 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Data Synthesis: A Teacher Model Training Recipe with Interpretation
Oct 27, 2024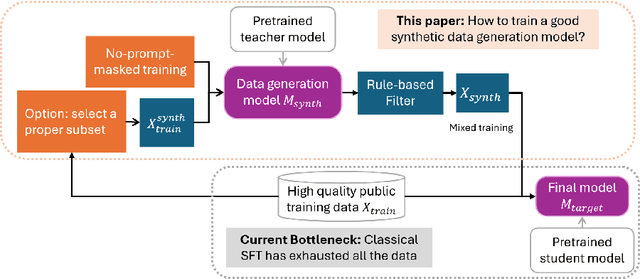
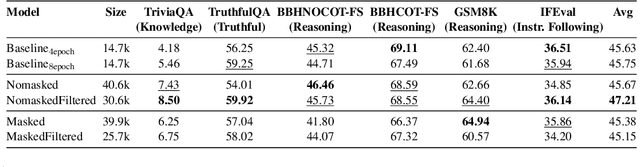
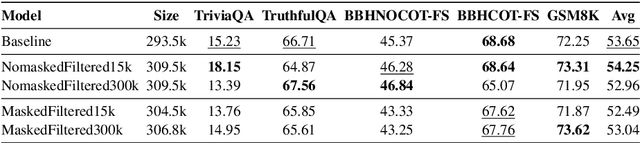
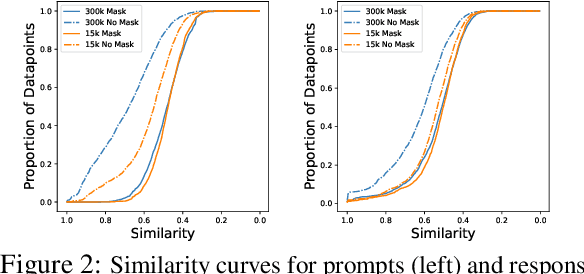
Recent advances in large language model (LLM) training have highlighted the need for diverse, high-quality instruction data. Recently, many works are exploring synthetic data generation using LLMs. However, they primarily focus on prompt engineering with standard supervised instruction-finetuned models, which contains a fundamental limitation: these models are optimized for general question-answering/problem-solving rather than data generation. We propose a paradigm shift named \textbf{NOMAD} by investigating how to specifically train models for data generation, demonstrating that this task differs significantly from training a classical LM. We identify two key factors: no-prompt-masked training and proper training set size selection. Our method, NOMAD, shows substantial improvements over baselines, achieving >4\% gains in TriviaQA and >2\% in GSM8K with limited training data. Finally, we offer new insights by interpreting synthetic data through the lenses of "relevance" and "novelty".
Optimal Reward Labeling: Bridging Offline Preference and Reward-Based Reinforcement Learning
Jun 14, 2024

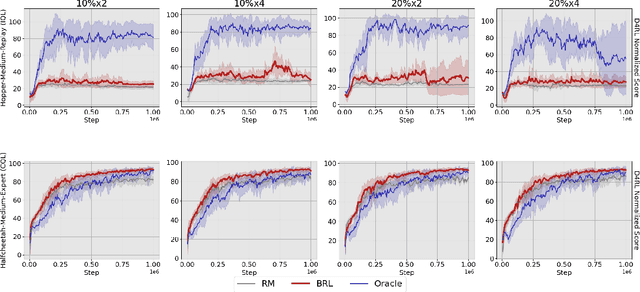

Offline reinforcement learning has become one of the most practical RL settings. A recent success story has been RLHF, offline preference-based RL (PBRL) with preference from humans. However, most existing works on offline RL focus on the standard setting with scalar reward feedback. It remains unknown how to universally transfer the existing rich understanding of offline RL from the reward-based to the preference-based setting. In this work, we propose a general framework to bridge this gap. Our key insight is transforming preference feedback to scalar rewards via optimal reward labeling (ORL), and then any reward-based offline RL algorithms can be applied to the dataset with the reward labels. We theoretically show the connection between several recent PBRL techniques and our framework combined with specific offline RL algorithms in terms of how they utilize the preference signals. By combining reward labeling with different algorithms, our framework can lead to new and potentially more efficient offline PBRL algorithms. We empirically test our framework on preference datasets based on the standard D4RL benchmark. When combined with a variety of efficient reward-based offline RL algorithms, the learning result achieved under our framework is comparable to training the same algorithm on the dataset with actual rewards in many cases and better than the recent PBRL baselines in most cases.