 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLESSViT: Robust Hyperspectral Representation Learning under Spectral Configuration Shift
May 18, 2026Modeling hyperspectral imagery (HSI) across different sensors presents a fundamental challenge due to variations in wavelength coverage, band sampling, and channel dimensionality. As a result, models trained under a fixed spectral configuration often fail to generalize to other sensors. Existing Vision Transformer (ViT) approaches either rely on implicit spectral modeling with fixed channel assumptions or adopt explicit spatial-spectral attention with prohibitive computational cost, leading to a fundamental trade-off between efficiency and expressiveness. In this work, we introduce Low-rank Efficient Spatial-Spectral ViT (LESSViT), a sensor-flexible architecture for cross-spectral generalization. LESSViT is built on LESS Attention, a structured low-rank factorization that models joint spatial-spectral interactions through separable spatial and spectral components, reducing the complexity of full spatial-spectral attention from $O(N^2 C^2)$ to $O(rNC)$, where $N$ is the number of spatial tokens, $C$ is the number of spectral channels, and $r$ is the rank of the low-rank approximation. We further incorporate channel-agnostic patch embedding and wavelength-aware positional encoding to support flexible spectral inputs. To enable efficient and robust pretraining, we introduce a hyperspectral masked autoencoder (HyperMAE) with decoupled spatial-spectral masking and hierarchical channel sampling. We evaluate LESSViT under a cross-spectral generalization setting that simulates cross-sensor variability. Experiments on the SpectralEarth benchmark demonstrate that LESSViT improves robustness under spectral shifts while remaining competitive in-distribution, and explicit and efficient spatial-spectral modeling is essential for scalable and generalizable hyperspectral representation learning.
Moment Alignment: Unifying Gradient and Hessian Matching for Domain Generalization
Jun 09, 2025Domain generalization (DG) seeks to develop models that generalize well to unseen target domains, addressing the prevalent issue of distribution shifts in real-world applications. One line of research in DG focuses on aligning domain-level gradients and Hessians to enhance generalization. However, existing methods are computationally inefficient and the underlying principles of these approaches are not well understood. In this paper, we develop the theory of moment alignment for DG. Grounded in \textit{transfer measure}, a principled framework for quantifying generalizability between two domains, we first extend the definition of transfer measure to domain generalization that includes multiple source domains and establish a target error bound. Then, we prove that aligning derivatives across domains improves transfer measure both when the feature extractor induces an invariant optimal predictor across domains and when it does not. Notably, moment alignment provides a unifying understanding of Invariant Risk Minimization, gradient matching, and Hessian matching, three previously disconnected approaches to DG. We further connect feature moments and derivatives of the classifier head, and establish the duality between feature learning and classifier fitting. Building upon our theory, we introduce \textbf{C}losed-Form \textbf{M}oment \textbf{A}lignment (CMA), a novel DG algorithm that aligns domain-level gradients and Hessians in closed-form. Our method overcomes the computational inefficiencies of existing gradient and Hessian-based techniques by eliminating the need for repeated backpropagation or sampling-based Hessian estimation. We validate the efficacy of our approach through two sets of experiments: linear probing and full fine-tuning. CMA demonstrates superior performance in both settings compared to Empirical Risk Minimization and state-of-the-art algorithms.
Towards Scalable Foundation Model for Multi-modal and Hyperspectral Geospatial Data
Mar 17, 2025



Geospatial raster (imagery) data, such as that collected by satellite-based imaging systems at different times and spectral bands, hold immense potential for enabling a wide range of high-impact applications. This potential stems from the rich information that is spatially and temporally contextualized across multiple channels and sensing modalities. Recent work has adapted existing self-supervised learning approaches for such geospatial data. However, they fall short of scalable model architectures, leading to inflexibility and computational inefficiencies when faced with an increasing number of channels and modalities. To address these limitations, we introduce Low-rank Efficient Spatial-Spectral Vision Transformer (LESS ViT) with three key innovations: i) the LESS Attention Block that approximates high-dimensional spatial-spectral attention through Kronecker's product of the low-dimensional spatial and spectral attention components; ii) the Continuous Positional-Channel Embedding Layer that preserves both spatial and spectral continuity and physical characteristics of each patch; and iii) the Perception Field Mask that exploits local spatial dependencies by constraining attention to neighboring patches. To evaluate the proposed innovations, we construct a benchmark, GFM-Bench, which serves as a comprehensive benchmark for such geospatial raster data. We pretrain LESS ViT using a Hyperspectral Masked Autoencoder framework with integrated positional and channel masking strategies. Experimental results demonstrate that our proposed method surpasses current state-of-the-art multi-modal geospatial foundation models, achieving superior performance with less computation and fewer parameters. The flexibility and extensibility of our framework make it a promising direction for future geospatial data analysis tasks that involve a wide range of modalities and channels.
Enhancing Compositional Generalization via Compositional Feature Alignment
Feb 05, 2024Real-world applications of machine learning models often confront data distribution shifts, wherein discrepancies exist between the training and test data distributions. In the common multi-domain multi-class setup, as the number of classes and domains scales up, it becomes infeasible to gather training data for every domain-class combination. This challenge naturally leads the quest for models with Compositional Generalization (CG) ability, where models can generalize to unseen domain-class combinations. To delve into the CG challenge, we develop CG-Bench, a suite of CG benchmarks derived from existing real-world image datasets, and observe that the prevalent pretraining-finetuning paradigm on foundational models, such as CLIP and DINOv2, struggles with the challenge. To address this challenge, we propose Compositional Feature Alignment (CFA), a simple two-stage finetuning technique that i) learns two orthogonal linear heads on a pretrained encoder with respect to class and domain labels, and ii) fine-tunes the encoder with the newly learned head frozen. We theoretically and empirically justify that CFA encourages compositional feature learning of pretrained models. We further conduct extensive experiments on CG-Bench for CLIP and DINOv2, two powerful pretrained vision foundation models. Experiment results show that CFA outperforms common finetuning techniques in compositional generalization, corroborating CFA's efficacy in compositional feature learning.
Invariant-Feature Subspace Recovery: A New Class of Provable Domain Generalization Algorithms
Nov 02, 2023



Domain generalization asks for models trained over a set of training environments to generalize well in unseen test environments. Recently, a series of algorithms such as Invariant Risk Minimization (IRM) have been proposed for domain generalization. However, Rosenfeld et al. (2021) shows that in a simple linear data model, even if non-convexity issues are ignored, IRM and its extensions cannot generalize to unseen environments with less than $d_s+1$ training environments, where $d_s$ is the dimension of the spurious-feature subspace. In this work, we propose Invariant-feature Subspace Recovery (ISR): a new class of algorithms to achieve provable domain generalization across the settings of classification and regression problems. First, in the binary classification setup of Rosenfeld et al. (2021), we show that our first algorithm, ISR-Mean, can identify the subspace spanned by invariant features from the first-order moments of the class-conditional distributions, and achieve provable domain generalization with $d_s+1$ training environments. Our second algorithm, ISR-Cov, further reduces the required number of training environments to $O(1)$ using the information of second-order moments. Notably, unlike IRM, our algorithms bypass non-convexity issues and enjoy global convergence guarantees. Next, we extend ISR-Mean to the more general setting of multi-class classification and propose ISR-Multiclass, which leverages class information and provably recovers the invariant-feature subspace with $\lceil d_s/k\rceil+1$ training environments for $k$-class classification. Finally, for regression problems, we propose ISR-Regression that can identify the invariant-feature subspace with $d_s+1$ training environments. Empirically, we demonstrate the superior performance of our ISRs on synthetic benchmarks. Further, ISR can be used as post-processing methods for feature extractors such as neural nets.
Fully Self-Supervised Depth Estimation from Defocus Clue
Mar 27, 2023
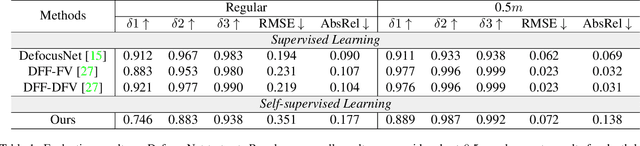
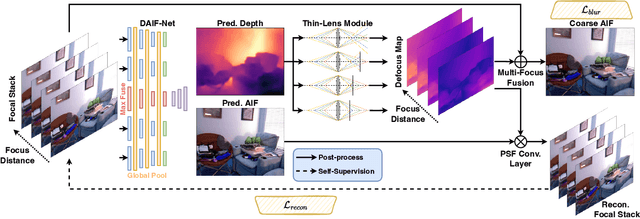
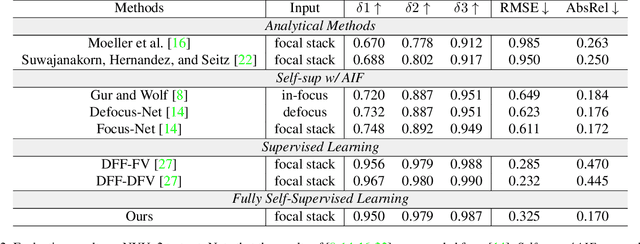
Depth-from-defocus (DFD), modeling the relationship between depth and defocus pattern in images, has demonstrated promising performance in depth estimation. Recently, several self-supervised works try to overcome the difficulties in acquiring accurate depth ground-truth. However, they depend on the all-in-focus (AIF) images, which cannot be captured in real-world scenarios. Such limitation discourages the applications of DFD methods. To tackle this issue, we propose a completely self-supervised framework that estimates depth purely from a sparse focal stack. We show that our framework circumvents the needs for the depth and AIF image ground-truth, and receives superior predictions, thus closing the gap between the theoretical success of DFD works and their applications in the real world. In particular, we propose (i) a more realistic setting for DFD tasks, where no depth or AIF image ground-truth is available; (ii) a novel self-supervision framework that provides reliable predictions of depth and AIF image under the challenging setting. The proposed framework uses a neural model to predict the depth and AIF image, and utilizes an optical model to validate and refine the prediction. We verify our framework on three benchmark datasets with rendered focal stacks and real focal stacks. Qualitative and quantitative evaluations show that our method provides a strong baseline for self-supervised DFD tasks.
Provable Domain Generalization via Invariant-Feature Subspace Recovery
Jan 30, 2022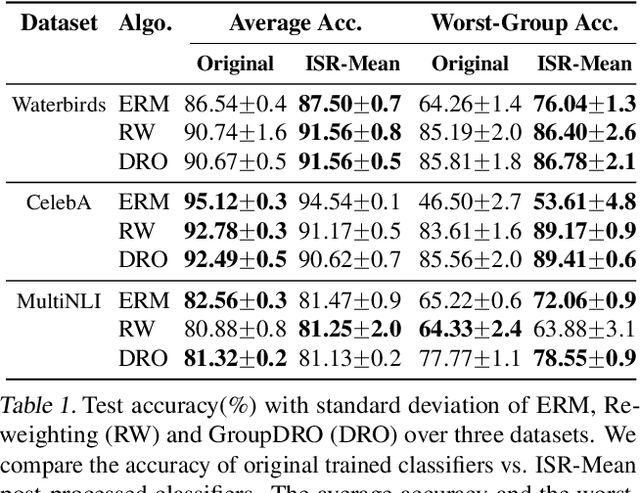
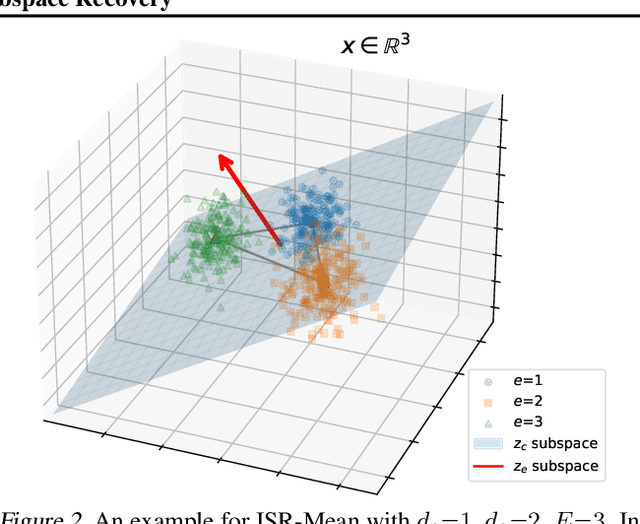
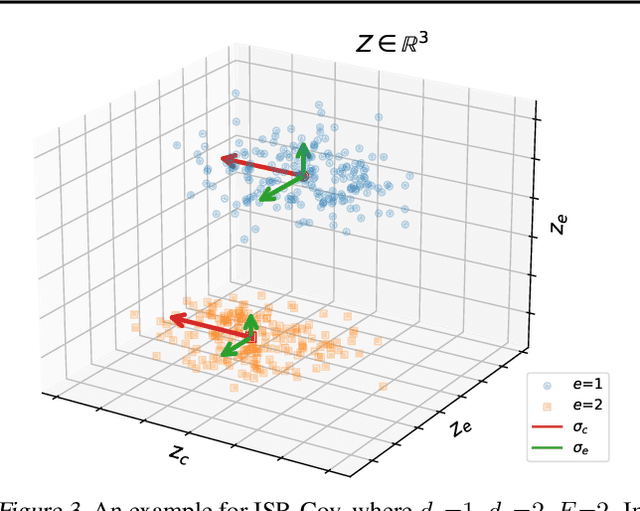
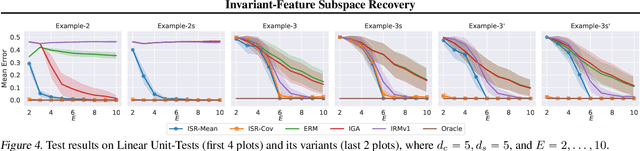
Domain generalization asks for models trained on a set of training environments to perform well on unseen test environments. Recently, a series of algorithms such as Invariant Risk Minimization (IRM) has been proposed for domain generalization. However, Rosenfeld et al. (2021) shows that in a simple linear data model, even if non-convexity issues are ignored, IRM and its extensions cannot generalize to unseen environments with less than $d_s+1$ training environments, where $d_s$ is the dimension of the spurious-feature subspace. In this paper, we propose to achieve domain generalization with Invariant-feature Subspace Recovery (ISR). Our first algorithm, ISR-Mean, can identify the subspace spanned by invariant features from the first-order moments of the class-conditional distributions, and achieve provable domain generalization with $d_s+1$ training environments under the data model of Rosenfeld et al. (2021). Our second algorithm, ISR-Cov, further reduces the required number of training environments to $O(1)$ using the information of second-order moments. Notably, unlike IRM, our algorithms bypass non-convexity issues and enjoy global convergence guarantees. Empirically, our ISRs can obtain superior performance compared with IRM on synthetic benchmarks. In addition, on three real-world image and text datasets, we show that ISR-Mean can be used as a simple yet effective post-processing method to increase the worst-case accuracy of trained models against spurious correlations and group shifts.