 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Adversarial Regularization for Offline Preference Optimization
Jan 29, 2026Learning from human feedback typically relies on preference optimization that constrains policy updates through token-level regularization. However, preference optimization for language models is particularly challenging because token-space similarity does not imply semantic or behavioral similarity. To address this challenge, we leverage latent-space regularization for language model preference optimization. We introduce GANPO, which achieves latent-space regularization by penalizing divergence between the internal representations of a policy model and a reference model. Given that latent representations are not associated with explicit probability densities, we adopt an adversarial approach inspired by GANs to minimize latent-space divergence. We integrate GANPO as a regularizer into existing offline preference optimization objectives. Experiments across multiple model architectures and tasks show consistent improvements from latent-space regularization. Further, by comparing GANPO-induced inferential biases with those from token-level regularization, we find that GANPO provides more robust structural feedback under distributional shift and noise while maintaining comparable downstream performance with minor computational overhead.
Learning a Pessimistic Reward Model in RLHF
May 26, 2025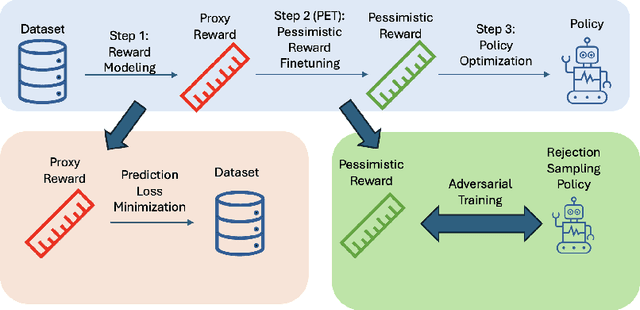


This work proposes `PET', a novel pessimistic reward fine-tuning method, to learn a pessimistic reward model robust against reward hacking in offline reinforcement learning from human feedback (RLHF). Traditional reward modeling techniques in RLHF train an imperfect reward model, on which a KL regularization plays a pivotal role in mitigating reward hacking when optimizing a policy. Such an intuition-based method still suffers from reward hacking, and the policies with large KL divergence from the dataset distribution are excluded during learning. In contrast, we show that when optimizing a policy on a pessimistic reward model fine-tuned through PET, reward hacking can be prevented without relying on any regularization. We test our methods on the standard TL;DR summarization dataset. We find that one can learn a high-quality policy on our pessimistic reward without using any regularization. Such a policy has a high KL divergence from the dataset distribution while having high performance in practice. In summary, our work shows the feasibility of learning a pessimistic reward model against reward hacking. The agent can greedily search for the policy with a high pessimistic reward without suffering from reward hacking.
Improving Assembly Code Performance with Large Language Models via Reinforcement Learning
May 16, 2025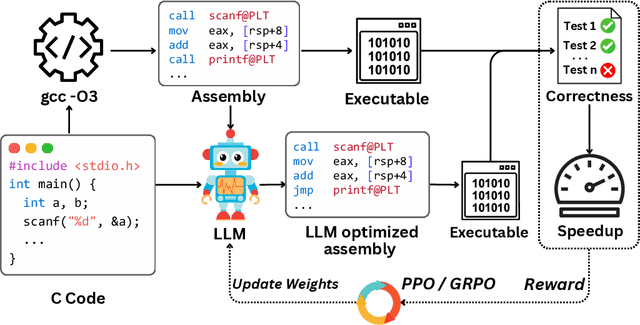
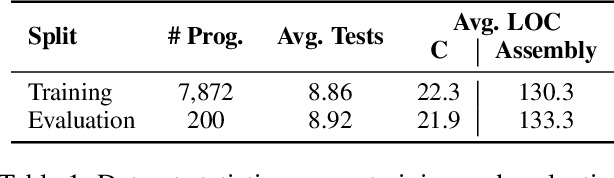


Large language models (LLMs) have demonstrated strong performance across a wide range of programming tasks, yet their potential for code optimization remains underexplored. This work investigates whether LLMs can optimize the performance of assembly code, where fine-grained control over execution enables improvements that are difficult to express in high-level languages. We present a reinforcement learning framework that trains LLMs using Proximal Policy Optimization (PPO), guided by a reward function that considers both functional correctness, validated through test cases, and execution performance relative to the industry-standard compiler gcc -O3. To support this study, we introduce a benchmark of 8,072 real-world programs. Our model, Qwen2.5-Coder-7B-PPO, achieves 96.0% test pass rates and an average speedup of 1.47x over the gcc -O3 baseline, outperforming all 20 other models evaluated, including Claude-3.7-sonnet. These results indicate that reinforcement learning can unlock the potential of LLMs to serve as effective optimizers for assembly code performance.
Robust Thompson Sampling Algorithms Against Reward Poisoning Attacks
Oct 25, 2024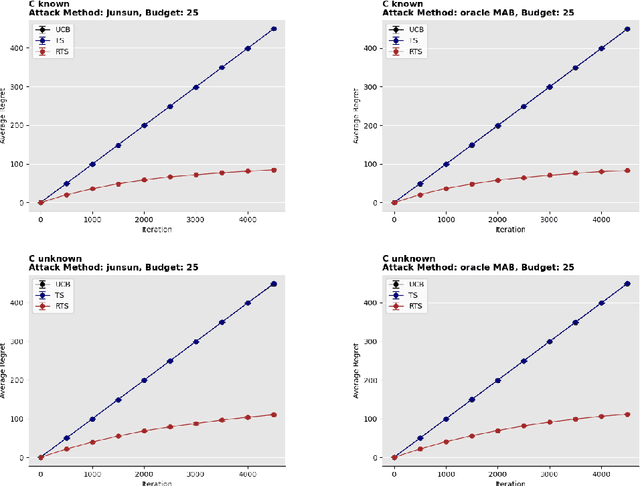


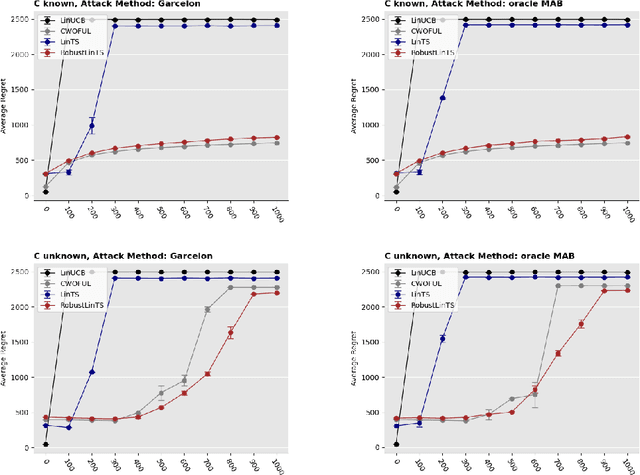
Thompson sampling is one of the most popular learning algorithms for online sequential decision-making problems and has rich real-world applications. However, current Thompson sampling algorithms are limited by the assumption that the rewards received are uncorrupted, which may not be true in real-world applications where adversarial reward poisoning exists. To make Thompson sampling more reliable, we want to make it robust against adversarial reward poisoning. The main challenge is that one can no longer compute the actual posteriors for the true reward, as the agent can only observe the rewards after corruption. In this work, we solve this problem by computing pseudo-posteriors that are less likely to be manipulated by the attack. We propose robust algorithms based on Thompson sampling for the popular stochastic and contextual linear bandit settings in both cases where the agent is aware or unaware of the budget of the attacker. We theoretically show that our algorithms guarantee near-optimal regret under any attack strategy.
Optimal Reward Labeling: Bridging Offline Preference and Reward-Based Reinforcement Learning
Jun 14, 2024

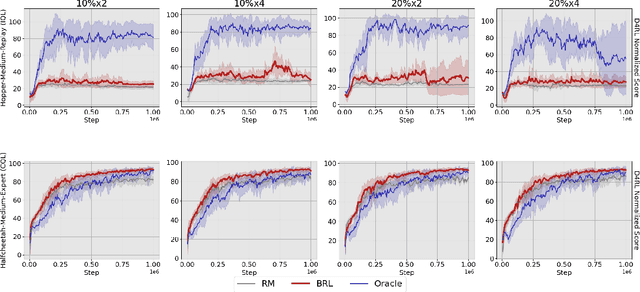

Offline reinforcement learning has become one of the most practical RL settings. A recent success story has been RLHF, offline preference-based RL (PBRL) with preference from humans. However, most existing works on offline RL focus on the standard setting with scalar reward feedback. It remains unknown how to universally transfer the existing rich understanding of offline RL from the reward-based to the preference-based setting. In this work, we propose a general framework to bridge this gap. Our key insight is transforming preference feedback to scalar rewards via optimal reward labeling (ORL), and then any reward-based offline RL algorithms can be applied to the dataset with the reward labels. We theoretically show the connection between several recent PBRL techniques and our framework combined with specific offline RL algorithms in terms of how they utilize the preference signals. By combining reward labeling with different algorithms, our framework can lead to new and potentially more efficient offline PBRL algorithms. We empirically test our framework on preference datasets based on the standard D4RL benchmark. When combined with a variety of efficient reward-based offline RL algorithms, the learning result achieved under our framework is comparable to training the same algorithm on the dataset with actual rewards in many cases and better than the recent PBRL baselines in most cases.
Reward Poisoning Attack Against Offline Reinforcement Learning
Feb 15, 2024



We study the problem of reward poisoning attacks against general offline reinforcement learning with deep neural networks for function approximation. We consider a black-box threat model where the attacker is completely oblivious to the learning algorithm and its budget is limited by constraining both the amount of corruption at each data point, and the total perturbation. We propose an attack strategy called `policy contrast attack'. The high-level idea is to make some low-performing policies appear as high-performing while making high-performing policies appear as low-performing. To the best of our knowledge, we propose the first black-box reward poisoning attack in the general offline RL setting. We provide theoretical insights on the attack design and empirically show that our attack is efficient against current state-of-the-art offline RL algorithms in different kinds of learning datasets.
Efficient Two-Phase Offline Deep Reinforcement Learning from Preference Feedback
Dec 30, 2023



In this work, we consider the offline preference-based reinforcement learning problem. We focus on the two-phase learning approach that is prevalent in previous reinforcement learning from human preference works. We find a challenge in applying two-phase learning in the offline PBRL setting that the learned utility model can be too hard for the learning agent to optimize during the second learning phase. To overcome the challenge, we propose a two-phasing learning approach under behavior regularization through action clipping. The insight is that the state-actions which are poorly covered by the dataset can only provide limited information and increase the complexity of the problem in the second learning phase. Our method ignores such state-actions during the second learning phase to achieve higher learning efficiency. We empirically verify that our method has high learning efficiency on a variety of datasets in robotic control environments.
On the Robustness of Epoch-Greedy in Multi-Agent Contextual Bandit Mechanisms
Jul 15, 2023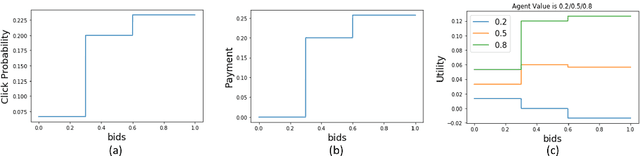
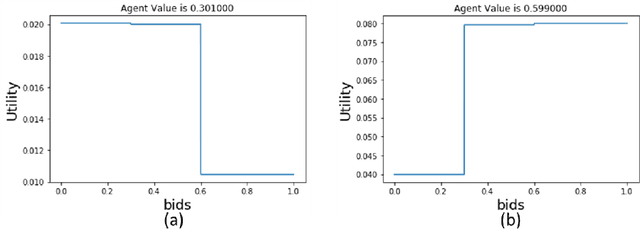
Efficient learning in multi-armed bandit mechanisms such as pay-per-click (PPC) auctions typically involves three challenges: 1) inducing truthful bidding behavior (incentives), 2) using personalization in the users (context), and 3) circumventing manipulations in click patterns (corruptions). Each of these challenges has been studied orthogonally in the literature; incentives have been addressed by a line of work on truthful multi-armed bandit mechanisms, context has been extensively tackled by contextual bandit algorithms, while corruptions have been discussed via a recent line of work on bandits with adversarial corruptions. Since these challenges co-exist, it is important to understand the robustness of each of these approaches in addressing the other challenges, provide algorithms that can handle all simultaneously, and highlight inherent limitations in this combination. In this work, we show that the most prominent contextual bandit algorithm, $\epsilon$-greedy can be extended to handle the challenges introduced by strategic arms in the contextual multi-arm bandit mechanism setting. We further show that $\epsilon$-greedy is inherently robust to adversarial data corruption attacks and achieves performance that degrades linearly with the amount of corruption.
Black-Box Targeted Reward Poisoning Attack Against Online Deep Reinforcement Learning
May 18, 2023

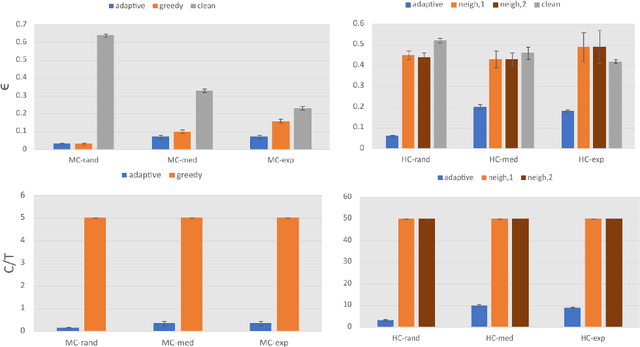

We propose the first black-box targeted attack against online deep reinforcement learning through reward poisoning during training time. Our attack is applicable to general environments with unknown dynamics learned by unknown algorithms and requires limited attack budgets and computational resources. We leverage a general framework and find conditions to ensure efficient attack under a general assumption of the learning algorithms. We show that our attack is optimal in our framework under the conditions. We experimentally verify that with limited budgets, our attack efficiently leads the learning agent to various target policies under a diverse set of popular DRL environments and state-of-the-art learners.
Efficient Reward Poisoning Attacks on Online Deep Reinforcement Learning
May 30, 2022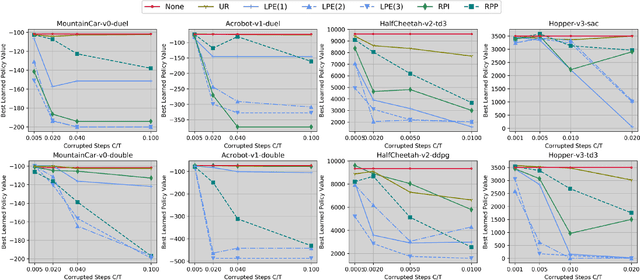
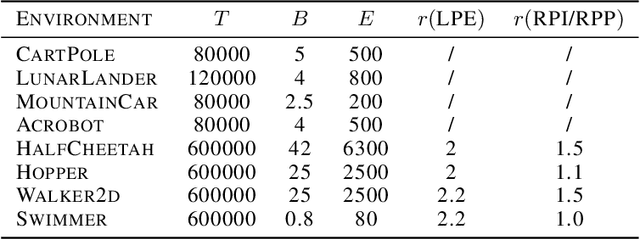
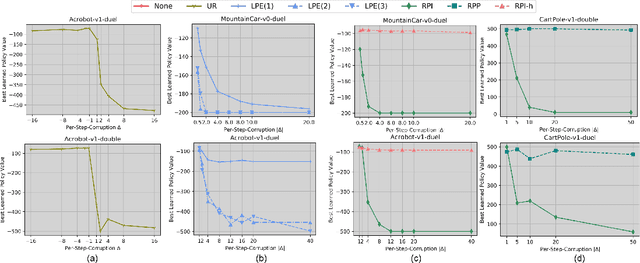
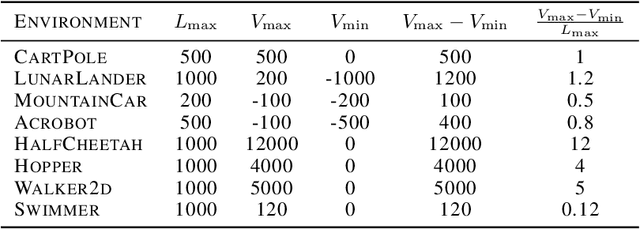
We study data poisoning attacks on online deep reinforcement learning (DRL) where the attacker is oblivious to the learning algorithm used by the agent and does not necessarily have full knowledge of the environment. We demonstrate the intrinsic vulnerability of state-of-the-art DRL algorithms by designing a general reward poisoning framework called adversarial MDP attacks. We instantiate our framework to construct several new attacks which only corrupt the rewards for a small fraction of the total training timesteps and make the agent learn a low-performing policy. Our key insight is that the state-of-the-art DRL algorithms strategically explore the environment to find a high-performing policy. Our attacks leverage this insight to construct a corrupted environment for misleading the agent towards learning low-performing policies with a limited attack budget. We provide a theoretical analysis of the efficiency of our attack and perform an extensive evaluation. Our results show that our attacks efficiently poison agents learning with a variety of state-of-the-art DRL algorithms, such as DQN, PPO, SAC, etc. under several popular classical control and MuJoCo environments.