 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Data Synthesis: A Teacher Model Training Recipe with Interpretation
Paper and Code
Oct 27, 2024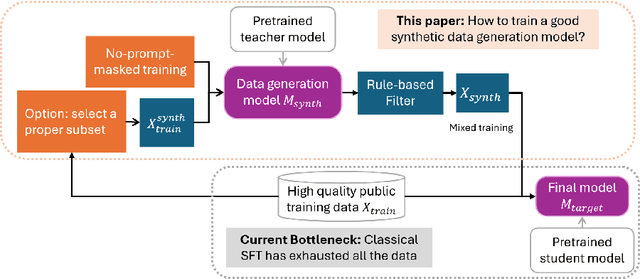
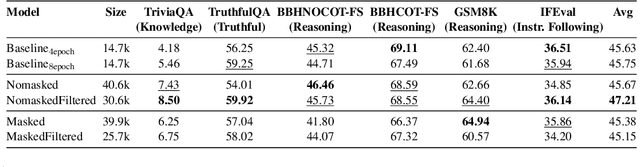
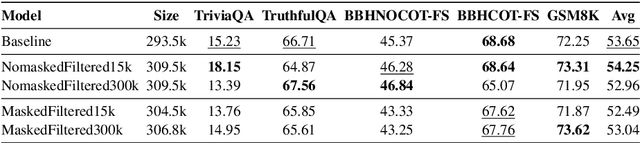
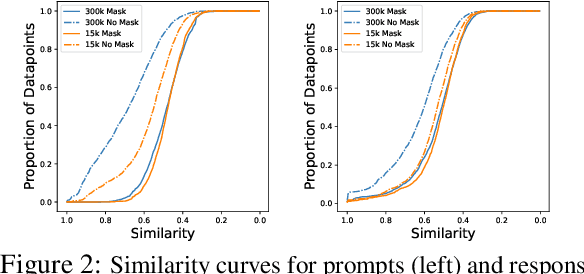
Recent advances in large language model (LLM) training have highlighted the need for diverse, high-quality instruction data. Recently, many works are exploring synthetic data generation using LLMs. However, they primarily focus on prompt engineering with standard supervised instruction-finetuned models, which contains a fundamental limitation: these models are optimized for general question-answering/problem-solving rather than data generation. We propose a paradigm shift named \textbf{NOMAD} by investigating how to specifically train models for data generation, demonstrating that this task differs significantly from training a classical LM. We identify two key factors: no-prompt-masked training and proper training set size selection. Our method, NOMAD, shows substantial improvements over baselines, achieving >4\% gains in TriviaQA and >2\% in GSM8K with limited training data. Finally, we offer new insights by interpreting synthetic data through the lenses of "relevance" and "novelty".