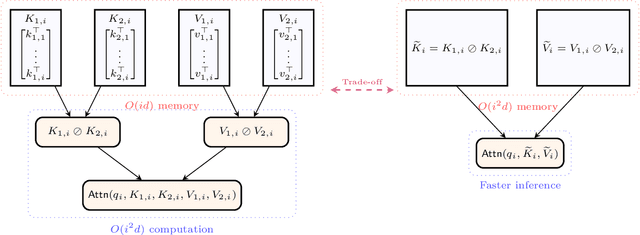
The key-value (KV) cache in autoregressive transformers presents a significant bottleneck during inference, which restricts the context length capabilities of large language models (LLMs). While previous work analyzes the fundamental space complexity barriers in standard attention mechanism [Haris and Onak, 2025], our work generalizes the space complexity barriers result to tensor attention version. Our theoretical contributions rely on a novel reduction from communication complexity and deduce the memory lower bound for tensor-structured attention mechanisms when $d = \Omega(\log n)$. In the low dimensional regime where $d = o(\log n)$, we analyze the theoretical bounds of the space complexity as well. Overall, our work provides a theoretical foundation for us to understand the compression-expressivity tradeoff in tensor attention mechanisms and offers more perspectives in developing more memory-efficient transformer architectures.
Scaling Law Phenomena Across Regression Paradigms: Multiple and Kernel Approaches
Mar 03, 2025Recently, Large Language Models (LLMs) have achieved remarkable success. A key factor behind this success is the scaling law observed by OpenAI. Specifically, for models with Transformer architecture, the test loss exhibits a power-law relationship with model size, dataset size, and the amount of computation used in training, demonstrating trends that span more than seven orders of magnitude. This scaling law challenges traditional machine learning wisdom, notably the Oscar Scissors principle, which suggests that an overparametrized algorithm will overfit the training datasets, resulting in poor test performance. Recent research has also identified the scaling law in simpler machine learning contexts, such as linear regression. However, fully explaining the scaling law in large practical models remains an elusive goal. In this work, we advance our understanding by demonstrating that the scaling law phenomenon extends to multiple regression and kernel regression settings, which are significantly more expressive and powerful than linear methods. Our analysis provides deeper insights into the scaling law, potentially enhancing our understanding of LLMs.
SHARP: Accelerating Language Model Inference by SHaring Adjacent layers with Recovery Parameters
Feb 11, 2025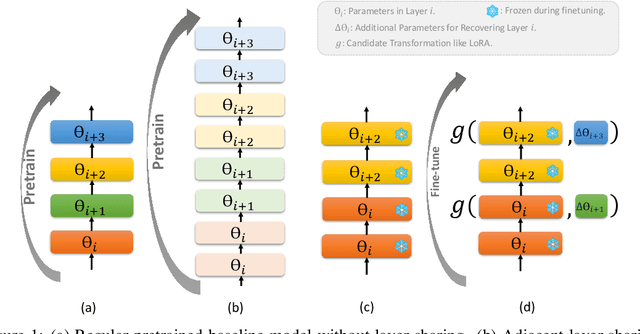

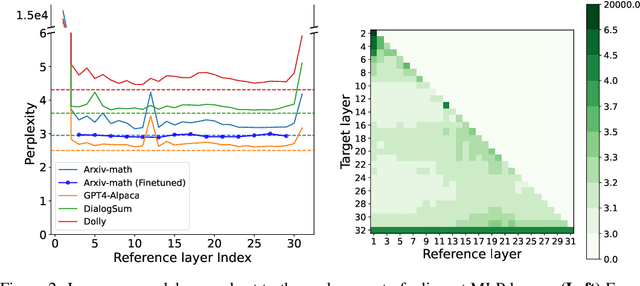
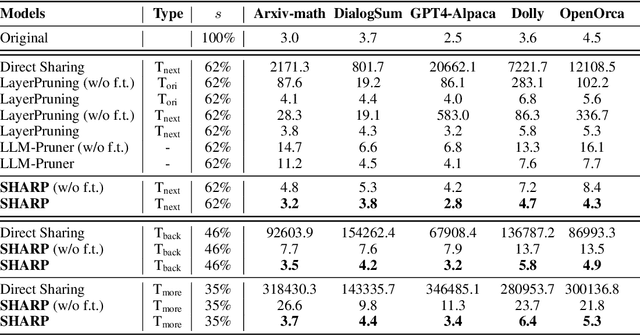
While Large language models (LLMs) have advanced natural language processing tasks, their growing computational and memory demands make deployment on resource-constrained devices like mobile phones increasingly challenging. In this paper, we propose SHARP (SHaring Adjacent Layers with Recovery Parameters), a novel approach to accelerate LLM inference by sharing parameters across adjacent layers, thus reducing memory load overhead, while introducing low-rank recovery parameters to maintain performance. Inspired by observations that consecutive layers have similar outputs, SHARP employs a two-stage recovery process: Single Layer Warmup (SLW), and Supervised Fine-Tuning (SFT). The SLW stage aligns the outputs of the shared layers using L_2 loss, providing a good initialization for the following SFT stage to further restore the model performance. Extensive experiments demonstrate that SHARP can recover the model's perplexity on various in-distribution tasks using no more than 50k fine-tuning data while reducing the number of stored MLP parameters by 38% to 65%. We also conduct several ablation studies of SHARP and show that replacing layers towards the later parts of the model yields better performance retention, and that different recovery parameterizations perform similarly when parameter counts are matched. Furthermore, SHARP saves 42.8% in model storage and reduces the total inference time by 42.2% compared to the original Llama2-7b model on mobile devices. Our results highlight SHARP as an efficient solution for reducing inference costs in deploying LLMs without the need for pretraining-scale resources.
Universal Approximation of Visual Autoregressive Transformers
Feb 10, 2025We investigate the fundamental limits of transformer-based foundation models, extending our analysis to include Visual Autoregressive (VAR) transformers. VAR represents a big step toward generating images using a novel, scalable, coarse-to-fine ``next-scale prediction'' framework. These models set a new quality bar, outperforming all previous methods, including Diffusion Transformers, while having state-of-the-art performance for image synthesis tasks. Our primary contributions establish that, for single-head VAR transformers with a single self-attention layer and single interpolation layer, the VAR Transformer is universal. From the statistical perspective, we prove that such simple VAR transformers are universal approximators for any image-to-image Lipschitz functions. Furthermore, we demonstrate that flow-based autoregressive transformers inherit similar approximation capabilities. Our results provide important design principles for effective and computationally efficient VAR Transformer strategies that can be used to extend their utility to more sophisticated VAR models in image generation and other related areas.
Fast Gradient Computation for RoPE Attention in Almost Linear Time
Dec 23, 2024The Rotary Position Embedding (RoPE) mechanism has become a powerful enhancement to the Transformer architecture, which enables models to capture token relationships when encoding positional information. However, the RoPE mechanisms make the computations of attention mechanisms more complicated, which makes efficient algorithms challenging. Earlier research introduced almost linear time, i.e., $n^{1+o(1)}$ where $n$ is the number of input tokens, algorithms for the forward computation under specific parameter settings. However, achieving a subquadratic time algorithm for other parameter regimes remains impossible unless the widely accepted Strong Exponential Time Hypothesis (SETH) is disproven. In this work, we develop the first almost linear time algorithm for backward computations in the RoPE-based attention under bounded entries. Our approach builds on recent advancements in fast RoPE attention computations, utilizing a novel combination of the polynomial method and the Fast Fourier Transform. Furthermore, we show that with lower bounds derived from the SETH, the bounded entry condition is necessary for subquadratic performance.
The Computational Limits of State-Space Models and Mamba via the Lens of Circuit Complexity
Dec 09, 2024In this paper, we analyze the computational limitations of Mamba and State-space Models (SSMs) by using the circuit complexity framework. Despite Mamba's stateful design and recent attention as a strong candidate to outperform Transformers, we have demonstrated that both Mamba and SSMs with $\mathrm{poly}(n)$-precision and constant-depth layers reside within the $\mathsf{DLOGTIME}$-uniform $\mathsf{TC}^0$ complexity class. This result indicates Mamba has the same computational capabilities as Transformer theoretically, and it cannot solve problems like arithmetic formula problems, boolean formula value problems, and permutation composition problems if $\mathsf{TC}^0 \neq \mathsf{NC}^1$. Therefore, it challenges the assumption Mamba is more computationally expressive than Transformers. Our contributions include rigorous proofs showing that Selective SSM and Mamba architectures can be simulated by $\mathsf{DLOGTIME}$-uniform $\mathsf{TC}^0$ circuits, and they cannot solve problems outside $\mathsf{TC}^0$.
Rethinking Data Synthesis: A Teacher Model Training Recipe with Interpretation
Oct 27, 2024
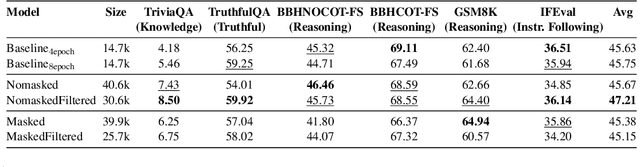
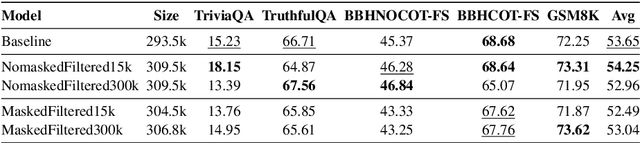
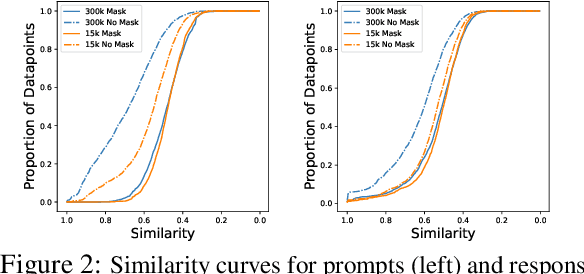
Recent advances in large language model (LLM) training have highlighted the need for diverse, high-quality instruction data. Recently, many works are exploring synthetic data generation using LLMs. However, they primarily focus on prompt engineering with standard supervised instruction-finetuned models, which contains a fundamental limitation: these models are optimized for general question-answering/problem-solving rather than data generation. We propose a paradigm shift named \textbf{NOMAD} by investigating how to specifically train models for data generation, demonstrating that this task differs significantly from training a classical LM. We identify two key factors: no-prompt-masked training and proper training set size selection. Our method, NOMAD, shows substantial improvements over baselines, achieving >4\% gains in TriviaQA and >2\% in GSM8K with limited training data. Finally, we offer new insights by interpreting synthetic data through the lenses of "relevance" and "novelty".
I Know About "Up"! Enhancing Spatial Reasoning in Visual Language Models Through 3D Reconstruction
Jul 19, 2024



Visual Language Models (VLMs) are essential for various tasks, particularly visual reasoning tasks, due to their robust multi-modal information integration, visual reasoning capabilities, and contextual awareness. However, existing \VLMs{}' visual spatial reasoning capabilities are often inadequate, struggling even with basic tasks such as distinguishing left from right. To address this, we propose the \ours{} model, designed to enhance the visual spatial reasoning abilities of VLMS. ZeroVLM employs Zero-1-to-3, a 3D reconstruction model for obtaining different views of the input images and incorporates a prompting mechanism to further improve visual spatial reasoning. Experimental results on four visual spatial reasoning datasets show that our \ours{} achieves up to 19.48% accuracy improvement, which indicates the effectiveness of the 3D reconstruction and prompting mechanisms of our ZeroVLM.
Cost-Effective Proxy Reward Model Construction with On-Policy and Active Learning
Jul 02, 2024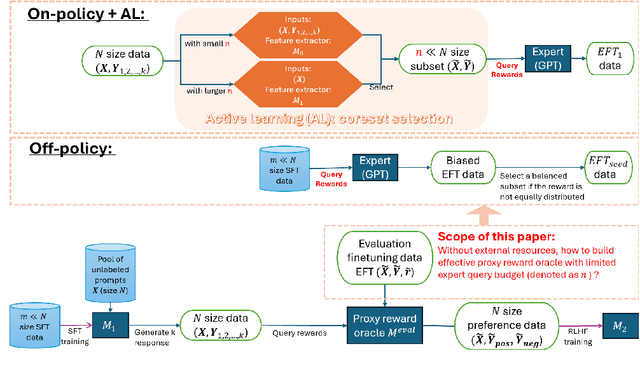
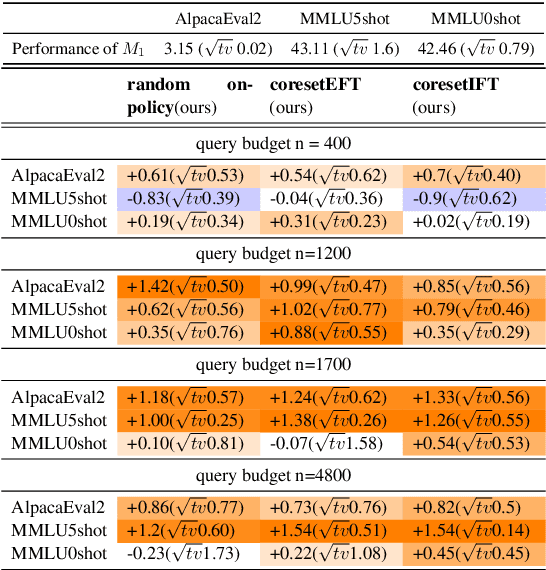

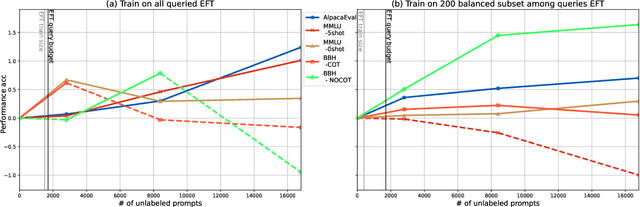
Reinforcement learning with human feedback (RLHF), as a widely adopted approach in current large language model pipelines, is \textit{bottlenecked by the size of human preference data}. While traditional methods rely on offline preference dataset constructions, recent approaches have shifted towards online settings, where a learner uses a small amount of labeled seed data and a large pool of unlabeled prompts to iteratively construct new preference data through self-generated responses and high-quality reward/preference feedback. However, most current online algorithms still focus on preference labeling during policy model updating with given feedback oracles, which incurs significant expert query costs. \textit{We are the first to explore cost-effective proxy reward oracles construction strategies for further labeling preferences or rewards with extremely limited labeled data and expert query budgets}. Our approach introduces two key innovations: (1) on-policy query to avoid OOD and imbalance issues in seed data, and (2) active learning to select the most informative data for preference queries. Using these methods, we train a evaluation model with minimal expert-labeled data, which then effectively labels nine times more preference pairs for further RLHF training. For instance, our model using Direct Preference Optimization (DPO) gains around over 1% average improvement on AlpacaEval2, MMLU-5shot and MMLU-0shot, with only 1.7K query cost. Our methodology is orthogonal to other direct expert query-based strategies and therefore might be integrated with them to further reduce query costs.
Decoding-Time Language Model Alignment with Multiple Objectives
Jun 27, 2024



Aligning language models (LMs) to human preferences has emerged as a critical pursuit, enabling these models to better serve diverse user needs. Existing methods primarily focus on optimizing LMs for a single reward function, limiting their adaptability to varied objectives. Here, we propose $\textbf{multi-objective decoding (MOD)}$, a decoding-time algorithm that outputs the next token from a linear combination of predictions of all base models, for any given weightings over different objectives. We exploit a common form among a family of $f$-divergence regularized alignment approaches (such as PPO, DPO, and their variants) to identify a closed-form solution by Legendre transform, and derive an efficient decoding strategy. Theoretically, we show why existing approaches can be sub-optimal even in natural settings and obtain optimality guarantees for our method. Empirical results demonstrate the effectiveness of the algorithm. For example, compared to a parameter-merging baseline, MOD achieves 12.8% overall reward improvement when equally optimizing towards $3$ objectives. Moreover, we experiment with MOD on combining three fully-finetuned LLMs of different model sizes, each aimed at different objectives such as safety, coding, and general user preference. Unlike traditional methods that require careful curation of a mixture of datasets to achieve comprehensive improvement, we can quickly experiment with preference weightings using MOD to find the best combination of models. Our best combination reduces toxicity on Toxigen to nearly 0% and achieves 7.9--33.3% improvement across other three metrics ($\textit{i.e.}$, Codex@1, GSM-COT, BBH-COT).