 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Reward Poisoning Attacks on Online Deep Reinforcement Learning
Paper and Code
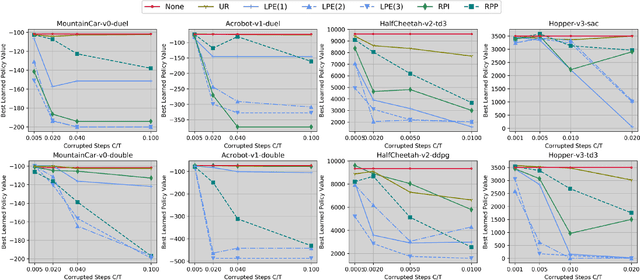
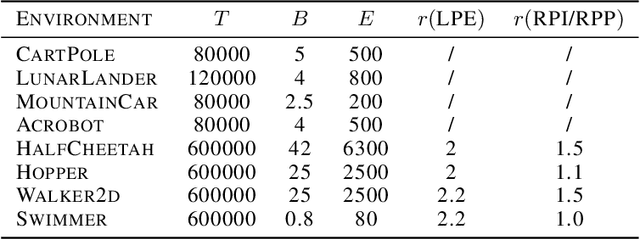
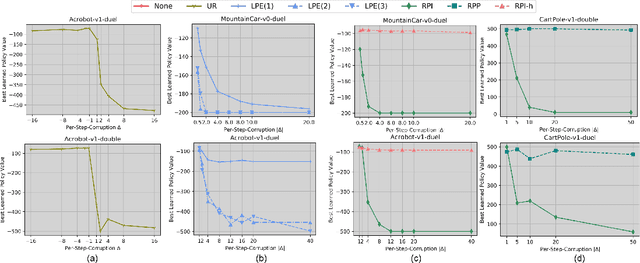
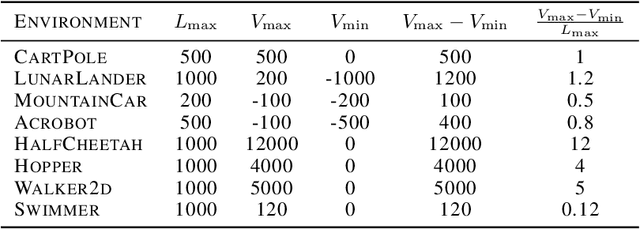
We study data poisoning attacks on online deep reinforcement learning (DRL) where the attacker is oblivious to the learning algorithm used by the agent and does not necessarily have full knowledge of the environment. We demonstrate the intrinsic vulnerability of state-of-the-art DRL algorithms by designing a general reward poisoning framework called adversarial MDP attacks. We instantiate our framework to construct several new attacks which only corrupt the rewards for a small fraction of the total training timesteps and make the agent learn a low-performing policy. Our key insight is that the state-of-the-art DRL algorithms strategically explore the environment to find a high-performing policy. Our attacks leverage this insight to construct a corrupted environment for misleading the agent towards learning low-performing policies with a limited attack budget. We provide a theoretical analysis of the efficiency of our attack and perform an extensive evaluation. Our results show that our attacks efficiently poison agents learning with a variety of state-of-the-art DRL algorithms, such as DQN, PPO, SAC, etc. under several popular classical control and MuJoCo environments.