 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaperMentor: A Human-Centered Multi-Agent Writing Tutor for AI Research Papers on Overleaf
Jun 07, 2026Expert writing feedback from experienced researchers is critical for early-career scholars to improve their manuscripts, yet high-quality feedback often remains scarce because reviewing research papers is labor-intensive. Emerging AI-powered writing assistants largely focus on grammar fixes or simulating peer review with final scores, yet they fall short of providing concrete, actionable suggestions that help students improve their papers during drafting. We present PaperMentor, a human-centered writing assistant system that delivers actionable suggestions as Overleaf-native inline comments while leaving the actual writing entirely to human authors. PaperMentor integrates an expert skill library carefully curated from established researchers' writing advice with 12 specialized agents covering different aspects of paper writing, such as formatting compliance, phrasing accuracy, and terminology consistency. In a user study (n=14), 90.6% of the generated comments were rated actionable and 67.5% were rated valid, significantly outperforming a GPT-5.2 baseline uswithout the skill library. We release PaperMentor as open source for public use. Our code is publicly available under the AGPL-3.0 license at https://github.com/jiarui-liu/overleaf
CausaLab: A Scalable Environment for Interactive Causal Discovery Toward AI Scientists
May 28, 2026We introduce CausaLab, a scalable environment for evaluating interactive causal discovery by LLM agents. Unlike prior evaluations, CausaLab evaluates both whether an agent can solve a problem using causal evidence and whether its answer is grounded in a faithful recovered causal mechanism. Each episode places an agent in a synthetic laboratory: it receives prior measurement records, intervenes on a manipulator crystal, and predicts the resonance frequency of a held-out reactor crystal governed by the same mechanism. The hidden data-generating process is a randomly sampled structural causal model (SCM), so success requires recovering both a causal graph and structural equations rather than recalling prior knowledge. Experiments show a persistent gap between prediction and mechanism recovery: in the purely observational 6-node setting, GPT-5.2-high reaches 92% task accuracy but only 0.471 all-edge $F_1$. Mixed observation-intervention strategies improve structural fidelity, while pure intervention remains difficult even for strong agents. We identify premature stopping as a major weakness and show that consistency verification mitigates it. CausaLab therefore separates predictive success from causal understanding and exposes current LLM agents' limits as experimental causal reasoners.
CausalDetox: Causal Head Selection and Intervention for Language Model Detoxification
Apr 16, 2026Large language models (LLMs) frequently generate toxic content, posing significant risks for safe deployment. Current mitigation strategies often degrade generation quality or require costly human annotation. We propose CAUSALDETOX, a framework that identifies and intervenes on the specific attention heads causally responsible for toxic generation. Using the Probability of Necessity and Sufficiency (PNS), we isolate a minimal set of heads that are necessary and sufficient for toxicity. We utilize these components via two complementary strategies: (1) Local Inference-Time Intervention, which constructs dynamic, input-specific steering vectors for context-aware detoxification, and (2) PNS-Guided Fine-Tuning, which permanently unlearns toxic representations. We also introduce PARATOX, a novel benchmark of aligned toxic/non-toxic sentence pairs enabling controlled counterfactual evaluation. Experiments on ToxiGen, ImplicitHate, and ParaDetox show that CAUSALDETOX achieves up to 5.34% greater toxicity reduction compared to baselines while preserving linguistic fluency, and offers a 7x speedup in head selection.
DIVEBATCH: Accelerating Model Training Through Gradient-Diversity Aware Batch Size Adaptation
Sep 19, 2025The goal of this paper is to accelerate the training of machine learning models, a critical challenge since the training of large-scale deep neural models can be computationally expensive. Stochastic gradient descent (SGD) and its variants are widely used to train deep neural networks. In contrast to traditional approaches that focus on tuning the learning rate, we propose a novel adaptive batch size SGD algorithm, DiveBatch, that dynamically adjusts the batch size. Adapting the batch size is challenging: using large batch sizes is more efficient due to parallel computation, but small-batch training often converges in fewer epochs and generalizes better. To address this challenge, we introduce a data-driven adaptation based on gradient diversity, enabling DiveBatch to maintain the generalization performance of small-batch training while improving convergence speed and computational efficiency. Gradient diversity has a strong theoretical justification: it emerges from the convergence analysis of SGD. Evaluations of DiveBatch on synthetic and CiFar-10, CiFar-100, and Tiny-ImageNet demonstrate that DiveBatch converges significantly faster than standard SGD and AdaBatch (1.06 -- 5.0x), with a slight trade-off in performance.
Moment Alignment: Unifying Gradient and Hessian Matching for Domain Generalization
Jun 09, 2025Domain generalization (DG) seeks to develop models that generalize well to unseen target domains, addressing the prevalent issue of distribution shifts in real-world applications. One line of research in DG focuses on aligning domain-level gradients and Hessians to enhance generalization. However, existing methods are computationally inefficient and the underlying principles of these approaches are not well understood. In this paper, we develop the theory of moment alignment for DG. Grounded in \textit{transfer measure}, a principled framework for quantifying generalizability between two domains, we first extend the definition of transfer measure to domain generalization that includes multiple source domains and establish a target error bound. Then, we prove that aligning derivatives across domains improves transfer measure both when the feature extractor induces an invariant optimal predictor across domains and when it does not. Notably, moment alignment provides a unifying understanding of Invariant Risk Minimization, gradient matching, and Hessian matching, three previously disconnected approaches to DG. We further connect feature moments and derivatives of the classifier head, and establish the duality between feature learning and classifier fitting. Building upon our theory, we introduce \textbf{C}losed-Form \textbf{M}oment \textbf{A}lignment (CMA), a novel DG algorithm that aligns domain-level gradients and Hessians in closed-form. Our method overcomes the computational inefficiencies of existing gradient and Hessian-based techniques by eliminating the need for repeated backpropagation or sampling-based Hessian estimation. We validate the efficacy of our approach through two sets of experiments: linear probing and full fine-tuning. CMA demonstrates superior performance in both settings compared to Empirical Risk Minimization and state-of-the-art algorithms.
Breaking Bad Tokens: Detoxification of LLMs Using Sparse Autoencoders
May 20, 2025Large language models (LLMs) are now ubiquitous in user-facing applications, yet they still generate undesirable toxic outputs, including profanity, vulgarity, and derogatory remarks. Although numerous detoxification methods exist, most apply broad, surface-level fixes and can therefore easily be circumvented by jailbreak attacks. In this paper we leverage sparse autoencoders (SAEs) to identify toxicity-related directions in the residual stream of models and perform targeted activation steering using the corresponding decoder vectors. We introduce three tiers of steering aggressiveness and evaluate them on GPT-2 Small and Gemma-2-2B, revealing trade-offs between toxicity reduction and language fluency. At stronger steering strengths, these causal interventions surpass competitive baselines in reducing toxicity by up to 20%, though fluency can degrade noticeably on GPT-2 Small depending on the aggressiveness. Crucially, standard NLP benchmark scores upon steering remain stable, indicating that the model's knowledge and general abilities are preserved. We further show that feature-splitting in wider SAEs hampers safety interventions, underscoring the importance of disentangled feature learning. Our findings highlight both the promise and the current limitations of SAE-based causal interventions for LLM detoxification, further suggesting practical guidelines for safer language-model deployment.
Analyzing the Role of Semantic Representations in the Era of Large Language Models
May 02, 2024Traditionally, natural language processing (NLP) models often use a rich set of features created by linguistic expertise, such as semantic representations. However, in the era of large language models (LLMs), more and more tasks are turned into generic, end-to-end sequence generation problems. In this paper, we investigate the question: what is the role of semantic representations in the era of LLMs? Specifically, we investigate the effect of Abstract Meaning Representation (AMR) across five diverse NLP tasks. We propose an AMR-driven chain-of-thought prompting method, which we call AMRCoT, and find that it generally hurts performance more than it helps. To investigate what AMR may have to offer on these tasks, we conduct a series of analysis experiments. We find that it is difficult to predict which input examples AMR may help or hurt on, but errors tend to arise with multi-word expressions, named entities, and in the final inference step where the LLM must connect its reasoning over the AMR to its prediction. We recommend focusing on these areas for future work in semantic representations for LLMs. Our code: https://github.com/causalNLP/amr_llm.
CLadder: A Benchmark to Assess Causal Reasoning Capabilities of Language Models
Dec 07, 2023The ability to perform causal reasoning is widely considered a core feature of intelligence. In this work, we investigate whether large language models (LLMs) can coherently reason about causality. Much of the existing work in natural language processing (NLP) focuses on evaluating commonsense causal reasoning in LLMs, thus failing to assess whether a model can perform causal inference in accordance with a set of well-defined formal rules. To address this, we propose a new NLP task, causal inference in natural language, inspired by the "causal inference engine" postulated by Judea Pearl et al. We compose a large dataset, CLadder, with 10K samples: based on a collection of causal graphs and queries (associational, interventional, and counterfactual), we obtain symbolic questions and ground-truth answers, through an oracle causal inference engine. These are then translated into natural language. We evaluate multiple LLMs on our dataset, and we introduce and evaluate a bespoke chain-of-thought prompting strategy, CausalCoT. We show that our task is highly challenging for LLMs, and we conduct an in-depth analysis to gain deeper insight into the causal reasoning abilities of LLMs. Our data is open-sourced at https://huggingface.co/datasets/causalNLP/cladder, and our code can be found at https://github.com/causalNLP/cladder.
CausalCite: A Causal Formulation of Paper Citations
Nov 05, 2023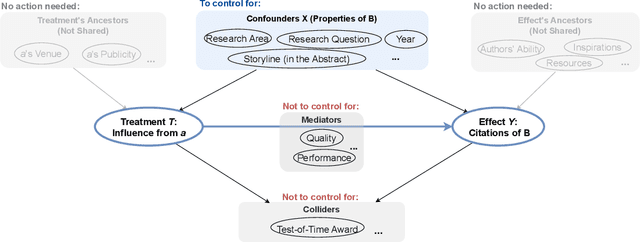


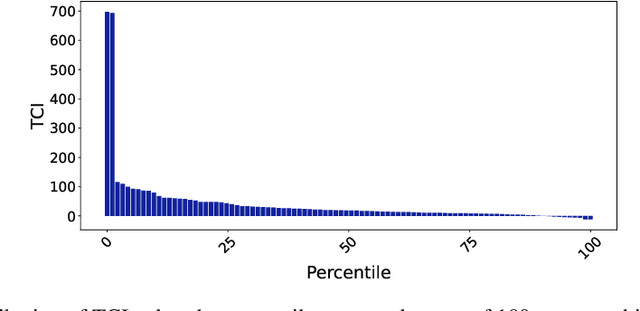
Evaluating the significance of a paper is pivotal yet challenging for the scientific community. While the citation count is the most commonly used proxy for this purpose, they are widely criticized for failing to accurately reflect a paper's true impact. In this work, we propose a causal inference method, TextMatch, which adapts the traditional matching framework to high-dimensional text embeddings. Specifically, we encode each paper using the text embeddings by large language models (LLMs), extract similar samples by cosine similarity, and synthesize a counterfactual sample by the weighted average of similar papers according to their similarity values. We apply the resulting metric, called CausalCite, as a causal formulation of paper citations. We show its effectiveness on various criteria, such as high correlation with paper impact as reported by scientific experts on a previous dataset of 1K papers, (test-of-time) awards for past papers, and its stability across various sub-fields of AI. We also provide a set of findings that can serve as suggested ways for future researchers to use our metric for a better understanding of a paper's quality. Our code and data are at https://github.com/causalNLP/causal-cite.