 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosterior Optimization with Clipped Objective for Bridging Efficiency and Stability in Generative Policy Learning
Apr 02, 2026Expressive generative models have advanced robotic manipulation by capturing complex, multi-modal action distributions over temporally extended trajectories. However, fine-tuning these policies via RL remains challenging due to instability and sample inefficiency. We introduce Posterior Optimization with Clipped Objective (POCO), a principled RL framework that formulates policy improvement as a posterior inference problem tailored for temporal action chunks. Through an Expectation-Maximization procedure, POCO distills a reward-weighted implicit posterior into the policy without likelihood estimation. Furthermore, POCO adopts an offline-to-online paradigm that anchors online exploration to pre-trained priors, and its model-agnostic design scales to fine-tune large VLA models without architectural modifications. Evaluations across 7 simulation benchmarks and 4 contact-rich real-world tasks demonstrate that POCO prevents catastrophic policy collapse, outperforms SOTA baselines, and achieves a 96.7% success rate on real-world tasks. Videos are available at our project website https://cccedric.github.io/poco/.
Inference-Time Scaling of Verification: Self-Evolving Deep Research Agents via Test-Time Rubric-Guided Verification
Jan 22, 2026Recent advances in Deep Research Agents (DRAs) are transforming automated knowledge discovery and problem-solving. While the majority of existing efforts focus on enhancing policy capabilities via post-training, we propose an alternative paradigm: self-evolving the agent's ability by iteratively verifying the policy model's outputs, guided by meticulously crafted rubrics. This approach gives rise to the inference-time scaling of verification, wherein an agent self-improves by evaluating its generated answers to produce iterative feedback and refinements. We derive the rubrics based on an automatically constructed DRA Failure Taxonomy, which systematically classifies agent failures into five major categories and thirteen sub-categories. We present DeepVerifier, a rubrics-based outcome reward verifier that leverages the asymmetry of verification and outperforms vanilla agent-as-judge and LLM judge baselines by 12%-48% in meta-evaluation F1 score. To enable practical self-evolution, DeepVerifier integrates as a plug-and-play module during test-time inference. The verifier produces detailed rubric-based feedback, which is fed back to the agent for iterative bootstrapping, refining responses without additional training. This test-time scaling delivers 8%-11% accuracy gains on challenging subsets of GAIA and XBench-DeepResearch when powered by capable closed-source LLMs. Finally, to support open-source advancement, we release DeepVerifier-4K, a curated supervised fine-tuning dataset of 4,646 high-quality agent steps focused on DRA verification. These examples emphasize reflection and self-critique, enabling open models to develop robust verification capabilities.
ScreenCoder: Advancing Visual-to-Code Generation for Front-End Automation via Modular Multimodal Agents
Jul 30, 2025Automating the transformation of user interface (UI) designs into front-end code holds significant promise for accelerating software development and democratizing design workflows. While recent large language models (LLMs) have demonstrated progress in text-to-code generation, many existing approaches rely solely on natural language prompts, limiting their effectiveness in capturing spatial layout and visual design intent. In contrast, UI development in practice is inherently multimodal, often starting from visual sketches or mockups. To address this gap, we introduce a modular multi-agent framework that performs UI-to-code generation in three interpretable stages: grounding, planning, and generation. The grounding agent uses a vision-language model to detect and label UI components, the planning agent constructs a hierarchical layout using front-end engineering priors, and the generation agent produces HTML/CSS code via adaptive prompt-based synthesis. This design improves robustness, interpretability, and fidelity over end-to-end black-box methods. Furthermore, we extend the framework into a scalable data engine that automatically produces large-scale image-code pairs. Using these synthetic examples, we fine-tune and reinforce an open-source VLM, yielding notable gains in UI understanding and code quality. Extensive experiments demonstrate that our approach achieves state-of-the-art performance in layout accuracy, structural coherence, and code correctness. Our code is made publicly available at https://github.com/leigest519/ScreenCoder.
DesignBench: A Comprehensive Benchmark for MLLM-based Front-end Code Generation
Jun 06, 2025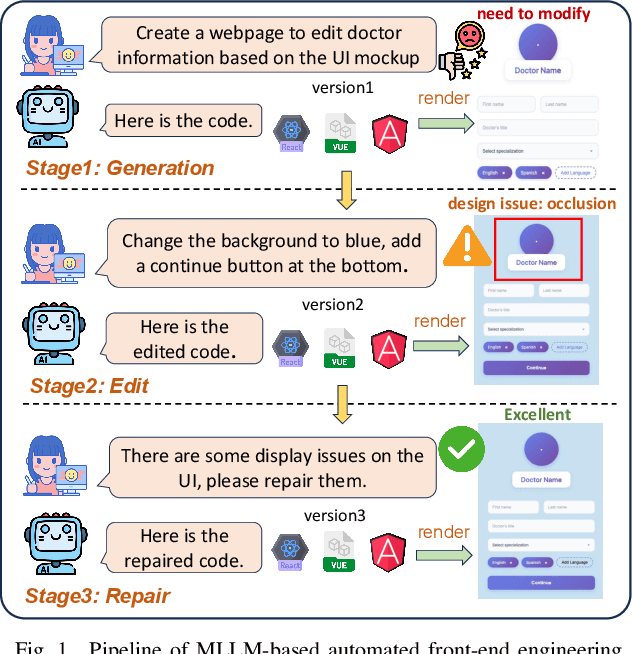
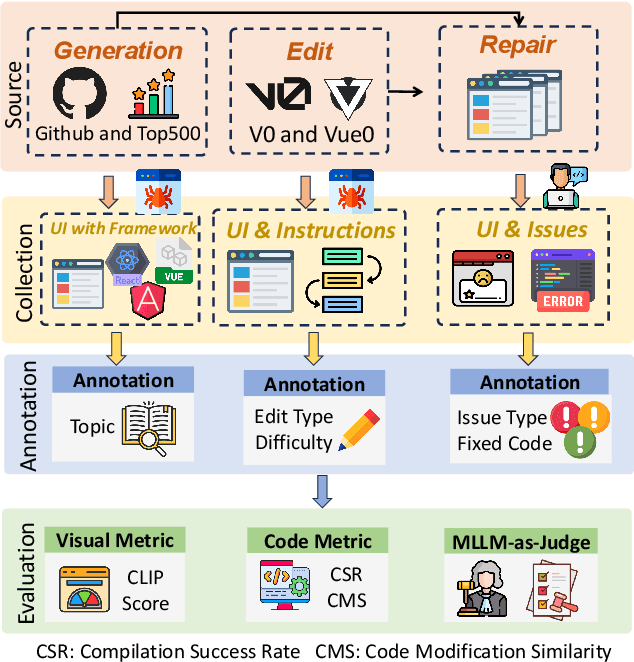

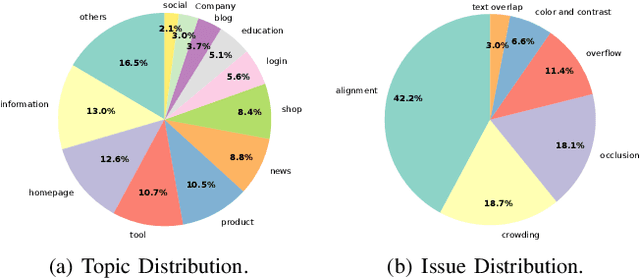
Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities in automated front-end engineering, e.g., generating UI code from visual designs. However, existing front-end UI code generation benchmarks have the following limitations: (1) While framework-based development becomes predominant in modern front-end programming, current benchmarks fail to incorporate mainstream development frameworks. (2) Existing evaluations focus solely on the UI code generation task, whereas practical UI development involves several iterations, including refining editing, and repairing issues. (3) Current benchmarks employ unidimensional evaluation, lacking investigation into influencing factors like task difficulty, input context variations, and in-depth code-level analysis. To bridge these gaps, we introduce DesignBench, a multi-framework, multi-task evaluation benchmark for assessing MLLMs' capabilities in automated front-end engineering. DesignBench encompasses three widely-used UI frameworks (React, Vue, and Angular) alongside vanilla HTML/CSS, and evaluates on three essential front-end tasks (generation, edit, and repair) in real-world development workflows. DesignBench contains 900 webpage samples spanning over 11 topics, 9 edit types, and 6 issue categories, enabling detailed analysis of MLLM performance across multiple dimensions. Our systematic evaluation reveals critical insights into MLLMs' framework-specific limitations, task-related bottlenecks, and performance variations under different conditions, providing guidance for future research in automated front-end development. Our code and data are available at https://github.com/WebPAI/DesignBench.
Learning a Pessimistic Reward Model in RLHF
May 26, 2025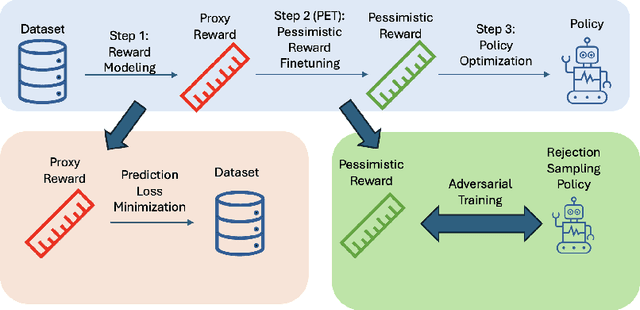


This work proposes `PET', a novel pessimistic reward fine-tuning method, to learn a pessimistic reward model robust against reward hacking in offline reinforcement learning from human feedback (RLHF). Traditional reward modeling techniques in RLHF train an imperfect reward model, on which a KL regularization plays a pivotal role in mitigating reward hacking when optimizing a policy. Such an intuition-based method still suffers from reward hacking, and the policies with large KL divergence from the dataset distribution are excluded during learning. In contrast, we show that when optimizing a policy on a pessimistic reward model fine-tuned through PET, reward hacking can be prevented without relying on any regularization. We test our methods on the standard TL;DR summarization dataset. We find that one can learn a high-quality policy on our pessimistic reward without using any regularization. Such a policy has a high KL divergence from the dataset distribution while having high performance in practice. In summary, our work shows the feasibility of learning a pessimistic reward model against reward hacking. The agent can greedily search for the policy with a high pessimistic reward without suffering from reward hacking.
Towards Scalable Foundation Model for Multi-modal and Hyperspectral Geospatial Data
Mar 17, 2025



Geospatial raster (imagery) data, such as that collected by satellite-based imaging systems at different times and spectral bands, hold immense potential for enabling a wide range of high-impact applications. This potential stems from the rich information that is spatially and temporally contextualized across multiple channels and sensing modalities. Recent work has adapted existing self-supervised learning approaches for such geospatial data. However, they fall short of scalable model architectures, leading to inflexibility and computational inefficiencies when faced with an increasing number of channels and modalities. To address these limitations, we introduce Low-rank Efficient Spatial-Spectral Vision Transformer (LESS ViT) with three key innovations: i) the LESS Attention Block that approximates high-dimensional spatial-spectral attention through Kronecker's product of the low-dimensional spatial and spectral attention components; ii) the Continuous Positional-Channel Embedding Layer that preserves both spatial and spectral continuity and physical characteristics of each patch; and iii) the Perception Field Mask that exploits local spatial dependencies by constraining attention to neighboring patches. To evaluate the proposed innovations, we construct a benchmark, GFM-Bench, which serves as a comprehensive benchmark for such geospatial raster data. We pretrain LESS ViT using a Hyperspectral Masked Autoencoder framework with integrated positional and channel masking strategies. Experimental results demonstrate that our proposed method surpasses current state-of-the-art multi-modal geospatial foundation models, achieving superior performance with less computation and fewer parameters. The flexibility and extensibility of our framework make it a promising direction for future geospatial data analysis tasks that involve a wide range of modalities and channels.
FetchBot: Object Fetching in Cluttered Shelves via Zero-Shot Sim2Real
Feb 25, 2025

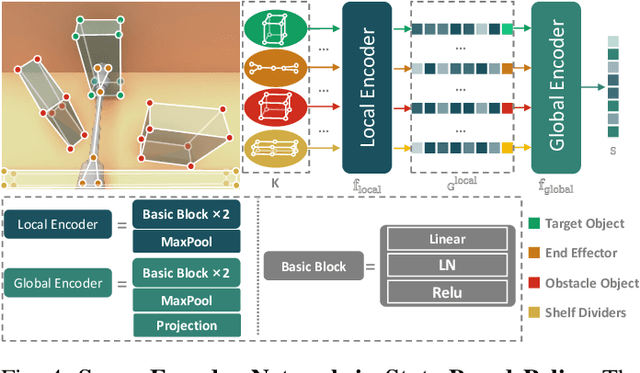
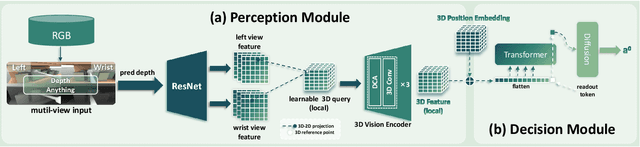
Object fetching from cluttered shelves is an important capability for robots to assist humans in real-world scenarios. Achieving this task demands robotic behaviors that prioritize safety by minimizing disturbances to surrounding objects, an essential but highly challenging requirement due to restricted motion space, limited fields of view, and complex object dynamics. In this paper, we introduce FetchBot, a sim-to-real framework designed to enable zero-shot generalizable and safety-aware object fetching from cluttered shelves in real-world settings. To address data scarcity, we propose an efficient voxel-based method for generating diverse simulated cluttered shelf scenes at scale and train a dynamics-aware reinforcement learning (RL) policy to generate object fetching trajectories within these scenes. This RL policy, which leverages oracle information, is subsequently distilled into a vision-based policy for real-world deployment. Considering that sim-to-real discrepancies stem from texture variations mostly while from geometric dimensions rarely, we propose to adopt depth information estimated by full-fledged depth foundation models as the input for the vision-based policy to mitigate sim-to-real gap. To tackle the challenge of limited views, we design a novel architecture for learning multi-view representations, allowing for comprehensive encoding of cluttered shelf scenes. This enables FetchBot to effectively minimize collisions while fetching objects from varying positions and depths, ensuring robust and safety-aware operation. Both simulation and real-robot experiments demonstrate FetchBot's superior generalization ability, particularly in handling a broad range of real-world scenarios, includ
MRWeb: An Exploration of Generating Multi-Page Resource-Aware Web Code from UI Designs
Dec 19, 2024Multi-page websites dominate modern web development. However, existing design-to-code methods rely on simplified assumptions, limiting to single-page, self-contained webpages without external resource connection. To address this gap, we introduce the Multi-Page Resource-Aware Webpage (MRWeb) generation task, which transforms UI designs into multi-page, functional web UIs with internal/external navigation, image loading, and backend routing. We propose a novel resource list data structure to track resources, links, and design components. Our study applies existing methods to the MRWeb problem using a newly curated dataset of 500 websites (300 synthetic, 200 real-world). Specifically, we identify the best metric to evaluate the similarity of the web UI, assess the impact of the resource list on MRWeb generation, analyze MLLM limitations, and evaluate the effectiveness of the MRWeb tool in real-world workflows. The results show that resource lists boost navigation functionality from 0% to 66%-80% while facilitating visual similarity. Our proposed metrics and evaluation framework provide new insights into MLLM performance on MRWeb tasks. We release the MRWeb tool, dataset, and evaluation framework to promote further research.
Interaction2Code: How Far Are We From Automatic Interactive Webpage Generation?
Nov 05, 2024



Converting webpage design into functional UI code is a critical step for building websites, which can be labor-intensive and time-consuming. To automate this design-to-code transformation process, various automated methods using learning-based networks and multi-modal large language models (MLLMs) have been proposed. However, these studies were merely evaluated on a narrow range of static web pages and ignored dynamic interaction elements, making them less practical for real-world website deployment. To fill in the blank, we present the first systematic investigation of MLLMs in generating interactive webpages. Specifically, we first formulate the Interaction-to-Code task and build the Interaction2Code benchmark that contains 97 unique web pages and 213 distinct interactions, spanning 15 webpage types and 30 interaction categories. We then conduct comprehensive experiments on three state-of-the-art (SOTA) MLLMs using both automatic metrics and human evaluations, thereby summarizing six findings accordingly. Our experimental results highlight the limitations of MLLMs in generating fine-grained interactive features and managing interactions with complex transformations and subtle visual modifications. We further analyze failure cases and their underlying causes, identifying 10 common failure types and assessing their severity. Additionally, our findings reveal three critical influencing factors, i.e., prompts, visual saliency, and textual descriptions, that can enhance the interaction generation performance of MLLMs. Based on these findings, we elicit implications for researchers and developers, providing a foundation for future advancements in this field. Datasets and source code are available at https://github.com/WebPAI/Interaction2Code.
Automatically Generating UI Code from Screenshot: A Divide-and-Conquer-Based Approach
Jun 24, 2024



Websites are critical in today's digital world, with over 1.11 billion currently active and approximately 252,000 new sites launched daily. Converting website layout design into functional UI code is a time-consuming yet indispensable step of website development. Manual methods of converting visual designs into functional code present significant challenges, especially for non-experts. To explore automatic design-to-code solutions, we first conduct a motivating study on GPT-4o and identify three types of issues in generating UI code: element omission, element distortion, and element misarrangement. We further reveal that a focus on smaller visual segments can help multimodal large language models (MLLMs) mitigate these failures in the generation process. In this paper, we propose DCGen, a divide-and-conquer-based approach to automate the translation of webpage design to UI code. DCGen starts by dividing screenshots into manageable segments, generating descriptions for each segment, and then reassembling them into complete UI code for the entire screenshot. We conduct extensive testing with a dataset comprised of real-world websites and various MLLMs and demonstrate that DCGen achieves up to a 14% improvement in visual similarity over competing methods. To the best of our knowledge, DCGen is the first segment-aware prompt-based approach for generating UI code directly from screenshots.